
[생성AI서비스팀 정재철]
세계 3대 컴퓨터 비전 학회 중 하나인 ICCV 2023(International Conference on Computer Vision, 국제 컴퓨터 비전 학회)이 10월 2일 부터 6일 까지 프랑스 파리에서 개최되었습니다. 이번 ICCV 2023을 참관하고 느낀 점을 공유하려고 합니다. 세계 각국의 컴퓨터 비전 분야 연구자들의 연구와 관련 기술 연구를 진행한 기업들의 기술 데모들을 보면서 기술 트렌드를 느끼고 영감을 얻을 수 있는 좋은 기회 였습니다.
ICCV 2023
먼저 ICCV 2023에 대해서 간단하게 말씀드리자면, ECCV(European Conference on Computer Vision, 유럽 컴퓨터 비전 학회), CVPR(Computer Vision and Pattern Recognition Conference, 컴퓨터 비전 및 패턴 인식 학회)과 더불어 컴퓨터 비전 분야의 3대 학회로 인정받고 있습니다. CVPR의 경우 매년 열리지만 ICCV, ECCV는 2년에 한번 개최되며, 매년 번갈아서 개최된다는 특징이 있습니다. 올해 ICCV 2023이 개최되었으니 내년에는 ECCV 2024가 개최되는 형태입니다. 참가 방식은 코로나 이후로 오프라인 / 온라인 2가지 형태로 가능해졌으며, 오프라인 참가 신청을 한 경우 온라인 참가 역시 지원합니다.
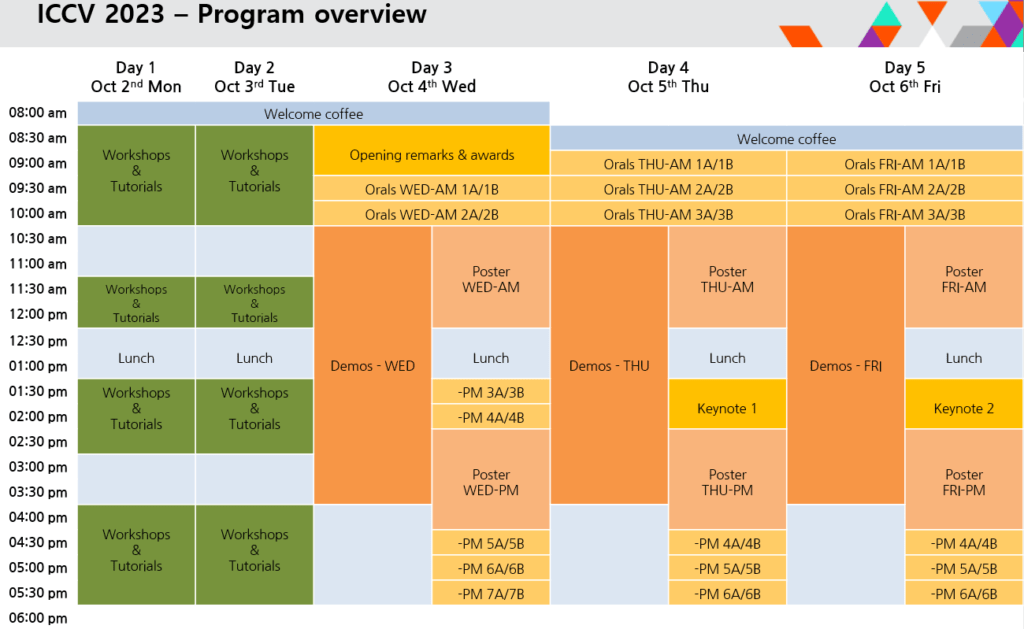
일정은 위 표와 같이 10/2~3일 간 Workshop / Tutorials 이 진행 되었고 이후 10/4~6까지 3일 간 main conference가 진행되었습니다. main conference는 opening 및 우수 논문에 대한 시상식 이후 Oral 발표와 Poster 발표로 진행되었고, 논문 저자 혹은 참여 기업의 tech demo가 전시되어 있어 방문하여 구경 할 수 있었습니다. Workshop / Tutorials의 경우 동시 진행들이 많았기 때문에 어떤 주제들로 진행되었는지 간략하게 말씀드리고, 제가 관심을 가지고 직접 들은 것들 위주로 소개하려고 합니다. 또 main conference 기간 중 10/5, 10/6일에 keynote 발표가 있었는데 비행기 일정 때문에 10/6일 점심 이후 일정이 불가능하여 keynote 2와 이후의 Oral 및 Poster 발표의 경우 듣지 못했습니다.
