
[服务开发组,Kyunghwan Lee]
我们在训练模型时通常会遇到一堆未标记的数据,并且经常遇到数据标注问题。这是因为将所有未标记的数据一一标记既耗时又昂贵。为此,在很多情况下通过随机选择数据来执行注释。如果您随机选择和标记数据,则您可能拥有一小部分数据,网络难以预测其答案,这将有助于提高模型的性能。如果已经进行了使网络易于预测答案的数据驱动学习,那么当实际网络难以预测的数据出来时,答案将难以匹配。
主动学习是一种通过识别模型难以处理的数据来帮助用户有效学习数据的技术。模型如何确定哪些数据是困难的,是主动学习的核心。由于它是一项已经发展了 20 多年的技术,因此存在各种识别方法。示例包括基于不确定性的方法、基于多样性的方法和预期模型更改。然而,上述三种方法都存在局限性,例如难以普遍使用或由于计算量大而难以应用于深度学习网络。
Learning Loss for Active Learning (CVPR 19) 提出了一种被广泛使用且易于应用于深度学习网络的损失预测模块。

另一个网络,损失预测模块,放置在主模型(也称为目标模块,例如图像分类模型)旁边以预测损失。它是一种通过估计输入数据的损失来确定网络难以学习的数据的方法。
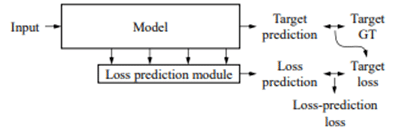
作为损失函数,使用了 Margin Ranking Loss。您可能想知道为什么没有使用相对流行的均方损失 (MSE) 方法,但是在使用 MSE 时,存在一个限制,即目标损失的规模不断变化。因此,我们使用了 Margin Ranking Loss,它不受目标损失规模变化的影响。

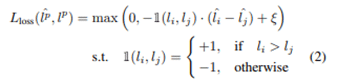
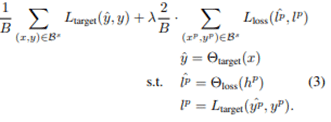
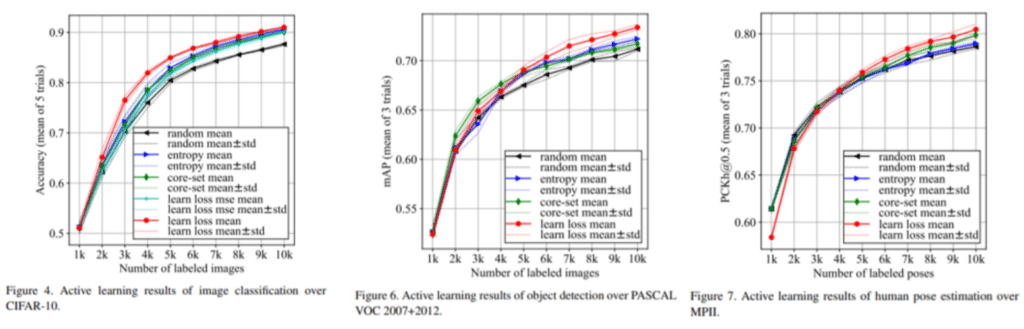
在本文中,我们对图像分类、目标检测和姿态估计等三个任务进行了实验,并分享了与其他主动学习方法相比获得了相对较好结果的事实。分别使用了CIFAR 10数据集/PASCAL VOC 2007+2012数据集/MPI数据集,与随机采样方法、基于熵的采样方法和核心集采样方法相比,性能被证明是优越的。在所有三项任务中,都展示了超越现有方法的性能。
随着人工智能技术的不断进步,对大量数据进行标注变得越来越必要。我们通过建议您使用 Learning Loss for Active Learning 中介绍的损失预测模块解决方案来结束本文。
参考 - 论文:https://arxiv.org/abs/1905.03677
参考 - https://kmhana.tistory.com/10






