
[생성지능개발팀 김성현]
우리는 한국어 문서를 볼 때, 그 대상을 의미를 가지는 단위로 쪼게서 이해할 수 있습니다.
예를 들어, “스마일게이트” 의 경우, “스마일” 과, 문을 의미하는 “게이트”로 이해할 수 있겠죠.
이렇게 자연어를 쪼게는 행위를 토크나이징 (tokenizing) 이라고 합니다.
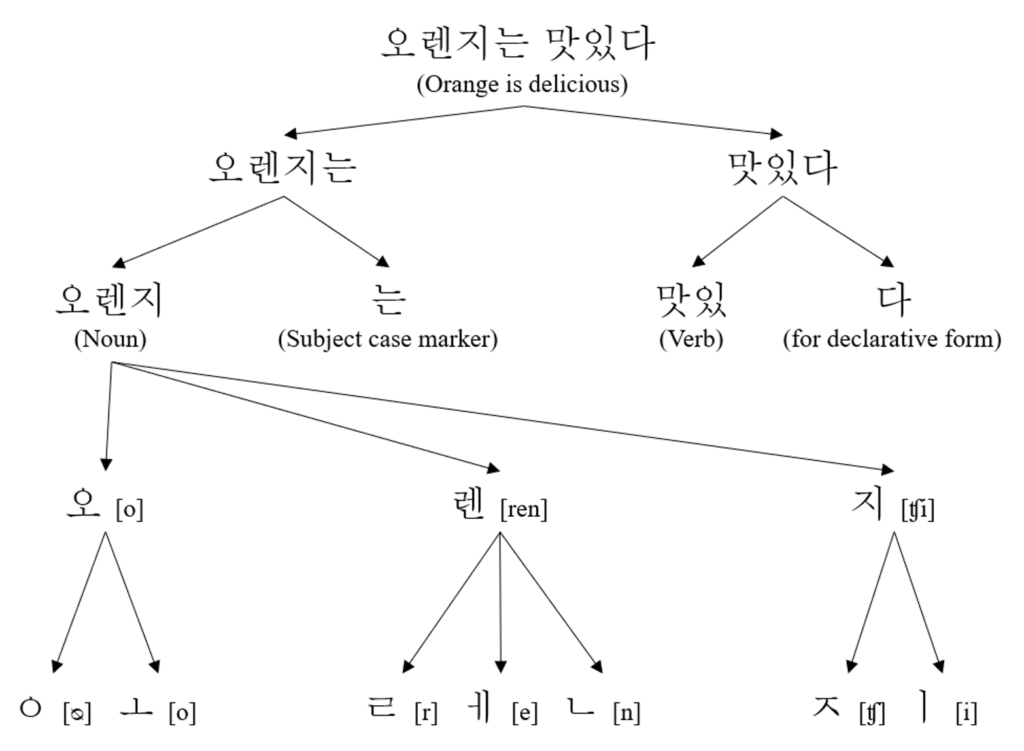
토크나이징의 다양한 단위들
가장 단순한 토크나이징 단위를 생각해본다면, 어절(띄어쓰기) 단위로 자르는 방법이 있을 것입니다.
이 경우, 영어와 같은 언어에서는 의미를 쪼게는데 꽤나 효과적으로 동작할 수 있습니다.
하지만 한국어는 조사나 어미를 붙여서 말을 만드는 교착어로, 띄어쓰기 만으로는 의미를 가지는 최소단위로 표현하기 어려워지죠.
예를 들어, 영어에서의 he/him 같은 단어가 어절 단위로 쪼겠을 때, 그 의미를 가지는 반면, 한국어에서는 ‘그’, ‘그가’, ‘그는’, ‘그를’, ‘그의’, ‘그에게’ 등과 같은 형태로, 더 세세하게 쪼게질 수 있습니다.
따라서 일반적으로, 한국어는 의미를 가지는 최소 단위인 형태소의 형태로 토크나이징을 수행합니다.
예를 들어, ‘안녕하세요’ 의 경우, [‘안녕’, ‘하’, ‘세’, ‘요’] 의 형태로 쪼게지는 것이죠.
반면에, 형태소보다 더 작은 단위인 음절 단위는 어떨까요?
[‘안’, ‘녕’, ‘하’, ‘세’, ‘요’] 를 관찰해볼 때, 오히려 원문의 의미가 파괴된 것을 볼 수 있습니다.