Workshop
Workshop / Tutorials 일정의 경우 많은 주제에 대해서 동시에 진행되었기 때문에 선택과 집중을 통해서 일부만 직접 참관했습니다. 이번 학회 일정은 연구보다는 최신 기술 트렌드 파악 및 인적 네트워크 형성이 목적이기 때문에 Tutorials은 제외하고 Workshop 위주로 진행 했습니다. Workshop의 경우 다양한 주제로 진행되었는데, 주류의 주제는 Video 생성, Vision-language, Robot/Self-driving, 3D/VR/AR이였습니다. 비주류의 주제들은 Quantization, Vision Transformers, Computer Vision Multimodal, out of distribution 등의 다양한 것들이 있었습니다. 주류와 비주류 주제의 차이는 비슷한 주제의 Workshop이 여럿 있는지 혹은 1, 2개의 Workshop만 관련 주제로 진행 되는 지의 차이로 이해하시면 될 것 같습니다. 주류의 주제들은 컴퓨터 비전 혹은 다른 분야의 기술과 융합되어 특화된 실제 상황에 적용되는 것을 가정한 것이라는 공통점이 있었습니다. 또한 비주류 주류 가릴 것 없이 거의 모든 주제들은 학문적인 정답이 모호한 목표 보다는 특정 목적에 맞는 모델을 연구하는 방식이 대부분 이였습니다. 이러한 경향을 볼 때 computer vision 분야의 인공지능의 경우 범용 인공지능을 목표로 하기 보다는 바로 적용해서 도움이 될 수 있는 단일 task에 특화된 형태를 목표로 한다는 느낌을 받았습니다.
이런 주제들로 진행된 workshop 중에서 제가 관심을 가지 본 것들은 아래 2가지가 있었습니다.
- Look Dave, I can see you’re really upset about this. HAL9000 computer: A Workshop on Emotionally and Culturally Intelligent AI
- Vision-and-Language Algorithmic Reasoning Workshop
우선 첫 번째 Workshop은 특이한 제목이 눈에 띄어서 듣는 것을 결정했는데, 상당히 흥미로운 주제로 진행되었습니다. 이 Workshop은 Vision-language를 설명 가능한 AI 기반으로 개발하는 방법론에 대해서 진행되었는데, 이를 위해서 감정을 이해하도록 개발해야 한다고 결론을 내렸고, 이를 위해서 감정을 데이터화 하는 과정에 대해서 논의 했습니다. 특히 기존의 인공지능 개발 과정에서 편향된 정보로 인해서 문제가 생겼던 것들을 예시로 보여주면서, 이를 회피하기 위해서 거의 모든 주류 문화권의 감정 / 음성 데이터를 모아야 한다는 것을 증명하는 것은 상당히 인상적이었습니다.

두 번째로 들은 Workshop도 앞선 것과 마찬가지로 Vision-language 관련된 것으로 이미지를 넘어서 비디오를 언어로 설명하는 모델을 만드는 것이 주제였습니다. 이 Workshop에서 소개되는 연구들 중에서 비디오를 자연어 기반으로 이해하기 위한 연구가 특히 인상적 이였는데, 정지 이미지와 비디오의 언어 관점의 차이점을 상호작용이라고 정의하고, 이에 맞추어서 상황을 크게 물체, 사람 사이의 3가지 상호작용으로 분류하여 비디오 / 언어 데이터 세트를 만드는 과정은 상당히 흥미로웠습니다.
