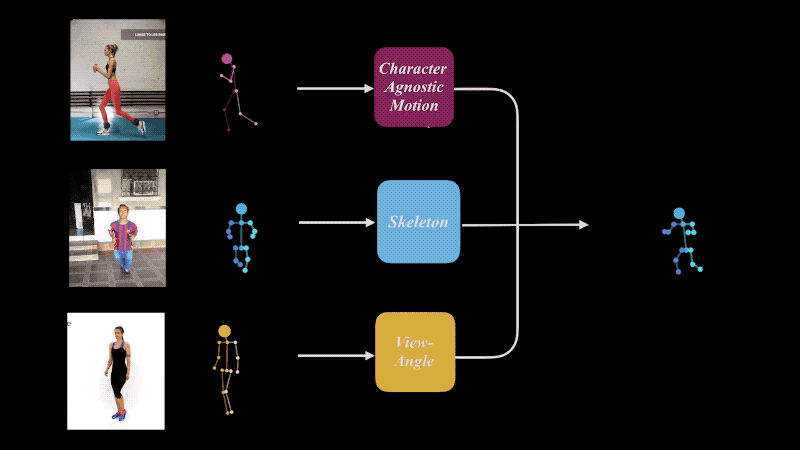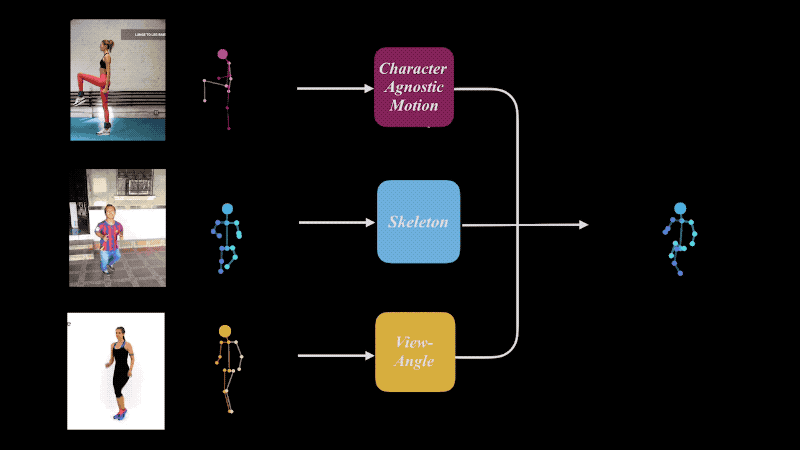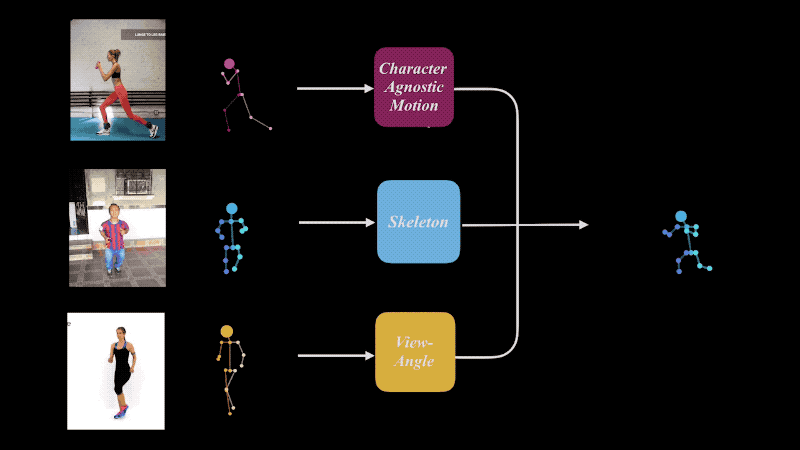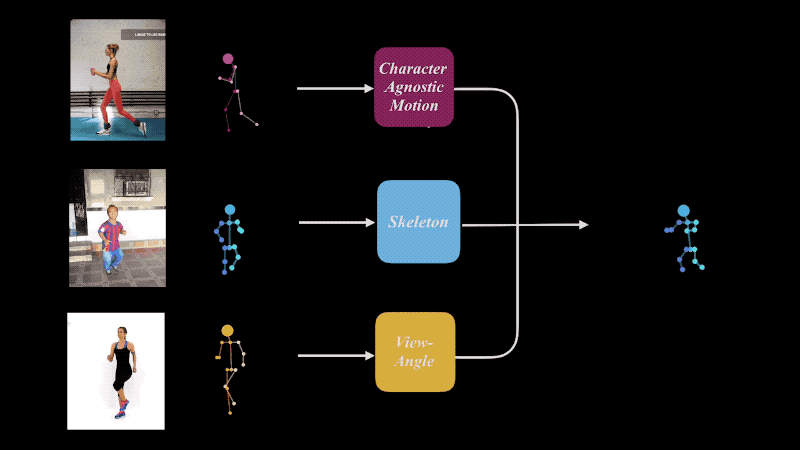
我们共享了在SIGGRAPH 2019上发表的论文``学习面向二维运动重定向的角色不可知运动''的项目页面。
在本文中,我们创建了一个深度学习模型,该模型从三个图像(可能互不相同)中提取运动,骨骼和相机角度,然后将它们组合为一个。可以针对“运动”,“骨骼”和“摄像机角度”进行单个或组合重新定位。 Mixamo被用作训练数据。
作者说,该结果可用于各种领域,例如视频性能克隆以及运动检索。我计划将来将其用于3D或2D角色动画。
我们共享了在SIGGRAPH 2019上发表的论文``学习面向二维运动重定向的角色不可知运动''的项目页面。
在本文中,我们创建了一个深度学习模型,该模型从三个图像(可能互不相同)中提取运动,骨骼和相机角度,然后将它们组合为一个。可以针对“运动”,“骨骼”和“摄像机角度”进行单个或组合重新定位。 Mixamo被用作训练数据。
作者说,该结果可用于各种领域,例如视频性能克隆以及运动检索。我计划将来将其用于3D或2D角色动画。