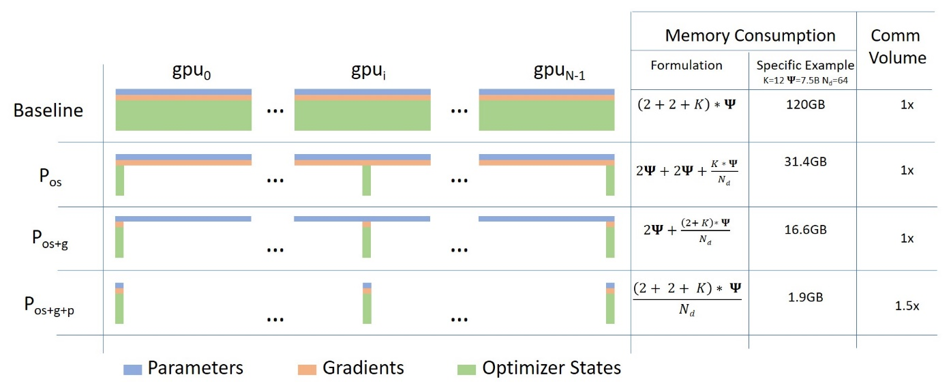
随着深度学习模型的参数数量显着增加,训练所需的内存也随之增加。 OpenAI的GPT-2由1.5B参数组成,而Google的mT5也具有13B参数。另外,OpenAI的GPT-3的参数数量达到175B。在这种大型号的情况下,即使尝试使用小数据进行微调,也很难轻松地尝试它,因为它需要大量的GPU内存。
微软发表的一篇论文《 ZeRO:训练万亿参数模型的内存优化》涵盖了缓解此问题的技术,并且已知可以显着减少所需的最大内存量。这是论文的链接:
ZeRO:针对训练万亿参数模型的内存优化
大型深度学习模型可显着提高准确性,但需要培训
数十亿到数万亿的参数具有挑战性。现有解决方案,例如
数据和模型并行性显示出适合这些模型的基本限制
进入有限的设备内存,同时获得计算,通信...
数十亿到数万亿的参数具有挑战性。现有解决方案,例如
数据和模型并行性显示出适合这些模型的基本限制
进入有限的设备内存,同时获得计算,通信...
Microsoft已在本白皮书中以DeepSpeed的名义发布了许多实现的技术。据说使用DeepSpeed,与以前的内存相比,内存需求可以减少1/10,从而可以使用10倍大的批量大小或10倍大的模型。 Microsoft使用此库来训练带有17B参数的模型Turing-NLG。同时,Facebook还以FairScale的名义发布了该论文中实现的技术。这是DeepSpeed和FairScale的github存储库的链接:


此外,众所周知的自然语言框架HuggingFace在4.2.0版本中实现了DeepSpeed和FairScale,并且仅需几个参数设置即可轻松使用。例如,对于具有3B参数的mT5-3B型号,即使批量大小为1,一个RTX 3090 24G GPU也会导致内存错误,但是据说如果您在以下位置使用DeepSpeed,FairScale和FP16,同时,您可以以20的批量学习。我们分享相关分析的文章: