图像中常用的卷积是3D操作。 (KxKxC; K =内核大小,C =通道数)通过将其划分为KxKx1的多个2D运算来应用后,深度可分离卷积在通道方向上应用大小为1x1xC的卷积会大大减少参数数量。以这种方式创建的网络结构是Google MobileNet。
在将不同大小的核(例如3×3、5×5和7×7)应用于输入张量之后,Google Inception具有一个基本的串联模块。这种方法的优点还在于基于相同性能的参数数量减少。
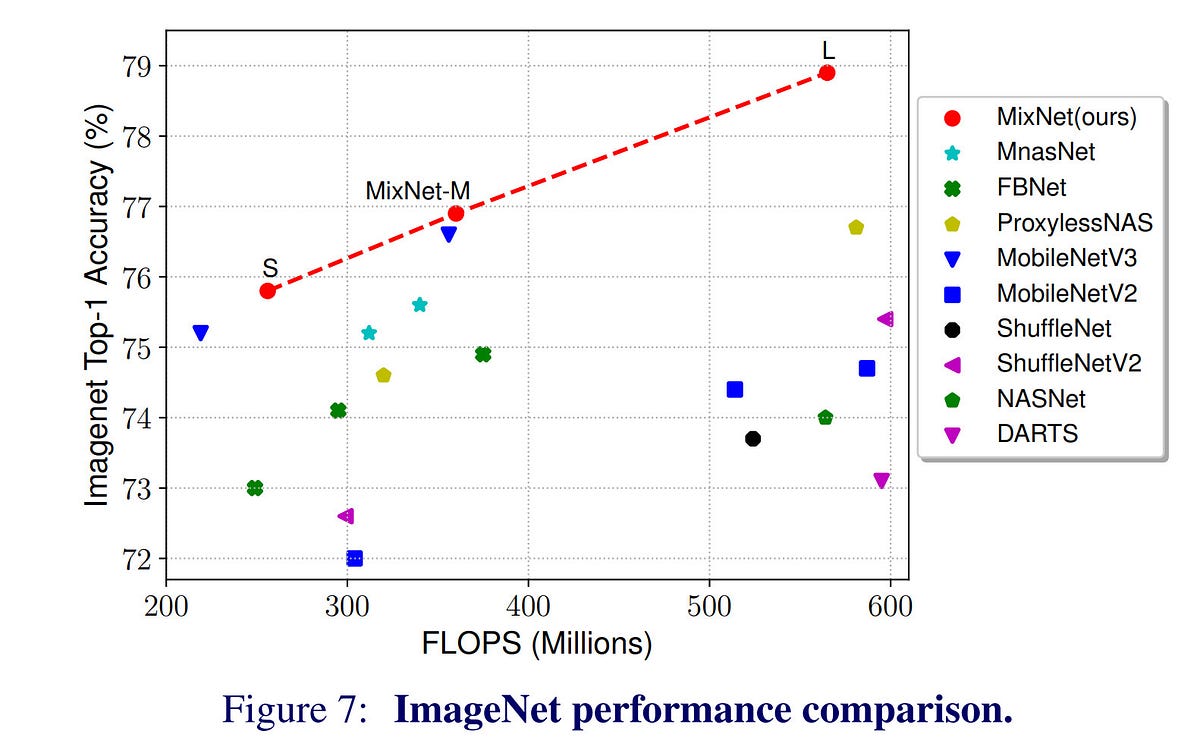
在下面的链接中共享的Google MixNet具有将以上两个特征组合为一个的结构。换句话说,在使用深度可分离卷积时,将应用各种大小的内核。实验的结果令人惊讶。与ResNet-153相比,在ImageNet-1K任务中,仅参数的1/12和操作的1/28表现出相同的性能。
但是,这并不意味着MixNet比ResNet快28倍。通常,对于最高效的GPU操作,必须重复执行``大'',``相同''的操作,但是深度卷积比标准卷积要复杂得多,因为它被拆分并应用到每个卷积中,并且最终随着操作数量的减少,性能没有差异。盗梦空间也是如此。它更复杂,因为它分为多个内核并执行每个操作,并且比非接收结构慢。另外,由于发生“分支”,因此在简单的实现中所需的内存也增加了。
作为参考,在残留网络(即跳过连接)的情况下,参数数量不会增加1度,并且仅通过MFLOPS计算得出的计算量几乎相同,但是在实践中进行测量时,执行时间会受到显着影响。 (我知道这也是因为发生“分支”。)存储过滤前后的内存所需的内存也增加了。
这并不意味着MixNet不好,我将在以后使用它,^^,但是我认为仅通过参数和操作的数量就不能完全表达网络的复杂性。实际上,MixNet-S的参数比MobileNet-V3少30%,但在Google Pixel进行的推理测试中,MobileNet-V3的速度是后者的两倍。我认为“结构简单”和“实现相似性”是实际上具有很大影响力的一个例子。作为参考,在硬件实现上更为明显。实现成本在3×3、5×5和7×7之间存在差异,远大于参数数量上的差异。