
[服务开发团队,Hyun-Jun Han]
介绍
사람들은 AI 스피커에서 난청 장애가 있는 사람들을 위한 도구 개발에 이르기까지 광범위한 음성 인식 및 이해 작업에 AI를 이용합니다. 그러나 이러한 음성 이해 시스템은 일상 상황에서 종종 잘 작동하지 않을 때가 있습니다. 여러 사람이 동시에 말을 하거나 배경 소음이 많은 경우, 정교한 소음 억제 기술조차도 이러한 상황을 완벽히 제어하지 못하는 상황이 발생합니다.
현재 인간이 AI보다 말을 더 잘 이해할 수 있는 이유는 인간이 말을 이해하는 과정에서 귀 뿐만 아니라 눈도 사용하기 때문입니다. 예를 들어 보자면 지금 듣고 있는 목소리가 누군가의 입이 움직이는 것을 보고 그 사람에게서 나오는 것이라는 것을 직관적으로 알 수 있습니다. 이러한 상황에서 Meta는 음성을 이해하기 위해 보고 듣는 것으로 학습하는 프레임워크인 AV-HuBERT(Audio-Visual Hidden Unit BERT)를 공개했습니다.
AV-HuBERT는 레이블이 지정되지 않은 데이터에서 말과 입술 움직임을 공동으로 모델링하는 최초의 시스템입니다. 또한 화자의 소리와 이미지를 모두 사용해서 말하는 사람의 말을 이해하는 최고의 AVSR(Audio visual speech recognition) 시스템보다 75%더 정확하고 성능 또한 레이블이 지정된 데이터의 1/10을 사용하여 더 뛰어납니다.
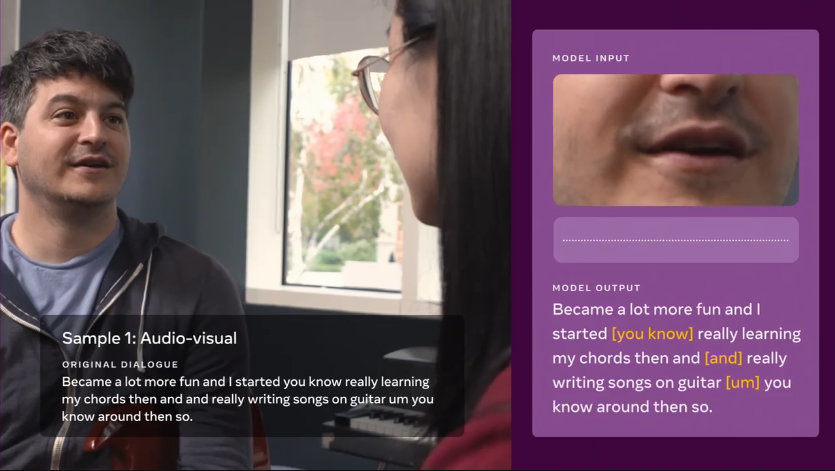
음성 인식을 구축하는 멀티 모달 방법
오늘날의 음성 인식 모델은 입력으로 오디오만 사용하므로 한 사람 또는 여러 사람이 말하고 있는지 아니면 소리가 배경 소음인지를 추측해야 합니다. 그러나 AV-HuBERT는 음성 및 입술 움직임 신호의 조합을 통해 언어를 인지하고 학습함으로써 사람들이 새로운 기술을 멀티 모달의 형태로 습득하는 방법과 유사하게 배웁니다. 공개적으로 사용 가능한 LRS3 및 VoxCeleb 데이터 세트인 비디오 녹화를 사용하여 모델을 훈련했습니다.
AV-HuBERT는 표현 학습을 위한 청각 정보와 함께 말하는 동안 입술과 치아의 움직임과 같은 시각적 신호를 결합하여 사전 훈련을 위해 훨씬 적은 양의 전사되지 않은 비디오 데이터로도 두 입력 스트림 간의 미묘한 연관성을 효율적으로 캡처할 수 있습니다.
사전 훈련된 모델이 구조와 상관 관계를 잘 학습하면 특정 작업이나 다른 언어에 대한 모델을 훈련하는 데 소량의 레이블이 지정된 데이터만 필요합니다.
