
[服务开发组黄俊善]
在监督学习机器学习模型时,如果使用标签间数据数量不均衡的数据集作为训练数据,则会出现对属于小比例标签的样本训练效果不佳的现象。如果单纯的样本数量少,训练效果不会很好,即使有足够的样本可以学习,如果比例差异过大,模型也会有偏差。这尤其常见,例如,当异常数据的分类问题是标签过多而无法分类时。在这种情况下,无论 state-of-the-art 模型有多好,也很难推导出正确的性能。有四种主要方法可以解决这些问题。
- 使用适当的评估指标
它不是直接解决不平衡数据集问题的方法的一部分,而是可以说是准确解释和理解当前训练的模型并应用后面描述的解决方案的第一步。例如,假设我们有一个标签 0 和 1 的二元分类问题,属于标签 0 的样本占整个数据集的比例为 99%,属于标签 1 的样本比例为 1%。如果训练后的模型将所有数据分类为 0,则该模型的准确度为 99%。虽然这个精度不是一个错误的指标,但是这个99%性能指标能正确的告诉这个型号的性能吗?一般来说,我们希望在这些数据中正确分类 1,而不是 0。如果是这样,这个指标就没有价值了。因此,推荐使用以下评价指标[1],不仅可以看到准确性,还可以看到各个方面。
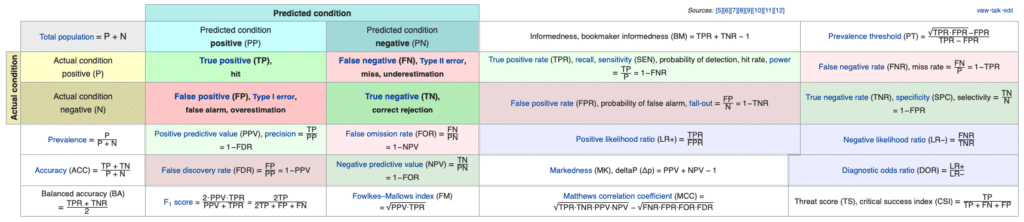
- 精度:真阳性/(真阳性+假阳性);模型归类为真而实际为真(拟合)的百分比
- 召回:真阳性/(真阳性+假阴性);模型预测为真的(拟合)与实际为真的模型的比例
- F1 分数:2 * Precision * Recall /(Precision + Recall);准确率和召回率的调和平均值
- ACU:指ROC曲线下的面积,表示一个分类模型在所有阈值下的表现的图表
在以上指标中,可以看出,对于比例较小的标签,其准确率和召回率都非常低。换句话说,它没有针对该标签进行过良好的训练。
- 对训练数据集进行采样
如果通过上述评估指标确定模型没有训练好,这是第一个可以简单应用的策略。您可以通过匹配标签之间的比例来解决不平衡问题。
- 欠采样[2]:通过减少占据较大比例的样本数量来创建平衡数据集,这种方法可以在数据量足够的情况下使用。
- 过采样[3]:通过增加占据较小比例的样本数量来创建平衡数据集,这种方法可以在数据量不足时使用。 (例如重复、引导、SMOTE、ROSE)
上述两种方法[4]的适当组合将导致更好的采样器。另外,常用的深度学习框架PyTorch的Imbalanced Dataset Sampler[5]已经发布,可以参考一下。但是,如果属于你要分类的标签的数据极少,不足以学习,单靠抽样方法可能无法解决。
- 数据增强
当数据数量极少时,可以使用这种方法。但是,是否以及如何应用此数据增强方法将因任务而异,具体取决于领域。
- 图像增强

- 文本增强
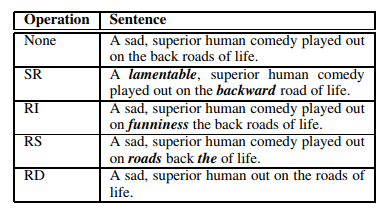
上面的例子是一种普遍应用于图像和文本数据的数据增强技术。具有低比率标签的样本,而不是具有高比率标签的样本,可以进行扩充并用于训练以提高性能。
- 对不平衡数据集使用损失函数
最后,使用适合不平衡数据的损失函数。不平衡数据最流行的损失函数之一是 Focal Loss[6]。除此之外,还有各种损失函数,还有LADE Loss[7],将在CVPR 2021中引入。
- Focal Loss:通过基于分类误差对损失值进行加权来解决
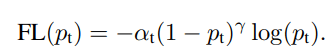
LADE Loss:通过将不平衡训练数据的标签分布分布到目标数据的标签分布来解决。
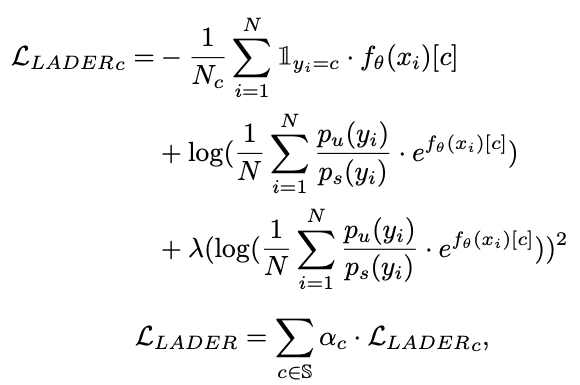
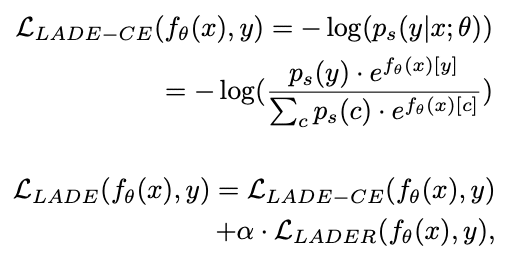
比所描述的方法更基本的解决方案是获取更多数据集。然而,收集适当的数据集和标记的成本是巨大的。如果用于您尝试解决的问题的数据集数量不足以训练机器学习模型,则上述所有方法可能都无法解决。如果数据集足够,但高度不平衡,则可以应用上述方法来驱动性能。最后一个方法,使用损失函数的方法,将作为代码共享,我将完成该帖子。
https://github.com/Joonsun-Hwang/imbalance-loss-test/blob/main/Loss%20Test.ipynb
[1] https://en.wikipedia.org/wiki/Precision_and_recall
[2] https://imbalanced-learn.org/stable/under_sampling.html
[3] https://imbalanced-learn.org/stable/over_sampling.html
[4] https://imbalanced-learn.org/stable/combine.html
[5] https://github.com/ufoym/imbalanced-dataset-sampler
[6] https://arxiv.org/abs/1708.02002
[7] https://github.com/hyperconnect/LADE






