
[前研究小组李政宇]
最近的强化学习表明,AI代理可以在各种任务中支配人类绩效。但是,未经学习的AI代理的缺点是,它需要大量的时间来学习,并且与人类相比,各种任务的泛化性能很差。另一方面,与AI代理不同,人类可以很好地适应新情况并具有继续学习新知识的能力。持续学习是通过提及这些人的能力而诞生的。在本文中 走向持续强化学习:回顾与展望 通过(Khetarpal等人,2020年),我想介绍适合现实情况的持续强化学习。
- 强化学习
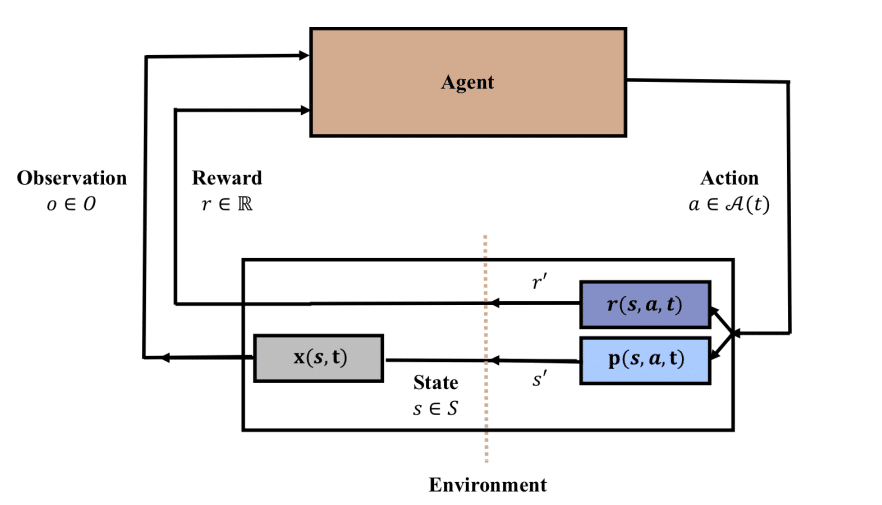
上图显示了强化学习的基本形式。本文的作者讨论了强化学习的状态,动作和奖励的时间依赖性部分。如果环境是无法再次回到过去的无限场景,则可以从非平稳的角度进行查看,因为现实世界已经过去的状态无法返回。这种自然的时间流逝和维持过去能力的条件是实验和验证持续学习的最佳条件。
- 持续学习
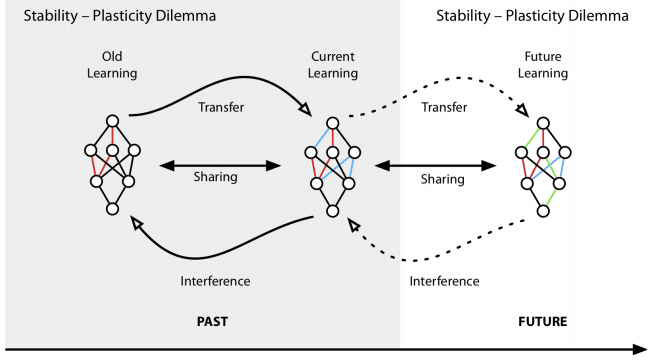
持续学习旨在解决“稳定性-可塑性难题”。牺牲可塑性以保持稳定性,您可以保留过去所学的知识,但对于新近学到的知识却可能虚弱。相反,将注意力集中在新知识上,会引起灾难性的遗忘问题。保持在稳定性和可塑性之间从过去学习的能力并实现不断的新学习是持续学习的关键。
- 持续强化学习
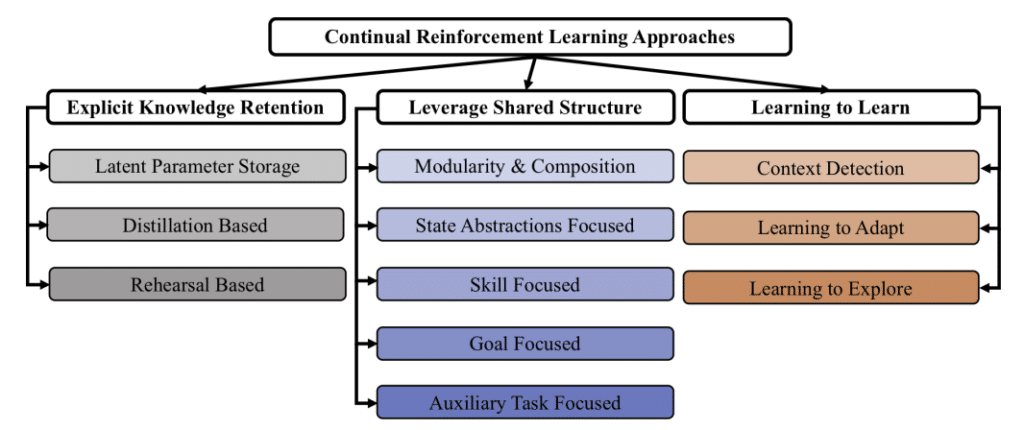
连续RL有三个主要目标。
- 明确的知识保留:通过防止在学习过程中发生的灾难性遗忘来维护知识,提高稳定性并确保最佳可塑性。
- 利用共享结构:在AI代理不断学习的情况下,用于解决问题的结构方面和从过去解决的子问题中获得的解决方案将被重用,并自动用于计划,学习和推理。充分利用此共享结构。