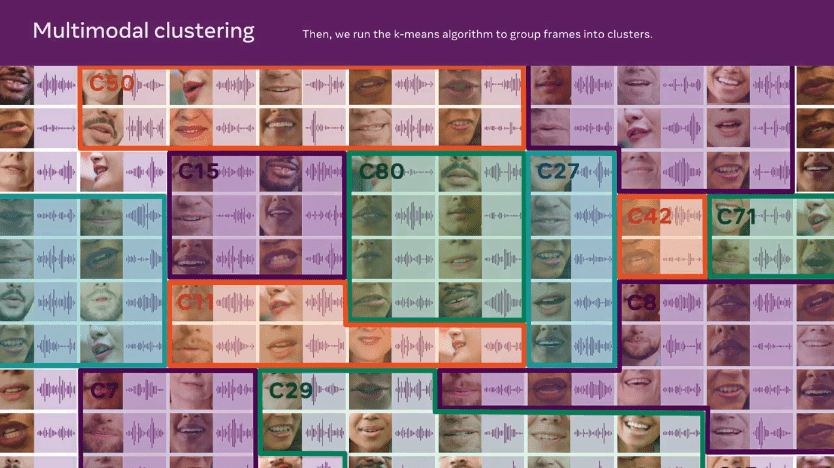
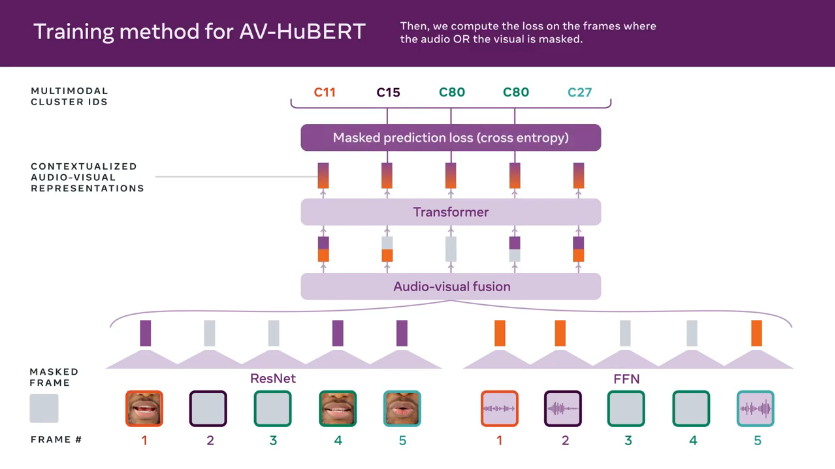
위 그림은 AV-HuBERT 접근 방식을 보여줍니다. 마스킹된 오디오 및 이미지 시퀀스를 하이브리드 ResNet-Transformer 아키텍처를 통해 시청각 기능으로 인코딩하여 미리 결정된 개별 클러스터 할당 시퀀스를 예측합니다. Meta AI’s audio HuBERT approach를 모티브로 자가 지도 음성 표현을 학습하기 위해 AV-HuBERT의 대상 클러스터 할당은 처음에 신호 처리 기반 음향 특성(예: Mel-frequency cepstral 계수 또는 MFCC)에서 생성된 다음 k-평균 클러스터링을 통해 시청각 인코더에서 학습한 기능을 사용하여 반복적으로 정제됩니다.
AV-HuBERT가 학습한 상황별 표현은 모델이 화자를 볼 수는 있지만 들을 수 없는 작업으로의 탁월한 전환 가능성을 보여줍니다. AV-HuBERT는 이 설정에서 현재의 최고 기술 수준의 접근 방식보다 20% 더 정확하며 성능이 더 뛰어납니다.
结论
현재 오디오만으로 언어를 인식하는데 많은 어려움이 있었습니다. 아무리 오디오를 정제한다 하더라도 주변 잡음이나 음성이 섞이게 되면 원하는 결과를 도출하기 힘들었습니다. 그러나 Meta가 공개한 AV-HuBERT은 이러한 문제들을 해결하는데 많은 가능성을 보여주었다고 생각됩니다. 멀티 모달이 가능한 환경에서 성능을 올리는 방법으로 AV-HuBERT를 활용한다면 새로운 음성 인식 도구를 만드는데 많은 도움을 줄 것이라고 기대합니다.
参考
https://ai.facebook.com/blog/ai-that-understands-speech-by-looking-as-well-as-hearing/






