
[생성지능개발팀 정재철]
최근 이미지 생성 모델은 생성물의 수준이 많이 올라감과 동시에 text to image라는 방식이 제안 되면서 사용 난이도도 감소하여 많은 주목을 받았습니다. 이후 현재는 다양한 AI 그림 생성, 공유, 모델 공유 서비스 등이 생겨나면서 학술의 영역에 일반인이 사용할 수 있는 형태로 드러나고 있습니다. 그와 동시에 학술 영역은 물론 기존의 text to image의 연구도 진행되지만 text to 3D라는 새로운 영역이 주목 받고 있습니다. 그래서 이 포스트에서는 간략하게 3D data의 종류와 text to 3D 분야가 탄생하기까지 과정을 설명 드리려고 합니다.
3D data 종류
3D 데이터는 이미지와 같이 표현할 수 있는 방법이 여러가지가 존재합니다. 대표적으로 Voxel, Polygon, Point cloud가 있으며, 게임, 영화 등의 산업에 주로 사용하는 대부분의 3D data의 형태는 Polygon 입니다. 각각의 3D data에 대해서 구체적으로 설명하면, 우선 Voxel은 Volume과 Pixel의 합성어로 부피를 가진 픽셀이라는 의미 입니다. 아래 그림과 같이 2d pixel 이미지와 비슷하게 3D 공간에 Voxel을 배치하는 방식으로 표현하는 데이터 입니다. 단순히 Voxel의 크기를 작게 만들고 표현에 사용하는 개수를 늘리면 좋은 그래픽을 구현할 수 있다는 장점이 있지만, 개수를 늘리면 기하급수적으로 필요한 연산량이 늘어난다는 치명적인 단점이 있어서 주류로 사용되는 데이터 형태는 아닙니다. 하지만 변형하기 쉽고, 다른 3D data 표현 방식으로 나타내기 어려운 형태를 구현할 수 있기 때문에(이론적으로 개수를 늘리면 거의 모든 형태를 정교하게 표현 가능) 다른 3D data 표현 방식과 혼용하는 등의 기술 적용 시도가 계속되고 있습니다.
Polygon은 3D를 주로 사용하는 게임/영화 등의 여러 산업 분야에서 사용되는 주류의 3D data 표현 방식입니다. 이름 그대로 다각형의 면의 조합으로 3D data를 정의하며 이를 위해서 Vertex(3D 공간 상의 좌표), Edges(vertex를 연결한 선), Faces(선들을 3개 이상 연결하여 만들어진 면) 정보가 필요한데, 보통 Vertex 정보를 기반으로 Vertex 정렬 순서를 이용해서 Edges, Faces 정보를 코드 기반으로 효율적으로 정의하기 때문에 효율적 입니다. 초기 Polygon은 아래 그림과 같이 각진 형태를 띄기 때문에 Voxel에 비해서 비교적으로 부자연스러워 보인다는 단점이 있었지만, 그래픽 성능 증가로 많은 수의 Polygon을 사용하여 곡면을 근사 표현하는 방식으로 극복할 수 있게 되어 점점 주류의 3D data 표현 방식이 되었습니다. Polygon으로 구성된 물체를 mesh라고 하며 mesh의 표면에 그림을 입히면, 게임 / 영화 등의 매체에 사용되는 그래픽 결과의 형상을 띄게 됩니다. 이 때 표면에 입히는 그림을 texture라고 합니다. mesh를 이용하여 애니메이션을 제작하는 경우 내부에 뼈대를 넣고 뼈대의 움직임에 따라서 Polygon이 따라 움직이도록 하는 작업을 Rigging이라고 하며, 그런 3D mesh의 움직임을 2D 화면으로 만드는 단계를 Rendering 이라고 합니다.

Point cloud는 앞서 설명한 Voxel, Polygon과 달리 순수한 3D data에 가까운 표현 방식입니다. 일종의 x, y, z 좌표계에서 Vertex(3D 공간 상의 좌표)의 집합으로 보통 Lidar 센서, RGB-D 센서 등으로 수집되는 raw data가 이러한 형태로 표현됩니다. 이렇게 측정 된 Point cloud는 아래 그림과 같이 표현되는데, 각 point 사이의 관계, 표현되는 물체의 기하학 적인 특성을 알 수 없고, Sparse 하기 때문에 단독으로 사용되지 않고 같은 시점의 이미지 등의 다른 data와 같이 사용되는 경우가 많습니다.

