
[가상생명연구팀 박주형]
최근 강화학습에서 많이 주목 받고 있는 분야 중에 하나가 Offline 학습 입니다. 기존 강화학습은 시뮬레이터를 통해 실시간으로 trajectory를 받아서 학습을 했었어야 했는데요, 시뮬레이터 만들기도 쉽지 않고 실제 적용도 어려워서 로봇이나 자율 주행 쪽에서는 많이 시도 되는 방법 입니다. 이를 위해 게임 쪽에서는 다양한 유저들이 만들어 내는 로그를 통해서 offline reinforcement learning이나 imitation learning을 시도하기도 하는 데요, 유저 로그를 일반인이 구하기가 쉽지도 않고 로그가 많지 않으면 학습도 어려워서 여러모로 진입 장벽이 있는 방법 이었습니다.
이 때 게임으로 강화학습을 해 보신 분이라면 한번쯤은 떠올려 보셨을 듯한 아이디어가 있습니다. 인터넷에 게임영상이 그렇게나 많은데 해당 영상을 가지고 강화학습을 해 볼수는 없을까? 사실 강화학습을 하기 위해서는 observation 뿐만 아니라 action이 필요 한데요, 영상으로만 action을 계산한다는게 매우 힘들기 때문에 실제로는 적용하기 힘든 아이디어 중에 하나였습니다. 하지만 OpenAI에서는 Video PreTraining (VPT)라는 방법을 고안해 이 아이디어가 실현 가능한 아이디어라는 것을 보여 주었습니다.
Learning to Play Minecraft with Video PreTraining (VPT)
OpenAI는 인터넷 영상을 학습에 이용하기 위해 Video PreTraining (VPT) 라는 semi-supervised imitation learning 방법을 고안 하였습니다. 기본적인 아이디어는 매우 간단 합니다. 사람들에게 일정 시간동안 마인크래프트 게임을 시켜 observation 뿐만 아니라 action 값을 얻습니다. 이 데이터로 이미지만 들어오면 사용된 action을 예측할 수 있는 Inverse Dynamis Model (IDM)을 학습 시킵니다. 그렇게 된다면 인터넷 동영상에서 action을 충분히 유추 가능하기 때문에 인터넷 동영상을 behavior cloning 등에 얼마든지 활용 할 수 있게 됩니다.
여기서 또 하나의 중요한 점은 IDM이 action을 예측 하기 위해 과거 frame만 쓴게 아니라 미래 frame도 같이 사용 하였다는 점입니다. 이는 non-causal 형태의 학습이 가능하게 하였는데요, 이로 인해 단순히 과거의 frame만으로 현재의 action을 예상 하는 BC 같은 방식 보다 훨씬 적은 양의 데이터로도 예측이 가능하도록 학습 할 수 있었습니다.

70,000 시간의 영상으로 학습된 VPT Foundation Model 자체만으로도 강화학습으로는 이루어 낼 수 없는 엄청난 성능을 보여 줬습니다. 나무를 잘라서 통나무를 모으는 것 뿐만 아니라, 이를 사용하여 판자도 만들고 심지어는 테이블도 만들었습니다. 일반적인 강화학습에서는 이렇게 학습되기가 거의 불가능 한데요, 테이블을 만들기 위해서는 약 1000개의 action을 연속으로 해야 하는데, 확률적으로 이러한 일이 일어나기가 거의 불가능 하기 때문입니다.
추가로 저자는 BC의 성능을 고도화 하기 위해 fine-tuning도 테스트 해 보았습니다. 사람들에게 10분간 새로운 마인크래프트 월드에서 집을 짓도록 한 후 해당 데이터로 fine-tuning을 진행 하였습니다. 놀랍게도 fine-tuning된 모델은 기존 foundation model이 했던 행동을 더욱 잘할 뿐만 아니라 나무와 철로 된 곡괭이도 만들 수 있게 되었습니다.

