
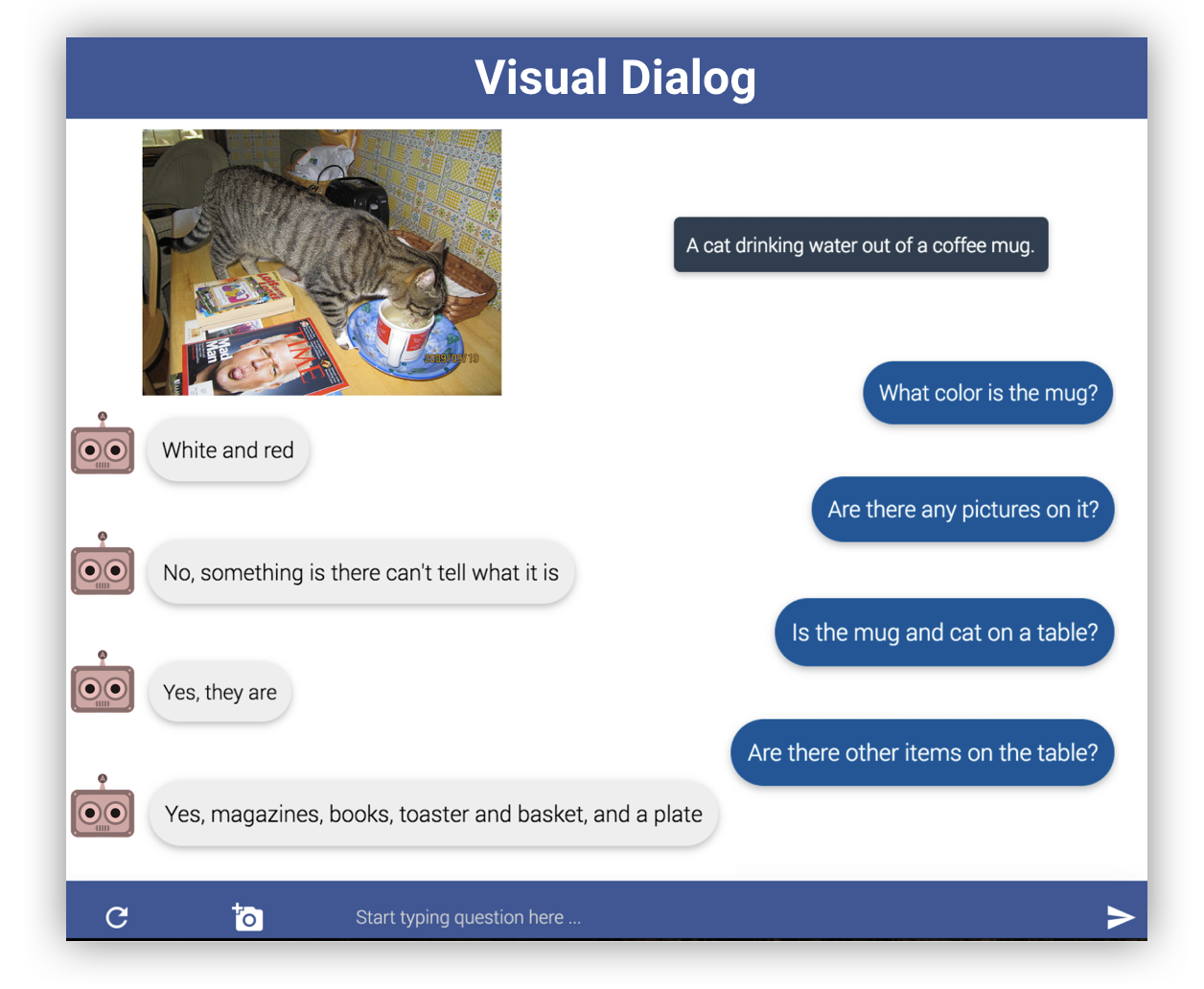
可视对话框任务是一种多模式任务,可将图像添加到由问答组成的Q&A任务中。例如,如果您一起给白猫和黑狗提供图片并询问“猫旁边的动物是什么颜色?”,您回答“黑”。具体来说,它是通过提供图像,对话历史记录和问题来生成答案的任务。如果您转到Visual Dialog网站,则该数据集是公开的,基于v1.0,有120,000张图像和120万个文本句子。 (每个图像1个对话)下面的链接是Visual Dialog站点的数据集页面。
这个网站每年都会面临挑战,下面的视频介绍了使用MReaL-BDAI系统排名第一的团队的技术。基于NDCG(评估指标之一),它获得了非凡的得分,比第二名高出近10分。 (74.57)
但是,如果您阅读了该技术的论文,它不是一个新的模型结构,而是在现有NDCG的59点技术上使用各种(与任务相关的)直观优化技术将其提高到74分。 (我仅通过作为两步学习方法介绍的方法将NDCG提高了10分),并且通过后续论文,将详细描述针对当前定义的可视化对话框任务优化的方法。我尚未阅读所有论文,但我认为有一种针对特定任务或特定指标对其进行优化的趋势。 (例如,在MRR的情况下,第三名团队落后10分或以上)。
改善视觉对话的两个因果原理
本文阐述了我们冠军团队采用的设计技巧
MReaL-BDAI,针对Visual Dialog Challenge 2019:两个因果原则
改进可视对话框(VisDial)。 “改善”是指他们可以
将几乎所有现有的VisDial模型提升为最新性能
在…上
MReaL-BDAI,针对Visual Dialog Challenge 2019:两个因果原则
改进可视对话框(VisDial)。 “改善”是指他们可以
将几乎所有现有的VisDial模型提升为最新性能
在…上
尽管Visual Dialog Task存在一些问题,并且评估指标也与实际性能有所不同,但我认为多模式对话是一个重要的领域,将来可能成为聊天机器人的方向之一。彼此交谈时,我们不仅依赖口头信息,还依赖各种信息,例如视觉,听觉和嗅觉信息。我认为聊天机器人可以阅读我们的表情并与我们交谈,如果我们“看到”和“听着”听到与我们所见相同的内容,则对话的广度将更加广泛。我们期待有一个聊天机器人与我们交谈,同时一起观看和收听BTS的表演。