- 学习学习:最后,旨在学习如何自我学习。基本上,它的目标与元学习相同。
通过三个主要目标,我们通过掌握所学知识的共享结构,同时保持像人类一样的过去知识,学习学习如何学习和发展。
- 评估持续强化学习
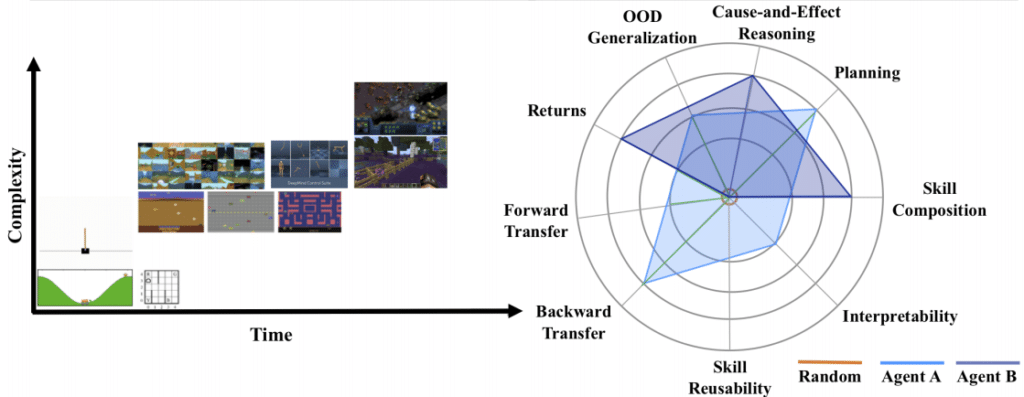
为了评估前面讨论的Continual RL的各个方面,本文描述了评估Continual RL代理的七个指标。
- 灾难性遗忘(向前和向后转移):评估AI代理是否可以在新的相关上下文中有效使用先前获得的知识(向前转移),是否可以提高以前在当前上下文中学习的类似功能的性能。
- 技能可重用性:遇到新的,无经验的情况时,请评估您是否可以重用以前学习的技能并创建新的技能。
- 可解释性:定性评估学习的代表,获得的行为,价值函数和策略,并利用它们来提高学习率和分数。
- 技能组成:评估代理人是否更有效地使用了先前从该数据中学到的知识。
- 规划:评估您是否可以使用已获得的知识来有效地规划未来。
- 因果推理:通过因果分析来衡量代理是否在实际学习环境中的规则和对象。
- OOD(Out of Distribution)泛化:可以通过零散预测来预测收益,并可以通过样本的复杂性来评估代理的泛化性能。
为了创建类似于人的学习过程,本文引入了多个领域,例如终身学习,在线学习和永无止境的学习以及Continual RL。很高兴看到,连续学习法(最近出现的连续学习法和在某些领域超过人类表现的强化学习法)的结合是否会显示出另一种增长潜力。
- 参考
https://arxiv.org/abs/2012.13490






