
[가상생명연구팀 김석겸]
(대표 이미지는 stable diffusion 을 통해 생성되었습니다.)
음성을 입력으로 받아서 텍스트 생성의 결과를 음성으로 받고 싶을 경우, 기존에는 음성을 텍스트로 바꾸는 모델(Speech To Text, STT), 텍스트를 처리하는 언어 모델(Language Model, LM), 텍스트 생성의 결과를 다시 음성으로 바꾸는 모델(Text To Speech, TTS) 을 순차적으로 통과해야 했습니다.
그런데 이번에 구글 리서치에서 발표한 AudioLM 은 그 모델 하나만으로 음성을 입력으로 받아 언어 모델링의 결과를 음성으로 출력해줄 수 있습니다.
잠시 강조해서 말해보자면 AudioLM 모델 하나로 모든 영역을 커버할 수는 없습니다. 다만 “AudioLM 하나로 끝”이라는 제목을 사용한 데에는 특정 영역에서 그만큼 성과가 좋기 때문입니다. (또한 관심 끌기용도 있습니다.)
먼저 생성 예제부터 한 번 확인해보겠습니다.
- 6초짜리 원래의 음성 데이터입니다.
- 입력으로 사용할 앞 부분부터 3초 음성(프롬프트)입니다.
- 프롬프트 영역을 입력 데이터로 주었을 때, AudioLM 의 출력값 중 하나입니다.
이 예시에서 세 가지를 확인할 수 있습니다.
- 3초의 입력 이후에 원래의 음성 데이터와 다른 내용이 나온다.
- 음성의 톤과 속도 등이 매끄럽게 연결된다.
- 출력값이 내용적으로도 적절하게 나온다.
AudioLM
AudioLM 은 장기적으로 일관성을 유지할 수 있는 고품질 오디오 생성 프레임워크입니다. AudioLM 은 입력 오디오를 분절된 토큰 시퀀스로 매핑하고 오디오 생성 과제를 임베딩 공간에서 언어 모델링 과제로 바꿔버립니다.
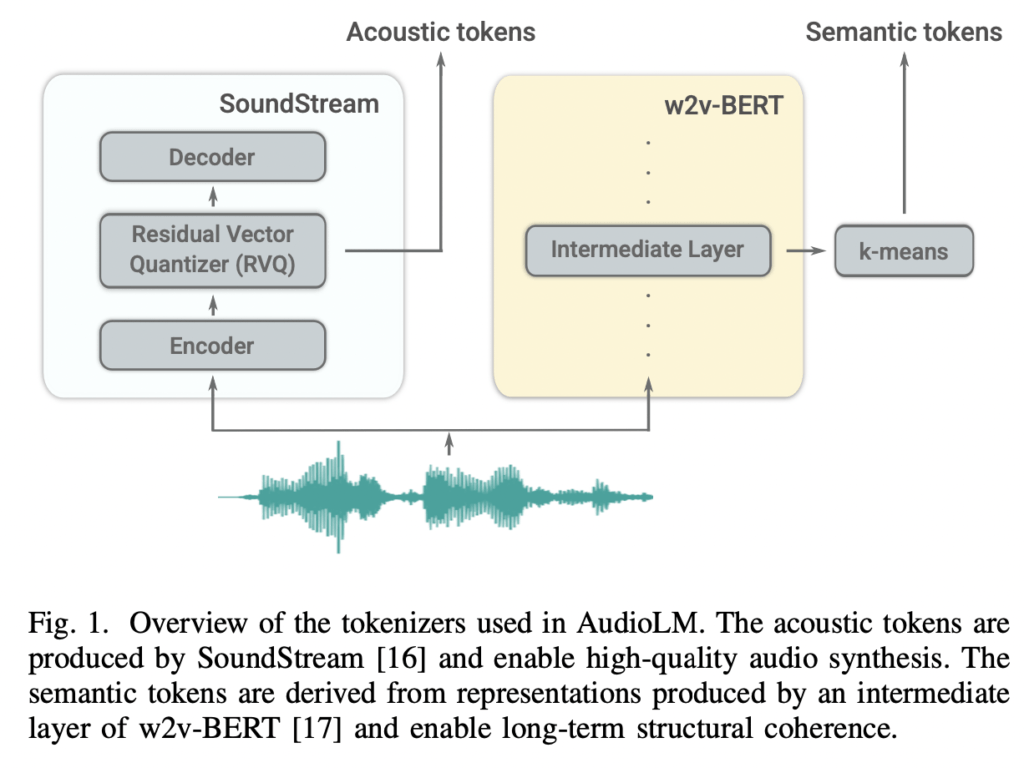
먼저 음성 특성과 언어적 특성 모두를 캐치하기 위해 하이브리드 토크나이징 체계를 사용합니다. 사전학습된 w2v-BERT 를 사용하여 semantic token 을 추출하고 SoundStream 을 이용해 acoustic token 을 추출하여 비교해 사용합니다. 이 둘은 음성을 구별할 수 있는 능력과 재구성 품질 측면에서 서로를 보완해줍니다.
w2v-BERT 는 거대한 speech corpora 데이터에서 자기 지도 방식으로 학습한 모델입니다. w2v-BERT 는 입력 오디오 파형을 언어적 특성의 풍부한 데이터셋으로 매핑해주는 역할을 합니다.