3D Generative AI trend 변화
기존의 vision 분야 Generative model 연구는 대부분 2D pixel space 위에서 연구되어 왔습니다. 그렇기 때문에 연구 결과를 image editting 혹은 view synthesis 같은 분야의 application에 적용하는 것은 제한적이었습니다. 예를 들면 2D pixel space에서 훈련된 GAN 모델에서 feature를 제어해서 출력의 pose 혹은 view를 변경하게 되면 훈련 데이터의 pose, view와 멀어질 수록 quality가 떨어지거나 identity가 변질된 결과가 나오게 됩니다. 이러한 한계를 극복하기 위해 연구되는 분야가 3d aware image synthesis 입니다.
초기의 3d aware image synthesis 연구는 2d 이미지를 3d 형태로 representation 하고 그렇게 만들어진 3d data를 기반으로 생성하는 방식으로 진행되어 왔습니다. 3d representation 방식은 Depth map, voxel grid, implicit surface, point cloud, mesh의 5가지 방식으로 나타냈습니다. Depth map은 입력 이미지의 각 pixel 까지 거리 값을 구하는 것을 의미하고, implicit surface는 각 pixel의 면이 가리키는 방향을 3d vector로 표현하는 방식입니다. 예시는 Depth map, implicit surface 순서로 아래 그림과 같습니다. Depth map의 경우 값의 크기가 커질 수록 어두운 색에서 밝은 색으로 표현되었고, implicit surface는 각 pixel의 표면 vector를 Normal mapping(대략적으로 천장 방향은 파란색 계열, 오른쪽으로 틀어진 대각선 방향은 빨간색 계열, 왼쪽으로 틀어진 대각 방향은 녹색 계열) 하여 색상으로 표현 했습니다.

하지만, 위와 같은 형태로 representation 된 3d는 입력 2d 이미지에서 가려진 부분 값이 나오지 않기 때문에 2.5d 수준에 더 가까운 한계가 있습니다. voxel grid, point cloud 방식 각각 아래 그림과 같이 표현 될 수 있습니다. 하지만 둘 모두 detail 표현이 어렵기 때문에(voxel은 high resolution 적용 시 많은 하드웨어 자원이 필요하며, point cloud는 sparse 하여 detail 정보 부족), 3d 표현에 한계가 있습니다.

mesh는 위 단점들에 모두 해당되지는 않지만, data 구조 특성 상 순서 정보가 중요하여 병렬 처리에 특화된 nerual net이 수행하기에 적합하지 않은 형태 입니다. 또한 voxel grid, point cloud, mesh 방식은 훈련 data가 많지 않기 때문에 학습 데이터에 없는 현실의 사용 환경에 맞도록 개선하는 것이 어렵습니다.
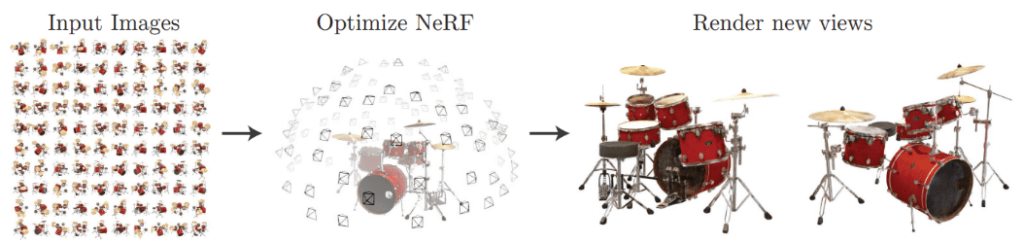
위 초기 연구 이후 2020년에 NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis 논문이 공개 되면서 3d aware image synthesis 분야의 한계를 한 단계 뛰어넘게 됩니다. NeRF는 아래 그림과 같이 물체의 사진을 여러 view로 촬영하여 넣으면, 입력된 view 사이의 없던 view의 새로운 이미지를 생성합니다. 즉 소수의 여러 view의 2d 이미지가 있다면, Depth map, voxel grid, implicit surface, point cloud, mesh 등의 representation 과정을 생략하고 바로 원하는 view의 2d image를 높은 quality로 만들 수 있다는 의미입니다.