자소 단위로 쪼게는 경우인 [‘ㅇ’, ‘ㅏ’, ‘ㄴ’, ‘ㄴ’ … ‘ㅇ’, ‘ㅛ’] 도 비슷하죠.
물론, 이렇게 자소 단위의 토크나이징이 오탈자 임베딩에서 좋은 성능을 나타낸다는 연구 결과도 있습니다 (关联)
그래서 목적에 따라 토크나이징의 단위를 잘 고르는 것도 아주 중요하죠.
오늘 소개드릴 논문은, 이 토크나이징과 관련된 연구입니다. (연구 git 링크, 논문 링크)
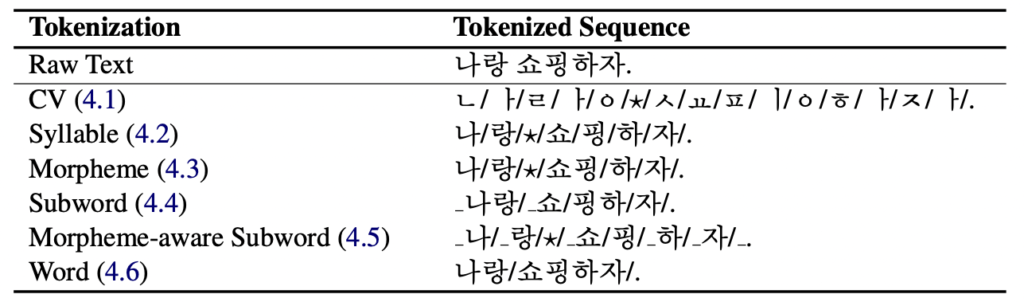
본 연구는 한국어 언어모델에서의 tokenizing 방식에 따른 성능 평가를 진행하였고, 그 단위는
(1) 자소, (2) 음절, (3) 형태소, (4) subword, (5) 형태소분석 + subword로 생성한 vocab을 이용해 Subword 기반 토크나이징, (6) 띄어쓰기 기반
으로 실험을 진행하였습니다.
결과는 어땠을까요?
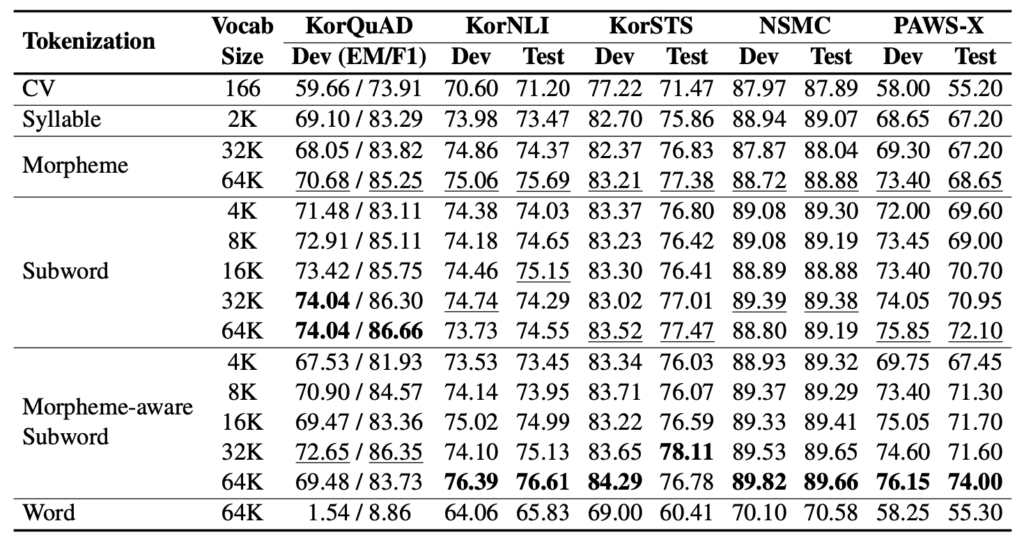
결과적으로는 morpheme-aware subword 방식이 한국어 자연어처리에서 가장 좋은 성능을 나타내주었습니다 🙂
이런 선행 연구들을 바탕으로, 언어모델 혹은 자연어처리를 진행할 때, 가장 적절한 한국어 토크나이저를 선택할 수 있을 것입니다.
최근에는 morpheme-aware bbpe (byte-level byte pair encoder)가 적용되는 연구도 있더라구요!






