
[融合研究组, Jihyun Song]
LinkedIn 搜索系统的深度自然语言处理
最近,在学习Rasa开源的过程中,我感受到了聊天机器人系统的结构和优化设计的应用是多么有效。意图和实体的设计和提取也非常重要。这在搜索引擎领域没有什么不同。搜索中有一篇有趣的论文,所以我想简要回顾一下。
自然语言处理的主要目的之一是从用户消息中提取结构化信息。搜索引擎从用户的查询中提取信息并提供适合该查询的答案。
本文介绍了如何通过将搜索引擎分为 5 个组件来使其高效和健壮,还介绍了如何在聊天机器人中使用重要的意图和实体。
为了使搜索系统健壮,需要考虑三个重要因素:延迟、健壮性和搜索效率。为了提高这三个系统的性能,在本研究中,我们通过五个系统的系统结构按固定顺序进行了实验。
5个搜索引擎组件
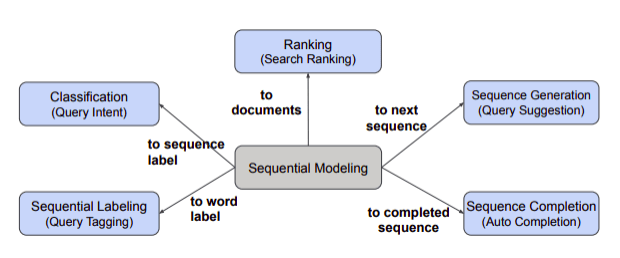
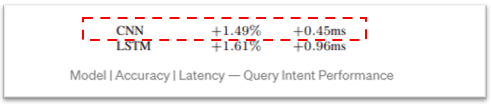
分类(查询意图) — 使用过LinkedIn的人都知道,他们使用了很多意义重大的搜索词,例如职位空缺、职位搜索和帮助中心搜索。首先通过按术语分解查询的意图对查询的意图进行分类。在这个过程中,方法论 美国有线电视新闻网 和LSTM模型进行研究,其中选择和使用延迟最低的CNN。
顺序标记(查询标记)——标记以创建新查询,通过创建符合您意图的实体来创建更好的搜索结果。 CRF, SCRF(当前系统),使用 LSTM-SCRF 模型。
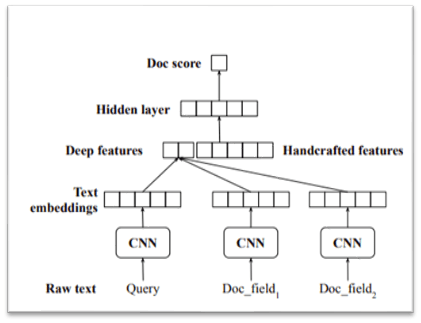
排名(搜索排名)——识别和重新排序最有效和更高的点击率。先用 CNN 预测文档的分数,然后再添加手动特征。
序列生成(查询建议)——要求输入查询和重构查询至少有一个共同词,确定搜索词的频率和重构以确定人们在寻找什么,他们在搜索什么等等。但是,这种方法需要很长时间,并且与搜索结果排名并行提供。在那之后,我能够节省时间。
序列完成(自动完成)——由于查询自动完成功能花费的大部分时间都来自归一化,因此本研究通过导出非归一化的权重来节省时间。
搜索引擎整体系统配置图
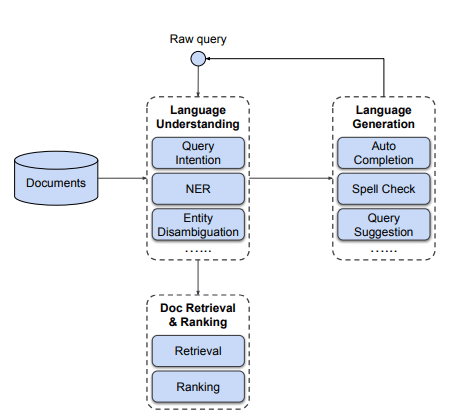
当查询进来时,搜索引擎按以下顺序运行。
- 语言理解:以理解查询意图、消除实体歧义并添加一些缺失部分的方式识别和处理其他细节。
- 语言生成:通过建议自动完成、拼写检查和查询来完成语言生成过程。
- Doc Retrieval & Ranking:通过搜索多个文档并对其中最重要的(如用户点击率)进行排序来计算。
在本文中,据说Deep NLP能够通过生成自然语言和丰富的复述来进行复述,因此在准确性方面具有很高的性能。
为了克服搜索引擎中最大的问题,等待时间,各种方法被提出。
替代方案是算法重新设计、并行计算、预训练嵌入和应用双路径排名计算。
此外,为了搜索的鲁棒性,我们提出了一种使用手动特征以及训练数据去噪和深度学习技术的方法。
通过五个组件创建一个高性能的搜索引擎是本论文的贡献,如果您识别并应用每个组件的特性,将有可能将其用于向聊天机器人输入信息或导入外部知识。
论文 : https://arxiv.org/pdf/2108.08252.pdf