Fine-Tuning with Reinforcement Learning
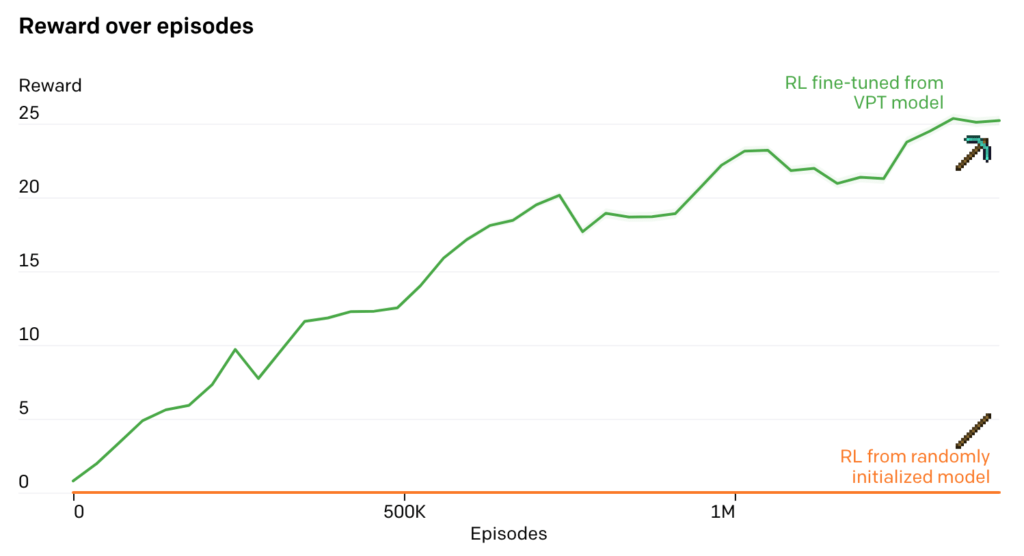
reward를 제공하는 강화학습 모델을 사용하면 아무래도 조금더 고도화된 작업을 할 수 있는데요, 그래서 저자는 마지막으로 fine-tuning된 모델에 강화학습 까지 적용을 시켜 최종적인 성능을 테스트 해 보았습니다. 생각해 보면 이는 딥마인드의 알파스타 학습 방식과 유사하다고 볼 수 있습니다. 유저들의 로그로 기본적인 빌드오더 및 행동양상을 학습한 다음 강화학습을 적용하여 인간보다 잘 플레이 하는 알파스타를 학습 시켰었습니다. 마인크래프트에서는 제작 난이도가 매우 높은 다이아몬드 곡괭이를 강화학습으로 학습 시켰는데요, 아래 그림에서 보듯이 대략 24000개 이상의 행동이 필요하고 시간도 20분 이상 걸린다고 합니다. 학습을 위해 다이아몬드 곡괭이를 만들기 위한 재료들이 완성될때 마다 reward를 제공 하였습니다.
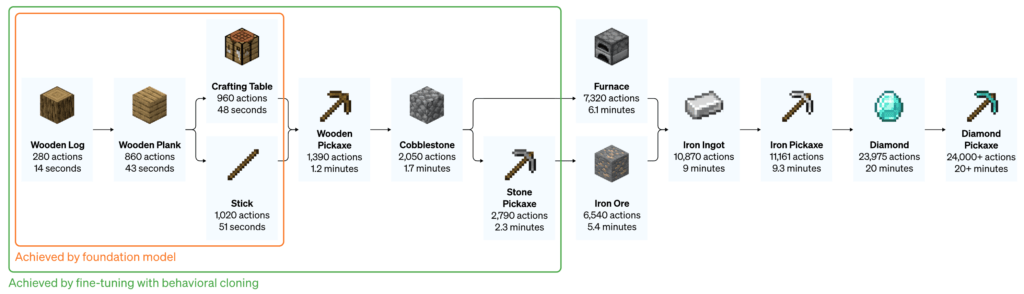
강화학습으로 fine-tuning 된 VPT model은 다이아몬드 곡괭이를 만들기 시작했을 뿐만 아니라 곡괭이를 만들기 위한 재료들을 만들 때도 인간과 비슷한 성공률을 보였다고 합니다. 이는 마인크래프트에서 처음으로 다이아몬드 곡괭이 만들기에 성공한 agent라고 하네요.
结论
이상으로 OpenAI에서 개발한 Video PreTraining (VPT)으로 마인크래프트 학습하기에 대해 알아 보았습니다. 게임 영상을 강화학습에 사용하는 방법을 제안 하였고, 성능 또한 기존 강화학습에서는 보여줄 수 없는 퍼포먼스를 보여줬기에 확실히 눈에 띄는 성과라 할 수 있겠습니다. 다만 제가 보기에 몇가지 한계점도 보였는데요, 대부분의 행동 성공율 그래프가 log 그래프로 되어 있는데, 실제 성공률이나 제작 횟수를 확인해 보면 그렇게 값이 높아 보이진 않아서 효과적이라고 보기에는 힘들꺼 같습니다. 또한 input으로 이미지를 사용했는데요, 대부분의 게임용 강화학습에서는 image는 노이즈도 많고 정보가 너무 방대하기에 사용하지 않고, 게임 정보를 표현해 주는 scalar 값이나 미니맵 형태의 vector 값을 사용 합니다. 이렇게 이미지를 사용하지 않고 학습된 경우 아무리 게임 동영상이 많더라도 이를 feature로 변환하기는 힘드므로 활용성이 다소 떨어 진다고 볼 수도 있겠습니다. 그럼에도 불구하고 게임 영상을 통해 복잡한 마인크래프트를 학습시켰다는 점에서는 매우 큰 의미가 있는 논문이라 생각됩니다. 이 논문을 바탕으로 강화학습에 다양한 영상 활용 방법이 나오길 기대 합니다.






