
[服务开发组林昌大]
높은 정확도를 가진 딥러닝 모델 개발에는 긴 시간이 소요됩니다. 모델 훈련과 미세 조정, 최적화를 거치며 만족하는 모델을 만들기까지 수 주일 또는 수 개월이 걸릴 수 있습니다. NVIDIA NGC 는 AI와 HPC 컨테이너, 사전 훈련된 모델, SDK, 헬름 차트(Helm chart)들을 제공하는 GPU 최적화 허브로 딥러닝 어플리케이션 개발 간소화와 가속화를 위해 고안되었습니다.
NVIDIA NGC 는 컴퓨터 비전, 음성과 언어의 이해와 같은 AI 업무 전반에서 사전 훈련된 모델을 제공합니다.
딥 러닝 모델을 처음부터 구축하려면 대규모의 고품질 데이터를 가지고 있어야 합니다. 하지만 이러한 데이터를 구축하는 것은 쉬운 일이 아닙니다. 그리고 일단 데이터가 확보된다고 하더라도 훈련 용 데이터로의 재구성과 준비가 필요할지도 모릅니다. 결국 데이터 과학자들은 딥 러닝 모델의 설계보다 데이터의 분류 및 정제에 더 긴 시간을 할애해야 하는 문제에 직면합니다.
또한 일반적인 개발 과정에는 오픈 소스 프레임워크로 딥 러닝 모델을 구축한 후 훈련, 개선, 재 훈련을 수차례 거듭하며 다수의 반복(iteration)에서 목표한 수준의 정확도를 달성하는 과정이 필요합니다. 여기에서 딥 러닝 모델의 규모와 복잡성이 또 다른 문제로 작용합니다. 지난 5년 사이 컴퓨팅 리소스에 대한 수요는 5년 전의 ResNet 50에서 현재의 BERT-Megatron 모델에 이르기까지 약 30,000배 증가했습니다. 이러한 대형 모델을 처리하려면 GPU 기반 대규모 클러스터 시스템이 필수적입니다.
사전 훈련된 모델은 그 명칭이 의미하는 바와 같이 특정 분야의 데이터를 이용하여 미리 훈련을 진행한 모델을 말합니다. 이 모델에는 해당 데이터에 맞춰 미세 조정된 가중치가 포함되어 있습니다. 따라서 개발을 가속화하고 싶으면 사전 훈련된 모델을 기반으로 훈련을 수행하여 모델 훈련의 시간을 절약할 수 있습니다. 여기에서 사용되는 기법이 전이 학습(Transfer Learning)입니다.
NVIDIA NGC catalog는 자율주행, 헬스케어, 제조 등 특정 산업에 특화된 사전 훈련된 모델들을 제공합니다.
비전(vision) 데이터를 위해 탐지, 분류, 분할 모델을 제공합니다.
음성(speech) 데이터를 위해 자동 음성인식, 음성 합성, 번역 모델을 제공합니다.
언어(language) 데이터를 위해 언어 모델링, 추천 시스템 모델을 제공합니다.
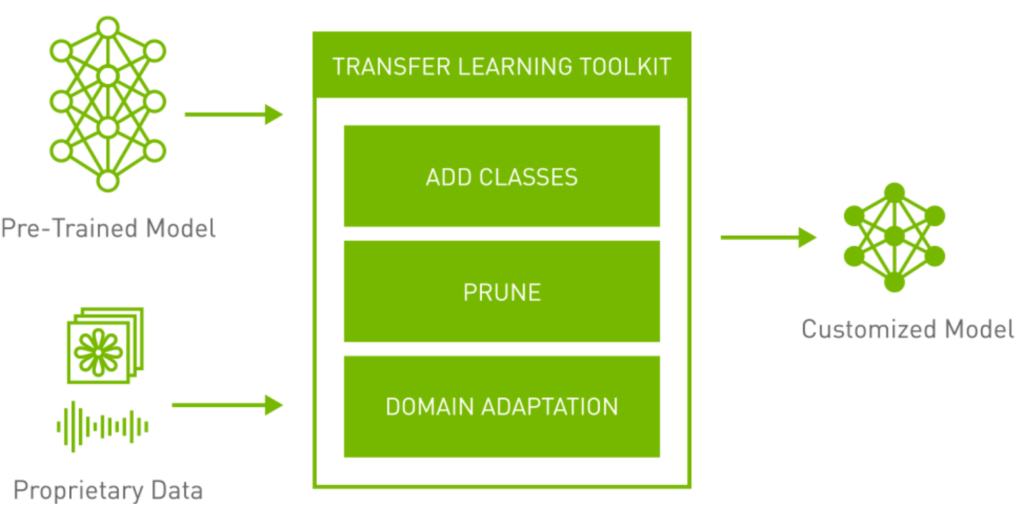
이러한 사전 훈련된 모델은 NVIDIA Research와 NVIDIA의 파트너사들이 직접 개발합니다. 사전에 훈련을 마친 모델은 기존의 산업용 SDK에 원활히 통합할 수 있습니다. 그 예시로 헬스케어를 위한 NVIDIA Clara, 대화형 모델을 위한 NVIDIA Riva, 딥 러닝 추천 시스템을 위한 NVIDIA Merlin, 자율주행 자동차를 위한 NVIDIA DRIVE 등과 손쉽게 통합되어 제작의 속도를 높입니다. 제공되는 모델 중에 선택이 끝나면, 사전에 훈련된 데이터와 다른 산업에 특화된 데이터로 훈련을 진행해야 합니다. 이때 NVIDIA Transfer Learning Toolkit (NVIDIA TLT) 는 Python 기반 딥 러닝 툴킷으로 사전 훈련된 딥 러닝 모델을 가져와 산업에 특화된 데이터로 커스터마이징 해주고 배포도 할 수 있도록 도와줍니다.
参考
https://blogs.nvidia.co.kr/2021/05/26/fast-tracking-hand-gesture-recognition-ai-applications-with-pretrained-models-from-ngc/
https://blogs.nvidia.co.kr/2021/07/05/fast-track-your-production-ai-with-pre-trained-models-and-transfer-learning-toolkit-3-0/






