
[前研究组金成yun]
现代语言模型是使用大型语料库进行训练的。特别是,对于使用解码器神经网络的模型(例如GPT-2,BART和T5模型),可以通过重复采样下一个标记来生成自然语言。在这里,您可以控制采样方法生成的自然语言的属性,例如主题,样式和情感。在本文中,我想介绍一种在生成自然语言时可以使用的有效解码采样策略。众所周知的解码策略是贪婪搜索和波束搜索。
- 贪婪的搜索
在贪婪搜索的情况下,它仅选择概率最高的单词作为下一个单词。
根据公式,它是𝑎𝑟𝑔𝑚𝑎𝑥𝑤𝑃=𝑎𝑟𝑔𝑚𝑎𝑥𝑤𝑃(𝑤|𝑤1:𝑡−1),其中t代表每个时间步长。
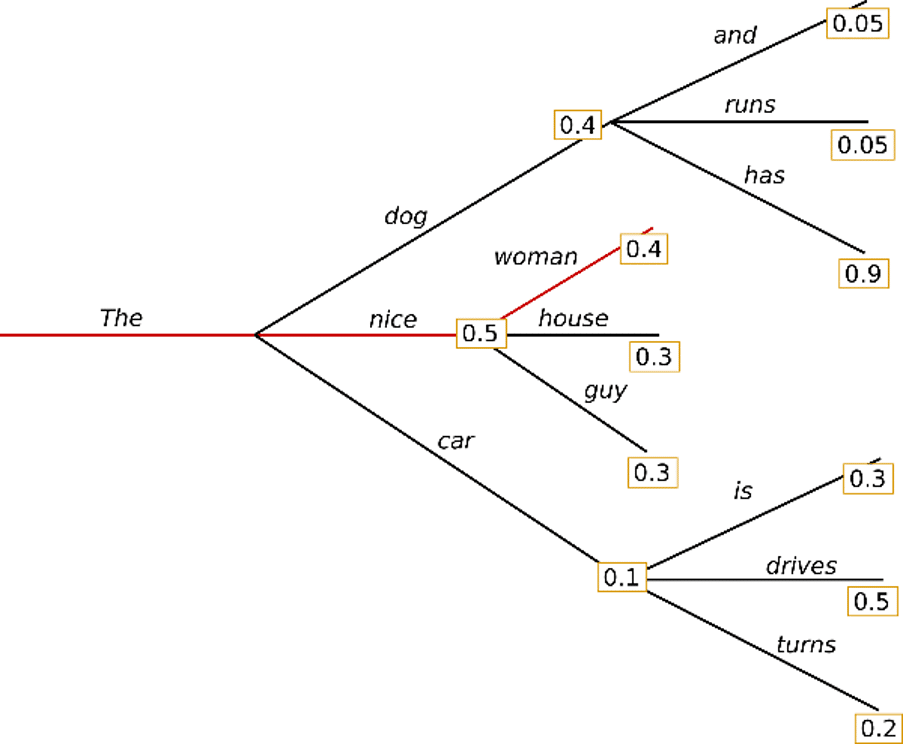
贪婪搜索算法可以从单词“ The”开始,然后选择最可能的单词“ nice”作为下一个单词。最后,生成句子“好女人”,总概率计算为0.5 * 0.4 = 0.2。但是,在这种情况下,某些短语会一遍又一遍地生成。
- 光束搜索
波束搜索会搜索与波束宽度一样多的概率(波束宽度是每个树级别的特定数字),并选择概率最高的树。
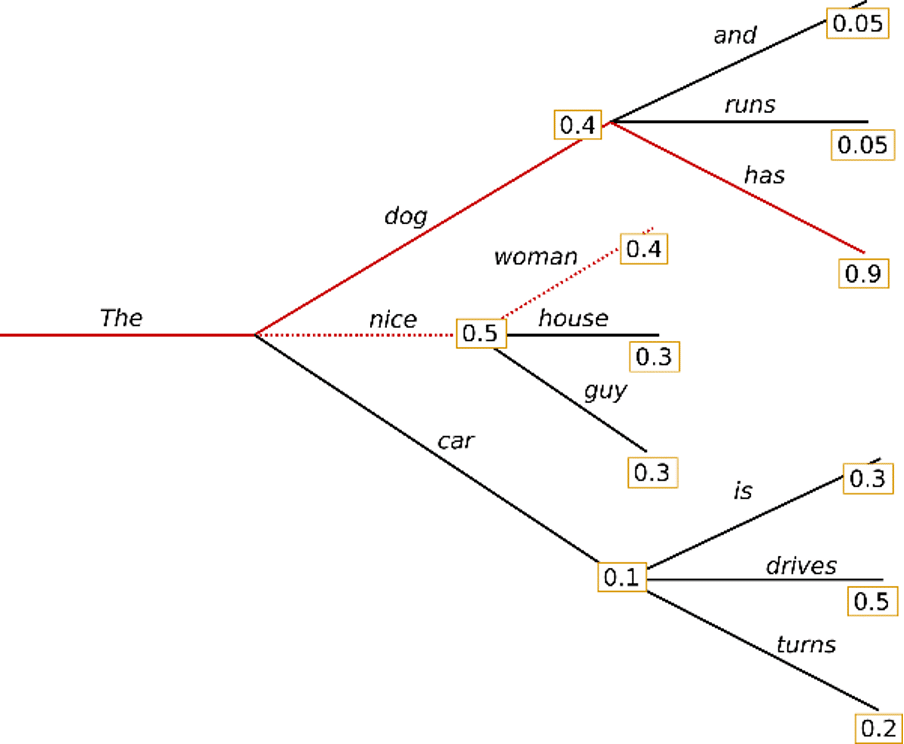
例如,这是光束宽度设置为“ 2”时的示例。此时,从出现在“ The”之后的“ dog”,“ nice”和“ car”中,我们开始一起搜索两个假设,即“ dog”和“ nice”,它们出现的可能性最高。 。