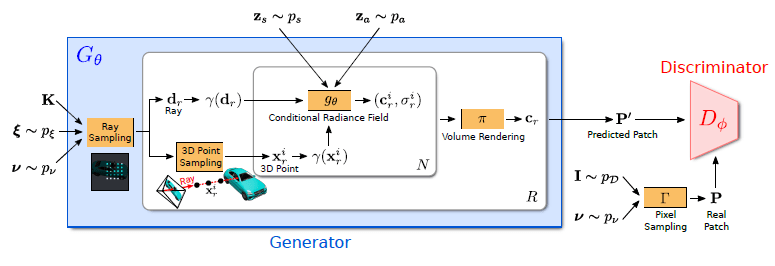
이후 전통적인 2D pixel space에서 훈련된 GAN 모델에 NeRF를 적용하는 연구 GRAF(GRAF: Generative Radiance Fields for 3D-Aware Image Synthesis, NIPS2020)를 시작으로 여러 아이디어들이 구현되기 시작했습니다. 구체적인 구현은 아래와 같은데 object에 대한 1개의 2d data(camera matrix K, camera pose ξ, 2D sampling pattern ν 및 형상)와 shape/appearance code zs, za 를 입력 받아 다른 view의 이미지를 예측하게 됩니다.
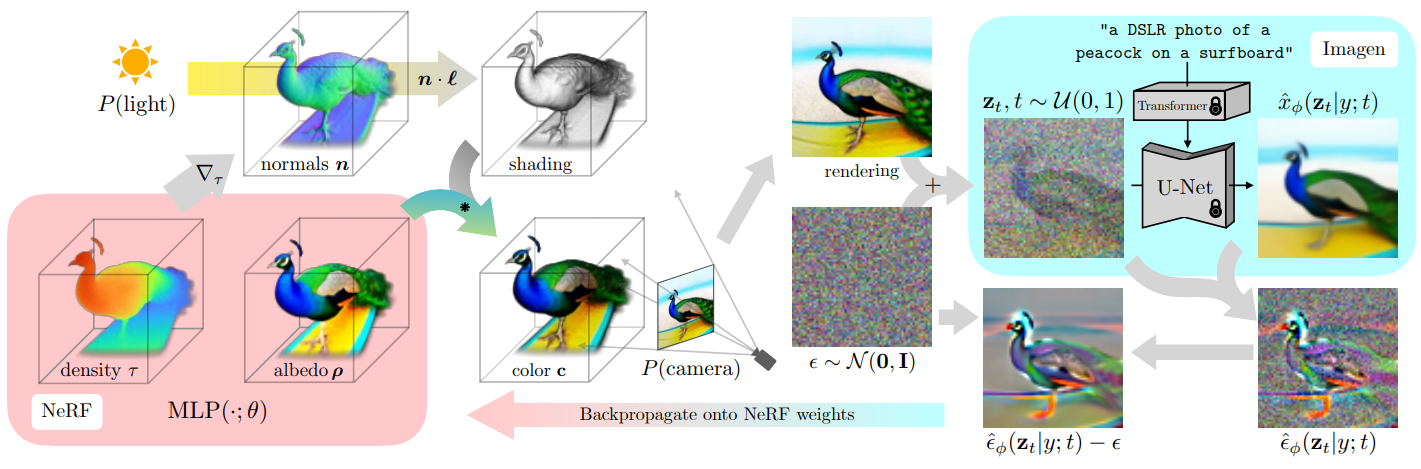
이후 NeRF와 GAN이 지속적으로 개선되면서 3D aware GAN도 같이 개선되었습니다. 하지만 GAN의 자리를 diffusion model이 대체하고, text encoder와 diffusion을 결합하여 text to image를 구현 모델들이 이미지 생성 모델 분야의 최고가 되면서 이러한 기술들을 3d aware image synthesis 에 적용하려는 시도가 생겨나게 되었습니다. 가장 처음으로 시도한 것이 바로 DreamFusion(DreamFusion: Text-to-3D using 2D Diffusion) 입니다. 구체적인 구현은 아래 그림과 같습니다. 구체적으로 NeRF model의 weight를 초기화 후 text to image model에 text 입력을 통해서 3D로 생성하고 싶은 object의 이미지를 출력합니다. 출력 된 이미지는 NeRF모델을 통해 multi view를 생성하고 다시 특정 view를 rendering을 합니다. rendering된 이미지에 앞서 사용한 text to image model의 t 시점의 noise를 추가하고 t 시점의 object 이미지 forward process 결과가 근사하도록 NeRF model 업데이트 합니다. 이 과정을 반복하면서 NeRF model을 업데이트 하면 text to image model로 생성한 object의 multi view를 만들 수 있도록 학습되게 됩니다.
앞으로의 전망
text to 3D model이 이미 제시되었고 최초의 연구를 개선한 다른 연구들이 나오고 있기 때문에 가까운 미래에 text to image 분야의 stable diffusion과 같은 역할을 하는 결과물이 나올 것으로 보여집니다. 만약 그렇게 된다면 stable diffusion으로 인해서 생긴 변화보다 더 큰 변화가 있을 것입니다.






