
[融合研究组Hongmae Shim]
如果你选出 2020 年 NLP 领域的前 10 个关键词, GPT-3 (语言模型是少数学习者) 当然,它会在排名中。时至今日,GPT-3 庞大的参数量和卓越的性能仍然在 NLP 领域内外越来越受欢迎。然而,作为一名 NLP 研究人员,GPT-3 对 state-of-the-art 研究的最大贡献是在一般工作中(尤其是零样本和少样本)。 即时调优 我认为这证明了该技术的适用性。在 GPT-3 之前,prompt-tuning 主要用于探索语言模型中嵌入(latent)的知识,近两年大量相关论文作为一个非常热门的关键词涌出。
Prompt-tuning 和 GPT-3 的共同成就在 NLP 的发展史上是不可忽视的。基于提示调优的 GPT-3 在执行各种类型的任务时表现出良好的性能,但仔细想想,GPT-3 不是具有更好的零样本和少样本学习能力来执行这些惊人的任务吗?提示调优是使用 GPT-3 的最佳方式吗?
最近,谷歌研究人员开发了一种指令调优方法,在使用比 GPT-3 (175B) 更少的参数 (137B) 的 25 项任务中,有 19 项的性能明显优于 GPT-3。 水果馅饼 (F调和 局域网guage 模型是零样本学习者)通过暗示 GPT-3 可以变得更强大。
GPT-3 ( 局域网guage 模型是零样本学习者) 相比 水果馅饼让我们与众不同的是我们的微调。 水果馅饼核心思想是微调各种NLP任务,通过将它们转化为自然语言指令(一种任务指令或指令)来解决这些任务。 (参考下面[图1]中的(C))
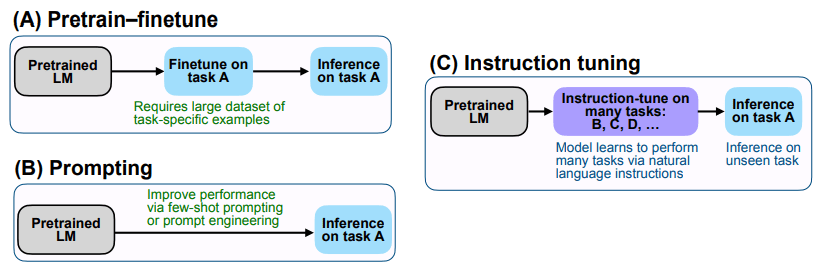
为了更详细地解释,FLAN 首先对预训练的 LM 进行微调,使其可以执行许多不同的 NLP 任务,包括翻译、常识推理、情感分类等。例如,如下面的 [图 2] 所示,对于翻译任务“将这句话翻译成西班牙语”,对于情感分类任务,使用命令/指令“该电影评论的情感是正面的还是负面的?”微调完成后,模型可以使用包含这些命令/指南的信息执行各种任务,将现有知识应用于命令“前提是否包含假设?”您可以更好地使用它来回答它。
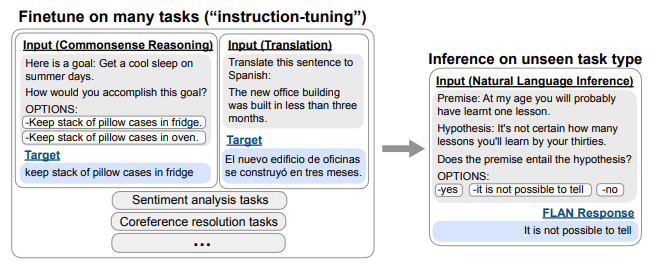