SoundStream 은 google ai에서 발표한 신경망을 활용한 오디오 코덱입니다. 기존 코덱은 압축의 효율성을 높이기 위해 신호 처리 전문가들이 도메인 지식을 활용하여 손수 설계하는 방식을 고집했다면 SoundStream 은 이 부분을 신경망으로 대체하면서도 실시간으로 작동할 수 있게 만든 코덱입니다.

AudioLM 은 Fig. 2에서 볼 수 있듯이, 3개의 하위 단계를 거쳐 수행됩니다. 모든 단계에서 분리된 디코더 모델을 사용합니다.
Semantic modeling 은 장기 구조적 일관성을 위해 semantic token 을 autoregressive 방식으로 예측하는 역할을 수행합니다.
Coarse acoustic modeling 은 semantic token 을 조건으로 acoustic token 만 예측합니다. soundstream 의 residual quantization 덕분에, acoustic token 은 위계 구조를 갖고 있습니다. 이는 화자의 아이덴티티, 녹음 조건 등 음향학적 특성을 커버할 수 있습니다.
Fine acoustic modeling 은 coarse acoustic modeling의 결과를 조건으로 오디오 품질을 향상시켜 두 번째 단계 이후에 남아 있는 손실 압축 잔여물을 제거합니다.
Datasets
Libri-Light 의 unlab-60k 학습 부분을 학습 데이터로 활용합니다. 이는 6만 시간의 영어 스피치로 이루어져 있습니다.
推理
AudioLM 은 아래 세 가지 방식으로 음성을 생성할 수 있습니다.
1. Unconditional generation
모든 semantic token에서 조건 없이 샘플링하여, acoustic modeling의 조건으로 사용합니다. 모델은 통사적, 의미적으로 일관성 있는 내용을 다양한 화자, 운율, 음성 조건에서 다양하게 만들어냅니다. 예시는 다음과 같습니다.
- 예시1
- 예시2
2. Acoustic generation
테스트 시퀀스에서 추출한 ground-truth semantic token 을 사용하여 acoustic token을 생성하는 방식입니다. 내용은 유지하되, 화자의 아이덴티티를 바꿀 때 사용합니다. 예시는 다음과 같습니다.
- 원래 데이터(1)
- 화자 변환 결과(1-a)
- 화자 변환 결과(1-b)
3. Generating continuations
AudioLM 저자의 주요 흥미 주제인 이어 만들기는 짧은 프롬프트로부터 이어지는 내용을 만드는 것입니다. 위에서 설명한 하위 3단계가 여기서 모두 쓰입니다. 이어 만들기는 처음 예시처럼 음성도 되지만 audio 데이터를 다루기 때문에 음악에서도 성공적으로 적용 가능합니다. 예시는 다음과 같습니다.
3-1. 음성 데이터
- 원래 데이터
- 프롬프트
- 생성 결과
3-2. 피아노 데이터
- 원래 데이터
- 프롬프트
- 생성 결과1: 잘 안되는 케이스도 있다.
- 생성 결과2: 잘 나온 경우
마무리
가상인간을 모델링하는 팀에서 일하다 보니 여러 모달리티를 다뤄야하는 경우가 생깁니다. 현재는 각 기능에 대해 분절된 모델로 각 프로세스를 맡고 있지만 AudioLM 처럼 몇 단계를 단축시킬 수 있는 모델이 나오면 예측 속도도 빨라지고 이어지는 측면에서 더 자연스러울 것입니다.
텍스트 데이터를 처리하는 데 있어서 전처리나 예외를 처리해줄 규칙 기반 처리도 중요하다고 생각하지만 sequence-to-sequence 로 모델링을 할 수 있는 과제에서는 이러한 방식이 적용될 만한 여지가 충분하다고 봅니다. 예를 들어, 번역도 가능하지 않을까 싶습니다. 현재 whisper가 음성 데이터를 입력으로 받으면 STT 뿐만 아니라 영어로 번역도 해주는데 이 기능에 다시 음성 데이터로 변환하는 기능만 넣는다면 음성으로 입력한 데이터를 번역하여 음성 데이터로 출력하는 것도 가능해보입니다.
参考
- https://google-research.github.io/seanet/audiolm/examples/
- https://arxiv.org/abs/2209.03143
- https://github.com/lucidrains/audiolm-pytorch
- https://engineering-ladder.tistory.com/90






