
[前研究小组沉宏前]
随着 Open AI 的 GPT-3 和 NAVER 的 Hyper CLOVA 等超巨型语言模型的发布,最近使用它们的各种示例和服务不断涌现。所有这些超级语言模型都具有惊人的能力,可以通过展示与新任务(= 任务)相关的简单示例而无需梯度更新来学习如何自行执行新任务。然而,虽然这些语言模型很好地执行了基于文本的任务,但它们并没有完全展示它们对文本以外的任务(例如 Visual Task)的能力。
最近,DeepMind 通过一篇论文公开了一种名为 Frozen 的方法,可以为自回归语言模型执行 Visual Tasks。在本文中,我们提出了一种简单有效的方法将少样本学习能力转移到“多模态”。通过学习视觉编码器使用图像-字幕对数据将每个图像表示为一系列连续嵌入,预训练的、冻结的语言模型可以使用此前缀信息生成适当的字幕。
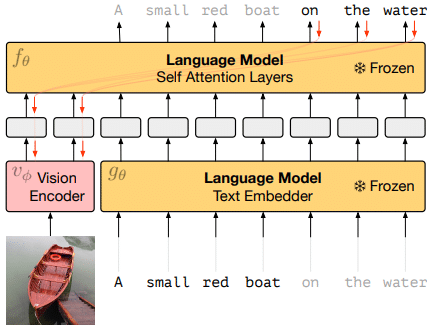
图[1]展示了包括本文介绍的视觉编码器在内的整个系统结构。图中两个Language Model的参数是固定和冻结的。 Vision Encoder 使用左侧的图像编码信息和右侧字幕的一些编码信息进行学习,以便语言模型(Self Attention Layers)可以生成字幕的其余部分。语言模型的权重保持固定,但梯度通过它传播回来以从头开始训练图像编码器。
使用上述结构训练的 Frozen 在本文中称为多模态小样本学习器。 Frozen 是在单个图像字幕对上训练的,但是一旦训练,它也可以有效地响应与多个图像和文本对齐的集合。此外,即使在未经训练的多模态任务(例如视觉问答 (VQA))中,它也具有通过利用预训练的语言模型来学习新任务的惊人能力。在本文中,为了提高frozen在多模态任务中的少镜头学习性能,在比较多个任务的镜头的同时进行了实验。
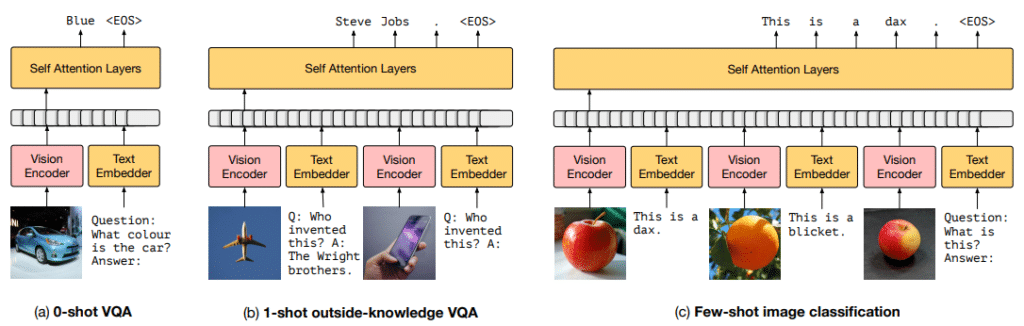
下图[3]显示了将上述实验得到的最优设置应用于Frozen模型后的测试数据的测试结果。如果你看图的第一行,如果你把两张图片和一个标题作为例子,最后提供一个图片和文字信息“这个人是谁”作为暗示词,模型最终生成了“惊恐”恐怖”表情符号。第二行也给出了一个类似格式的例子,只能得到“飞机”的信息作为图像信息,但是语言模型中也包含了事实知识,所以最终的模型是人的“莱特兄弟”谁发明了飞机我们可以为您提供答案。 Frozen 的吸引力在于它可以通过结合语言模型的视觉信息和事实知识信息来执行此类任务。

开发 Frozen 的目标不是在特定任务中最大化性能,因此它具有执行任务所必需的能力,但与 SOTA 在几次学习的特定任务上的性能仍然存在差异。然而,在没有查看基准提供的所有必要训练示例的情况下,各种任务的性能远远超过基线。此外,如图 [3] 所示,Frozen 经常产生有吸引力的输出,可以将其视为一个系统,用于对图像进行真正开放和不受约束的语言解释。
到目前为止,我们已经介绍了如何使用 Frozen 将大规模语言模型转换为多模态小样本学习系统。更多细节请参考论文。
参考
[1] Tsimpoukelli, M., Menick, J., Cabi, S., Eslami, S.M., Vinyals, O., & Hill, F. (2021)。使用冻结语言模型的多模态小样本学习。 arXiv 预印本 arXiv:2106.13884.
[2] https://www.youtube.com/watch?v=FYA_jwPpXi0






