
[先前的研究团队 Hyunwoo Choi]
5 月,DeepMind 发表了一篇题为“奖励就足够了”的强化学习论文。作者给出了“一只试图增加饱腹感的松鼠”和“一个试图保持清洁的厨房机器人”的例子,如果定义了适当的奖励,与智力相关的各种能力(认知、记忆、计划、运动等)声称能够自然地使用它并做出决定。

人们经常通过各种尝试和错误来学习判断情况并自行做出决定以实现某些目标的能力。由于强化学习本身类似于这些人类学习原则,因此适当的奖励系统将在实现 AGI 中发挥关键作用的说法有一定的道理。然而,虽然可能是因为标题有点挑衅(?),但也有一些持怀疑态度的观点,例如“这是一个没有实质内容的断言”和“在现实生活问题中很难定义明确的奖励” .
XLand:一个新的强化学习环境
事实上,Reward is Enough 可能受到更多攻击,因为它是一个没有包含具体实施结果的声明。仿佛意识到了这种凝视,DeepMind 最近公布了在一个名为 XLand 的新强化学习环境中的实验结果。
目前,人工智能研究正在从一种将预训练模型微调到所需任务的方法,转向使用少量数据确保性能的少样本甚至零样本学习。另一方面,强化学习似乎有一个致命的缺点,即无法利用预先训练的模型来学习新任务,并且总是必须从头开始重新学习。在此背景下,强化学习也可以通过泛化获得的知识来应用于新任务!这是本次演讲的主要结果。显然,如果对一个新任务进行高效学习是可能的,它可以被认为是一种非常接近 AGI 的形式。

为了证明这一点,作者构建了一个能够进行刚体物理模拟的 XLand 引擎,并为训练代理自动创建各种环境和目标。目标可能是让智能体去“靠近紫色立方体”,或者可以给它一个更复杂的目标,例如“靠近紫色立方体或将黄色球体放在红色地板上”。还有一些相互竞争的目标,比如捉迷藏,“看到你的对手,而不是让他们看到你”。
每个智能体在 XLand 的 4,000 个独特世界中玩了大约 700,000 个独特游戏,并在 340 万个独特任务中经历了 2000 亿步学习。结果表明,即使在以前没有训练过的新任务上,只需大约 30 分钟的微调就可以获得显着的性能。另一方面,从头开始训练的模型的性能几乎为零(尽管这是自然结果,因为比较目标已经训练了 2000 亿次)。
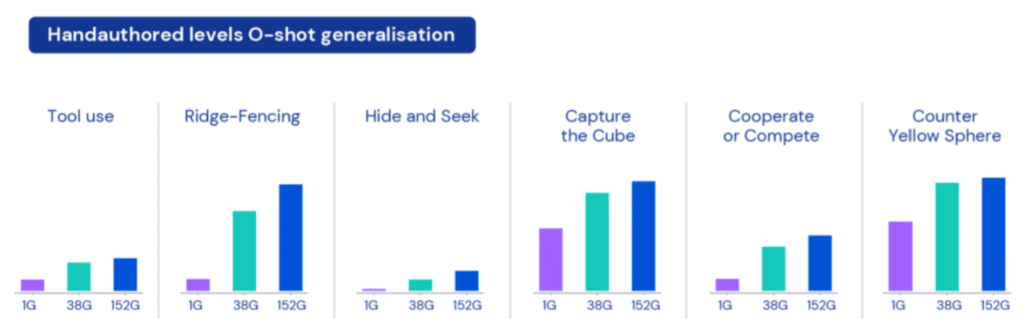
作者认为,代理为解决每个问题而采取的行动可能看起来是偶然的,但仍然是一致的,这表明代理对奖励系统有清晰的了解。
强化学习能否成为 AGI?
如上所述,作者展示了预训练强化学习模型可以快速适应各种新任务的潜力。但是,要突破现有的批评观点,它只是大大简化了现实世界的问题,可能有点困难。
作者还介绍了几个没学好的失败例子,挺有意思的。首先,如果出现了预学习中没有出现的裂缝(陷阱),agent无法假设自己会落入陷阱,从而继续达不到目标。可以通过利用周围物体做一个斜坡来解决上层的问题,但是不能解决连续做多个斜坡的问题(这部分肯定是因为试错维数太大无法解决,限制强化学习的出现。似乎)。另外,如果两个智能体的目标不同,他们可能无法理解另一个智能体的目标,从而无法实现自己的目标。
尽管强化学习是一种模仿人类学习模式的技术,但关于人类如何轻松解决人工智能难以解决的问题,似乎仍有许多令人好奇的部分。即使在代理几乎没有动作选项的模拟环境中,似乎 AGI 的局限性仍然很明显,因为它已经训练了 2000 亿次。
不过,您可能会认为我们已经取得了很大进展,因为我们率先(或许)展示了如何使用灵活的强化学习模型。我很好奇,看看进一步的研究是否可以找到解决失败案例的线索🙂
参考
- https://deepmind.com/research/publications/2021/Reward-is-Enough
- https://deepmind.com/blog/article/generally-capable-agents-emerge-from-open-ended-play






