
自从由多层卷积层组成的AlexNet问世以来,已有许多关于深度学习模型结构的研究。
例如,Google Inception使用了一种通过创建和串联具有不同内核大小(例如3×3、5×5、7×7等)的卷积层来提高每个参数效率的方法,而Microsoft ResNet使用了跳过连接。换句话说,通过创建一个不经过卷积层的数据路径并将其添加到通过卷积层的结果中,即使在具有数千个或更多层的复杂结构中,也可以防止梯度消失。这两种方法都很简单有效,因此它们被积极用于设计其他深度学习模型。
另一方面,尽管方法不同,但在Google MobileNet和Xception中使用了一种称为深度可分离卷积的技术,以降低复杂度,同时提高每个参数的性能,而在ShuffleNet中,通过添加随机改组来降低复杂度层。
但是,在初始情况下,数学上3×3、5×5和7×7内核的组合是仅使用7×7内核的子集,因此对于降低复杂度而不是改善模型表达式很有意义实际上,与使用一个内核相比,数据路径很多,因此与减少参数数量相比,速度提升并不明显。深度方向可分卷积也是如此,在深度方向卷积(即组卷积的一种形式)中,可以将其视为2D卷积和1D卷积的组合,在这种情况下,参数数量与使用3D卷积,但实际实现后的性能改进不是很大。这可以看作是将一个并行操作分解为两个操作而导致的效率下降。
就ResNet而言,有许多关于为什么学习效果很好的子研究。对具有相对较小变化的残差信号进行建模的分析会更有效,因为将经过卷积层的信号与不类似的信号相加,类似于将原始信号分解为预测值和残差信号(增加另一方面,有观点认为,通过简单地将多层划分为较小的层,在学习之后这仅仅是一种合奏(学习技术)的形式。为了进一步说明,在后一种情况下,使用跳过连接实际上可以起到跳过一个卷积层的作用,从而产生减少层数的效果。
就个人而言,我在训练ResNet系列的深度学习模型时不断观察体重变化的经历是相似的。换句话说,在学习开始时会更多地使用跳过连接,但是随着学习的逐步进行,跳过连接的作用会降低。此外,在学习阶段使用了ResNet,但是在学习完成之后,我看到了删除跳过连接并进一步训练几个纪元以达到类似性能的情况。
RepVGG的作者试图仅使用卷积层来提高性能,而不使用多个数据路径和诸如Inception或Residual Network之类的复杂结构。这项尝试的有趣之处在于,在学习和推理阶段将模型结构不同地使用。以下是本文包含的图片:
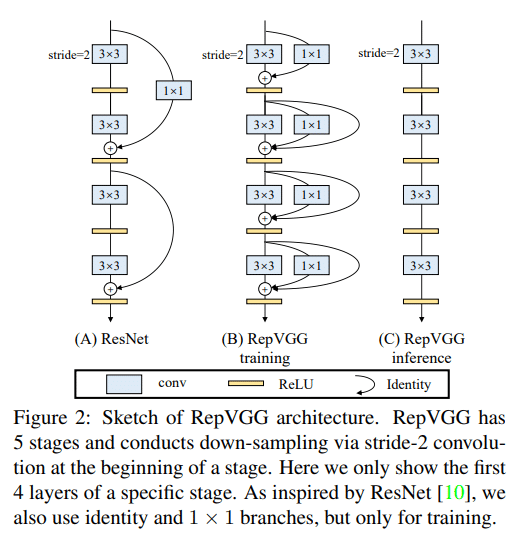
通常,ResNet重复使用Input-Relu-Conv-Output组合,该组合使用一种将尺寸与1×1卷积对齐并将其添加到输出的方法。输入和输出之间存在非线性函数Relu。相反,RepVGG将Conv本身(这是一个线性运算步骤)划分为多个数据路径。每个划分的路径由具有各种核的卷积组成,例如3×3卷积和1×1卷积。据说学习表现良好,没有梯度消失问题,并且与ResNet等现有模型相比,具有更好的性能。
注意,由于仅将线性运算步骤划分为多个数据路径,因此在训练完成之后,可以通过简单的计算将这些数据路径组合为一个卷积。 RepVGG的作者将这种结构重新参数化,并在此过程之后最终通过一个简单的卷积运算收敛,该运算可用于推理阶段。结果,在RepVGG中,仅使用了3×3的卷积,并且由于未使用跳过连接,因此被表示为VGG状。该实现的结果具有简单的数据路径,并且对于硬件实现是有利的。作为实际实验的结果,即使由软件运行,它也比ResNet更快,性能更好。
以上结果表明,残差网络不是用于改进模型表达的技术,而是用于提高学习易用性的技术。当然,这并不意味着Residual Network不是有用的技术,但是RepVGG的实验结果更加有趣,因为我们可以更清楚地了解跳过连接的作用。 RepVGG在github上分享。







