[前研究组柳熙Jo]
文本转语音(TTS)是一种将任意文本转换为特定语音的语音并进行计算的技术。谷歌发布Tacotron系列后,迅速从基于HMM(隐马尔可夫模型)转向基于深度学习,目前商业服务的模型往往是在深度学习的基础上运行的。改进已经足够商业化,相关研究也在从“简单实现”转向“新功能”和“优化”。
Neo Sapiens 最近推出了 MLP Singer,这是一种新的 TTS 模型,正如其名称所暗示的那样唱歌。虽然微软的 HiFiSinger 是作为现有的非自回归唱歌 TTS 发布的,它使用了 Transformer 的持续时间预测器,但通过排除持续时间预测器并使用 MLP 混合器代替 Transformer,它在减轻重量方面是一个显着改进的模型。
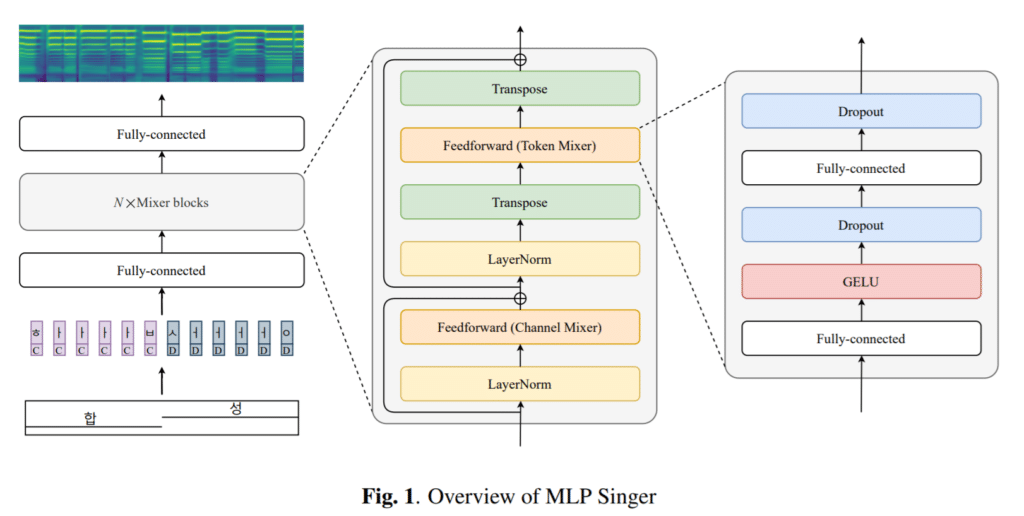
当然,虽然最近商业化的 TTS MOS 超过了 4 点范围并产生了与人类几乎无法区分的声音,但发布的模型的 TTS 仍然在早期的 3 点范围内,所以似乎还有很大的空间改进。但是,与现有的 TTS 一样,它有望通过数据积累和模型细化得到快速发展。
KAIST去年发布的韩/英歌曲数据集也在5月份发布,从数据中学习到的demo是公开的,所以你可能想听听。详情请参考下面的链接,该链接是论文中发布的演示站点。
演示链接: https://mlpsinger.github.io/
Github 链接: https://github.com/neosapience/mlp-singer
参考
Tae, J.、Kim, H. 和 Lee, Y.(2021 年)。 MLP 歌手:迈向快速并行韩国歌声合成。 arXiv 预印本 arXiv:2106.07886.
Choi, S.、Kim, W.、Park, S.、Yong, S. 和 Nam, J.(2020 年 10 月)。用于声乐研究的儿歌数据集。在 第 21 届国际音乐信息检索学会 (ISMIR).国际音乐信息检索协会。
Chen, J., Tan, X., Luan, J., Qin, T., & Liu, T.Y. (2020)。 Hifisinger:走向高保真神经歌声合成。 arXiv 预印本 arXiv:2009.01776.






