
[가상인간연구팀 황준선]
NVIDIA NeMo는 간단한 Python 인터페이스를 사용하여 GPU 가속 음성 및 자연어 이해 모델을 구축, training 및 fine-tuning하기 위한 오픈소스 프레임워크입니다. NeMo를 활용하면 실시간 자동 음성 인식, 자연어 처리, 텍스트 음성 변환 등 애플리케이션용 모델을 구축할 수 있다고 합니다.
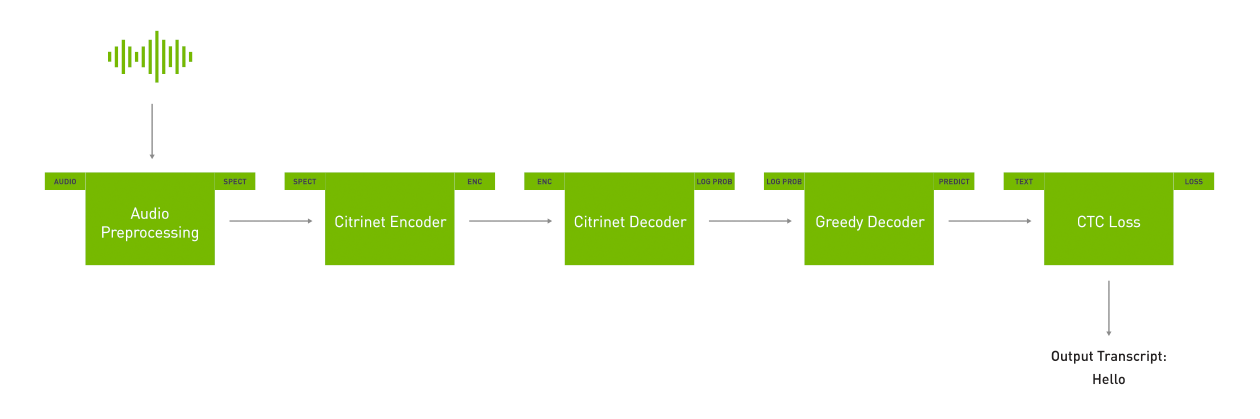
NeMo에는 ASR, NLP 및 TTS용 도메인 별로 여러 기능을 포함하며 Citrinet, Jasper, BERT, Fastpitch, HiFiGAN과 같은 최첨단 모델을 개발할 수 있습니다. NeMo는 Neural Module들로 구성되며, 이러한 모듈의 입력 및 출력은 모듈 간의 semantic check를 자동으로 수행합니다. 이를 다이어그램으로 표현하면 아래의 그림과 같으며 Hydra framework 기반으로 구성되어 있습니다.
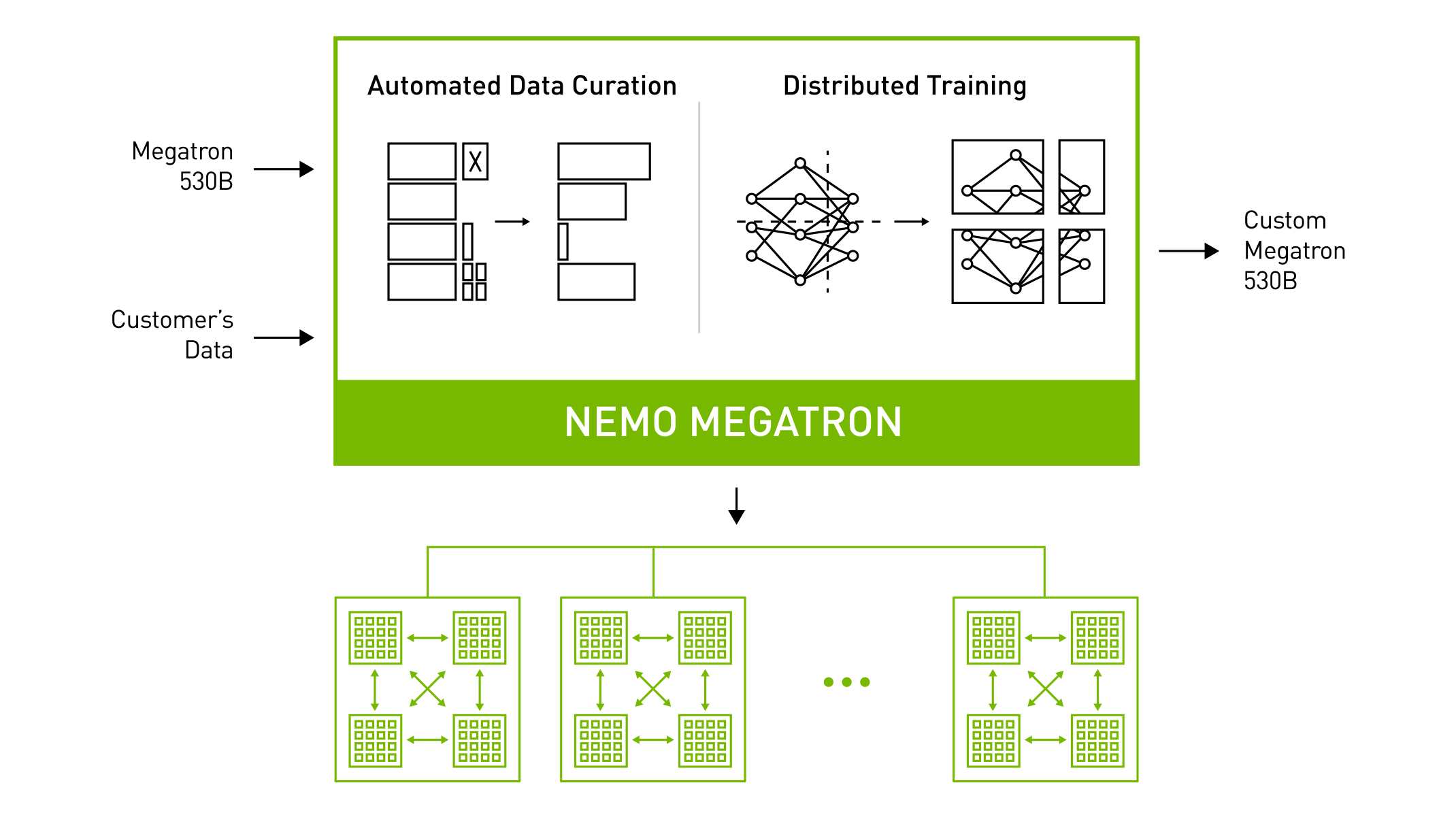
대규모의 Transformer 기반 언어 모델은 텍스트 생성, 요약 및 챗봇과 같은 광범위한 자연어 작업에 적용되고 있습니다. NeMo Megatron(530B)은 훈련 데이터에 대해 전처리 기능 수행 및 데이터를 선별하고 최대 수조 개의 파라미터를 가진 대규모 모델을 훈련할 수 있는 기능을 제공합니다. NeMo Megatron의 아키텍쳐는 아래 그림과 같으며, 현재 얼리억세스가 가능합니다.
마지막으로, NeMo의 공식 GitHub을 통해 간단한 튜토리얼을 제공하고 있습니다. 그 중에서, Audio Translation 튜토리얼이 쉽게 실행시킬 수 있고, 직접 들어볼 수도 있기 때문에 한번 실행시켜보는 것을 추천드립니다.
参考
[1] https://developer.nvidia.com/nvidia-nemo
[2] https://github.com/NVIDIA/NeMo
[3] https://github.com/facebookresearch/hydra






