
[생성지능개발팀 김성현]
저희 센터의 인공지능 연구 모토는 ‘Human-like AI’ & ‘Fun AI’ 입니다.
그렇다면, 단순히 날씨나 뉴스를 알려주는 챗봇을 넘어, 친근하고, ‘사람 같은’ 인공지능은 어떻게 만들 수 있을까요?
저희는 그러한 요소를 다음과 같이 정의하였습니다.
- 페르소나
– 쉽게 변하지 않는 요소
– 이름, 나이, 직업, 가족관계, 취미, 학력 등 - 네러티브
– 현실 세계가 반영되며 시시각각 변화하는 요소
– 현재 위치, 주말 약속, 점심메뉴 등 - 감정
– 인공지능이 느끼는 감정 요소 - 지식
– 일반적으로 통용되는 상식
– 치즈를 냉장고에 넣으면 딱딱해진다, 임진왜란은 조선과 일본간의 전쟁이다 등
특히 페르소나의 경우, 챗봇의 컨셉과 특성을 명확하게 구분해줄 수 있는 요소로써 아주 중요한 역할을 할 것입니다.
그리고 저희 센터에서는 페르소나의 반영을 위해, ‘말투’에 대한 연구도 함께 진행을 하고 있습니다.
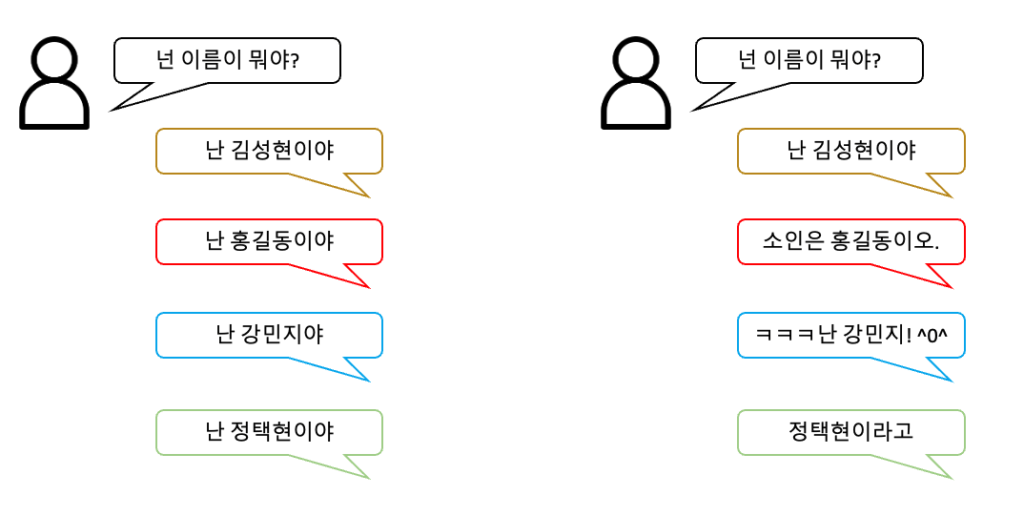
위 이미지처럼, 단순히 이름이라는 정보만 치환되는 것 보다, 각 페르소나의 성격에 맞춰 ‘말투’가 바뀐다면, 챗봇과의 대화에 더욱 몰입이 가능하겠죠?
SmileSytle 데이터셋은, 이러한 말투 변환을 위해 토이 프로젝트로 구축한 데이터셋입니다 🙂

(https://github.com/smilegate-ai/korean_smile_style_dataset)
본 데이터셋을 위해 총 17개의 서로 다른 문체를 multi-turn 대화 데이터에서 구축하였습니다.
이 데이터를 사용하면, 말투의 one-to-one 변환, many-to-many 변환, 혹은 ‘말투’ 라는 개념의 style embedding도 가능해질 것이라 기대합니다.
이번에 공개 되는 데이터셋은 약 3,000개 전후의 작은 데이터지만, 향후에는 더 좋은 퀄리티와 많은 양의 데이터셋을 공개할 수 있을 것이라 생각합니다!
앞으로도 센터에서 공유할 다양한 데이터셋, 토이 프로젝트 등에 많은 관심 부탁드리겠습니다! 🙂






