
[생성지능개발팀 김성현]
인간은 세상을 학습할 때, 다양한 감각을 동시에 이용하며 학습합니다.
그리고 모든 감각은, 이를 감지하는 신경세포(neuron)의 발화(spike)로 변형되어 [1,0] 의 신호로 뇌로 전달됩니다.
예를 들어, 물체를 만지지 않았을 때는 세포의 발화가 생기지 않다가(0), 만지는 순간 발화가 일어나(1) 정보가 전달되는 것이죠.
마찬가지로, 빛이 있고(1) 없고(0) 에 따라, 특정 맛을 만들어내는 분자가 있고(1) 없고(0)에 따라, 특정 소리 헤르츠의 떨림이 감지되냐(1) 안되냐(0)에 따라 정보를 전달할 수 있습니다.
즉, 인간의 모든 정보처리는 이러한 통일된 “신경세포”에 의해 아날로그 신호를 데이터화해서 정보를 처리하게 됩니다.
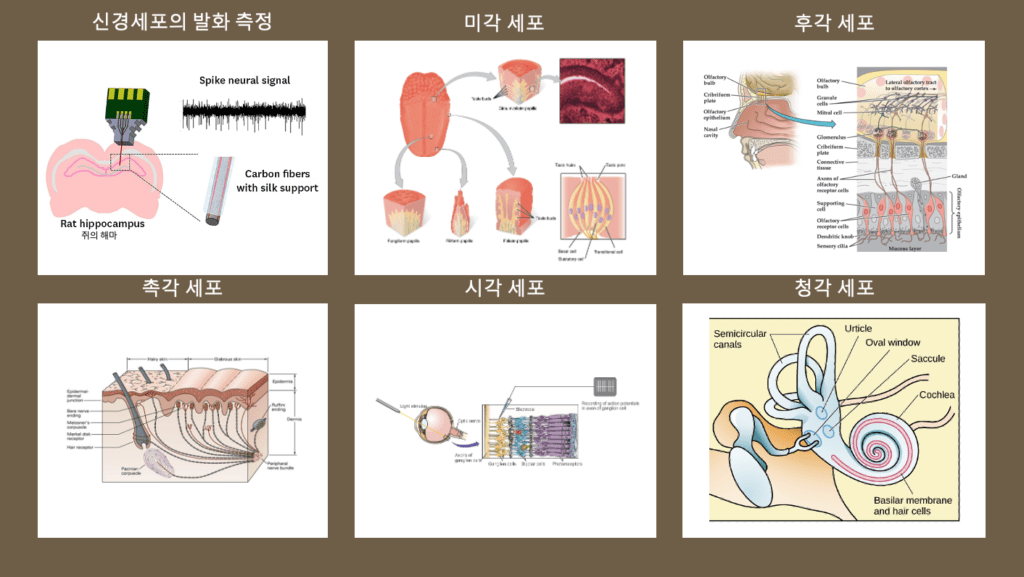
그렇다면, 인공지능 기술은 감각 정보를 어떻게 데이터화 할까요?
과거에는 각각의 감각 정보를 컴퓨터가 이해할 수 있도록 서로 다른 알고리즘으로 데이터화 시켰습니다.
예를 들어, 이미지는 [R,G,B] 픽셀 값을 3차원의 입력 데이터로 사용하거나, 이미지의 픽셀 비트를 낮춰서 palette를 만들었습니다.
음성 신호는 raw wave 신호를 mel spectrogram 등을 통해 변형시켜 데이터화 하였고,
자연어의 경우, vocabulary와 tokenizing 기법을 통해 데이터화 했었죠.
이처럼 새로운 감각 정보를 위해선 서로 다른 처리 방법을 적용해야 했었는데요,
그런데 최근 페이스북이었던 메타에서 data2vec이라는 새로운 알고리즘을 발표했습니다!
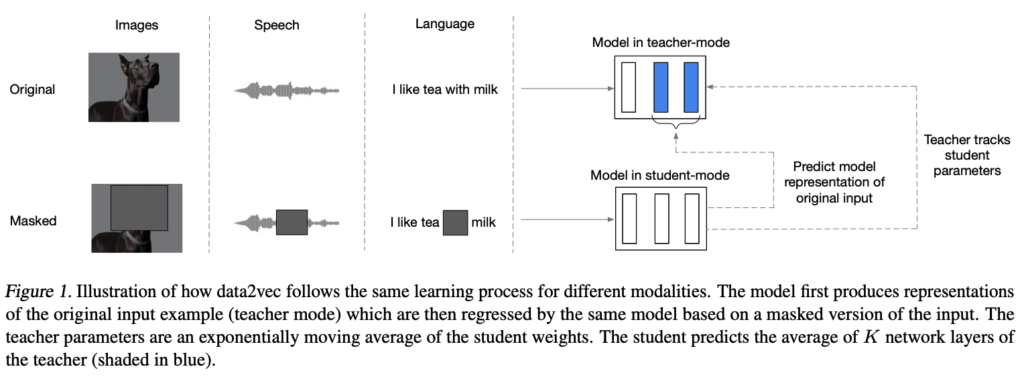
이 알고리즘은, 본래의 감각 정보(modality)를 처리하는 teacher mode와, 해당 modality에 mask 기법을 통해 노이즈를 삽입한 student mode로 분리할 수 있습니다.
Student mode는 masking된 본래의 정보를 추측하며 정보를 학습할 수 있습니다.
따라서 이 모델은, 이미지, 음성, 텍스트에 대해 동일한 방법으로 학습하게 됩니다.
이러한 학습 방법은 각 modality의 최신 모델들보다 나은 성능을 보여주었다고 합니다.
메타의 이번 발표는 좀 더 인간다운 정보 처리 방법을 제시했고, 각각의 modality를 독립된 대상으로 다루는 것이 아니라, 동일 알고리즘으로 동시에 처리가 가능함을 보인데 의의가 있다고 생각합니다 🙂
좀 더 자세한 article은 여기와, 해당 알고리즘의 논문은 여기서 확인하실 수 있습니다.