结果,发现“狗拥有”的概率比贪婪搜索选择的“好女人”的概率高0.36。在这种波束搜索的情况下,它可能具有以下特征。
- 它可以很好地用于可预期的句子生成所需长度的任务,例如机器翻译或句子摘要。但是,它在输出长度可能会显着变化的开放式创作中(例如对话或故事创建)无法正常工作。 (Murray等。 (2018), 杨等。 (2018))
- 光束搜索容易受到迭代生成问题的影响。
另外,Ari Holtzman等。根据(2019)论文,人为选择的语言将具有更高的差异。
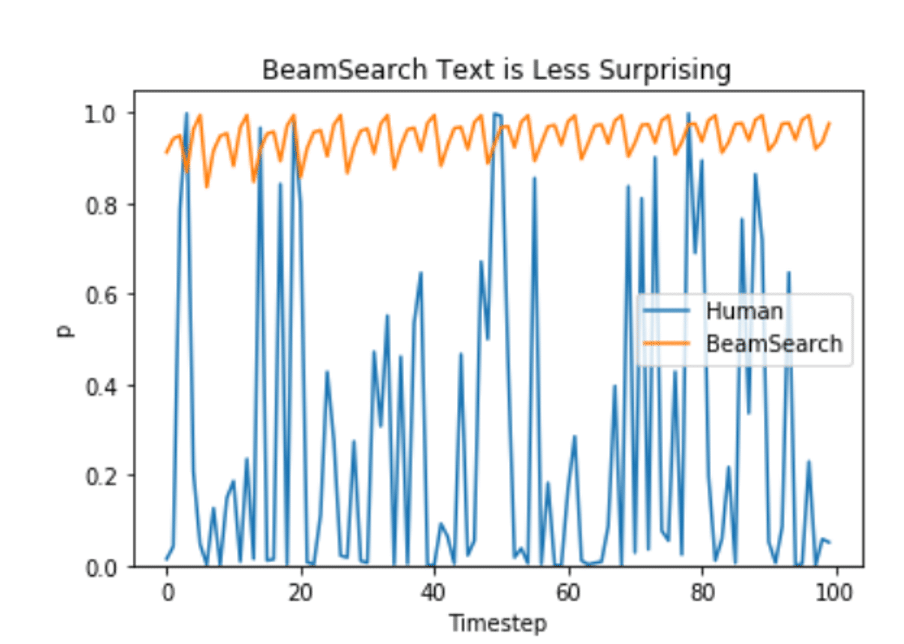
那么,什么是更好的生成策略?
让我们通过下面的练习代码来了解基于KoGPT-2的自然语言生成策略。
https://colab.research.google.com/drive/1yUGVmQ0nj8Hd3h0YV6PemQx0FtzpefGB?usp=sharing
参考
https://lilianweng.github.io/lil-log/2021/01/02/controllable-neural-text-generation.html
https://huggingface.co/blog/how-to-generate