在论文中,作者发现 FLAN 甚至可以在学习了网页、编程语言、对话和维基百科句子后没有明确学习的任务上学习操作。通过这种方式,指令调优可以通过教授模型如何执行表示为一种命令/指令的 NLP 任务来提高处理和理解自然语言的能力。这意味着我们可以部分理解自然语言的真实意图。
在 FLAN 的论文中,通过选取 12 个类别共 62 个常见的自然语言处理和生成任务相关数据进行了调优实验。 (参考【图3】)
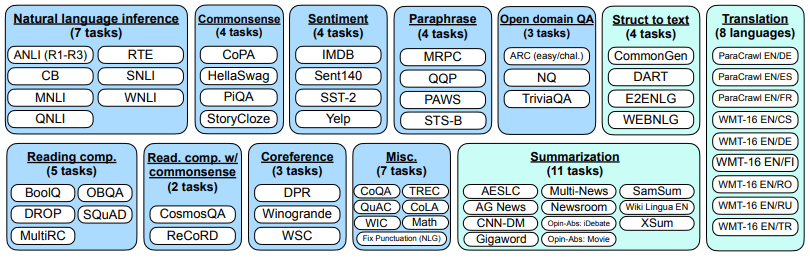
作者使用大小为 137B 的自回归语言模型 (Base LM) 作为基础语言模型。指令调整管道混合了 60 多个 nlp 任务的所有数据集,并从每个数据集中随机采样。每个数据集中的样本数量差异很大,有些数据集的训练样本(例如翻译)超过1000万个,将每个数据集中的最终训练样本数量限制在30,000个。在实验中,T5-11B和GPT-3被用作参考模型。
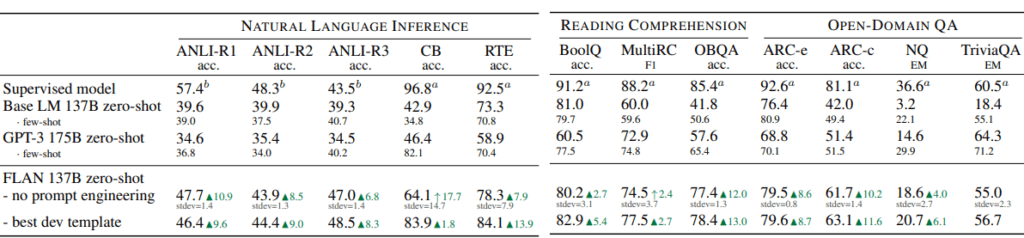
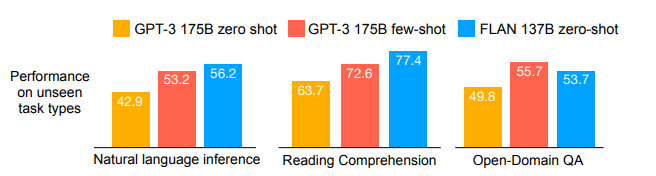
作为实验的结果,FLAN 在自然语言推理任务和 QA 任务中的零样本场景中的表现已经优于少样本 GPT-3,并且在许多任务中取得了与监督模型相似的性能([图 4] , [下图 5] ] 注.) 论文中还包含了其他各种任务的实验结果,如有必要,请自行检查论文。
熟悉NLP的人可能会认为这篇文章是另一个“A+B”任务(A=提示调优,B=多任务学习)。但是,这些 A+B 将是 通用自然语言处理模型去做 解决方案/方法我想这可能是。首先,通过大量未标注的语料,训练一个千亿参数的大规模自回归预训练模型,或者选择一个现有的训练模型,在第二步,这些模型是可以微调理解的和创作任务。在微调过程中,使用类似于课程学习的方法,可以先训练一个较低级别的任务(例如 NER 识别、序列语义注释),然后再训练一个较高级别的任务(例如逻辑推理、QA)。它还首先学习资源丰富的任务(例如英语/大数据任务),然后学习较少的资源(例如其他语言/低数据任务),并使用适配器将每个任务的相关部分保留在模型中。最后,我们提供命令/指令,以便模型可以推理新数据和新任务。如果这种通用方法得到充分利用,我很期待它能够执行哪些新任务!
参考:
https://arxiv.org/pdf/2109.01652.pdf