Main conference
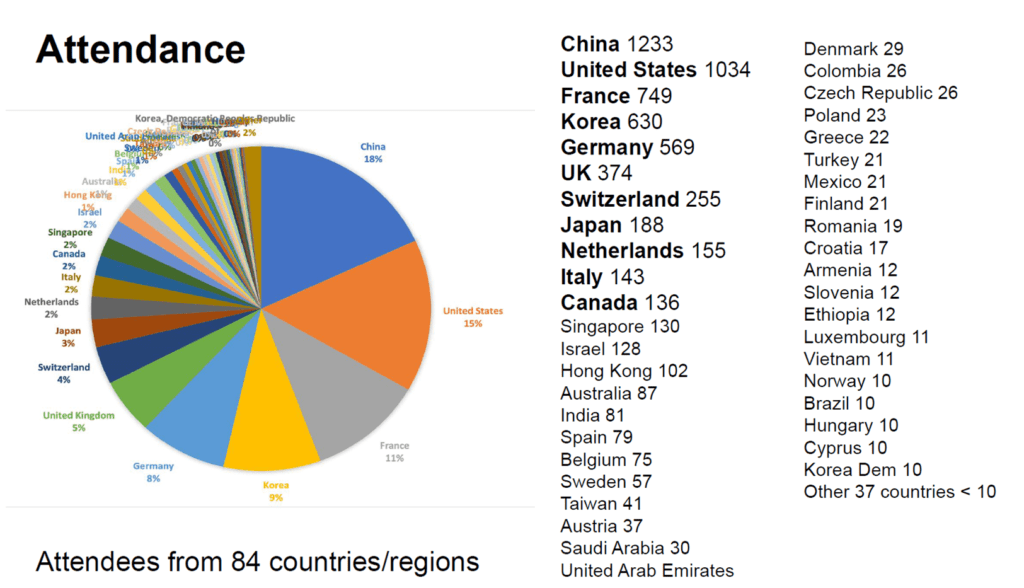
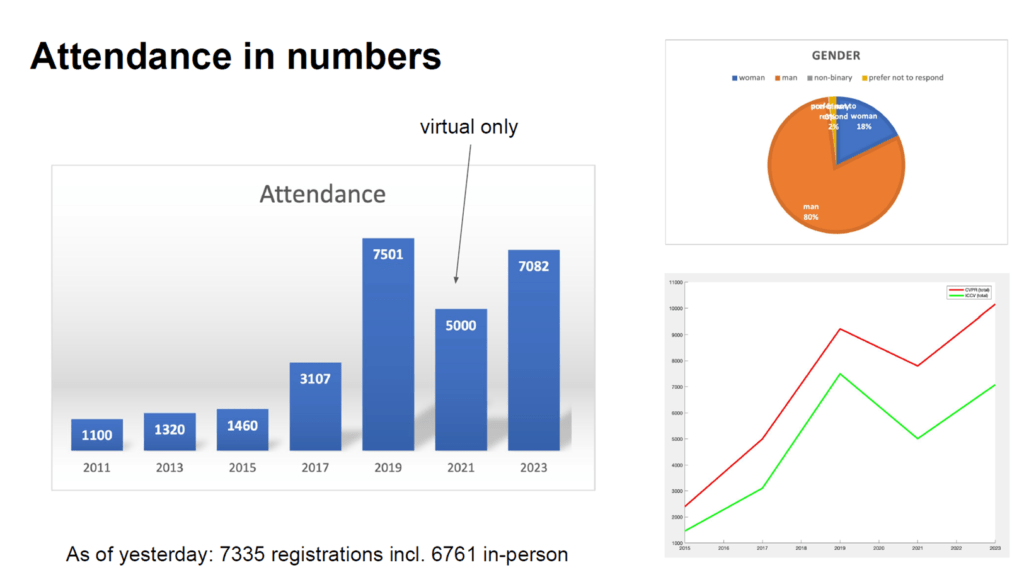
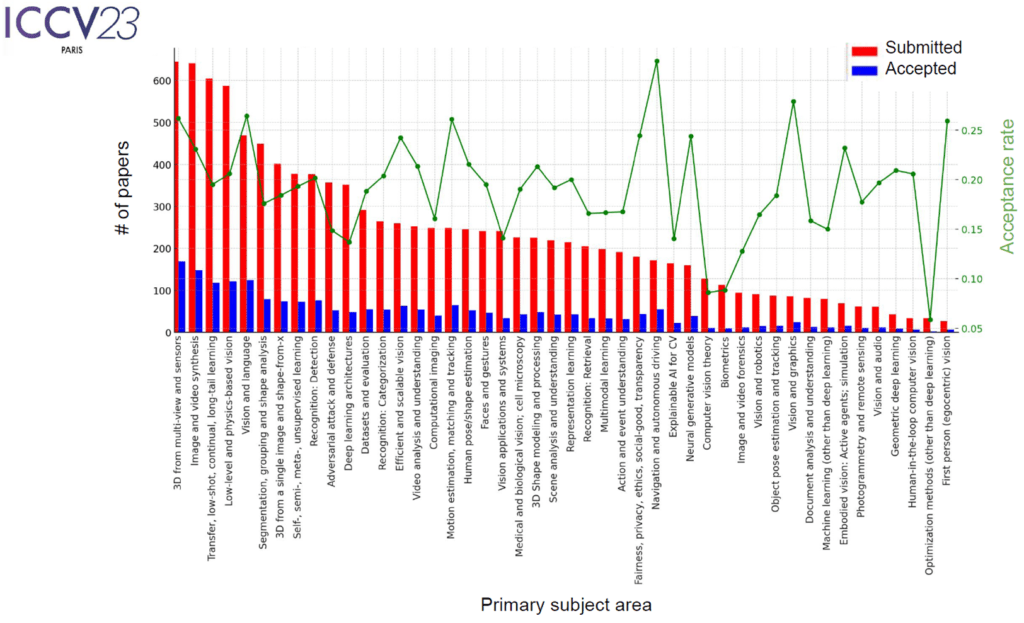
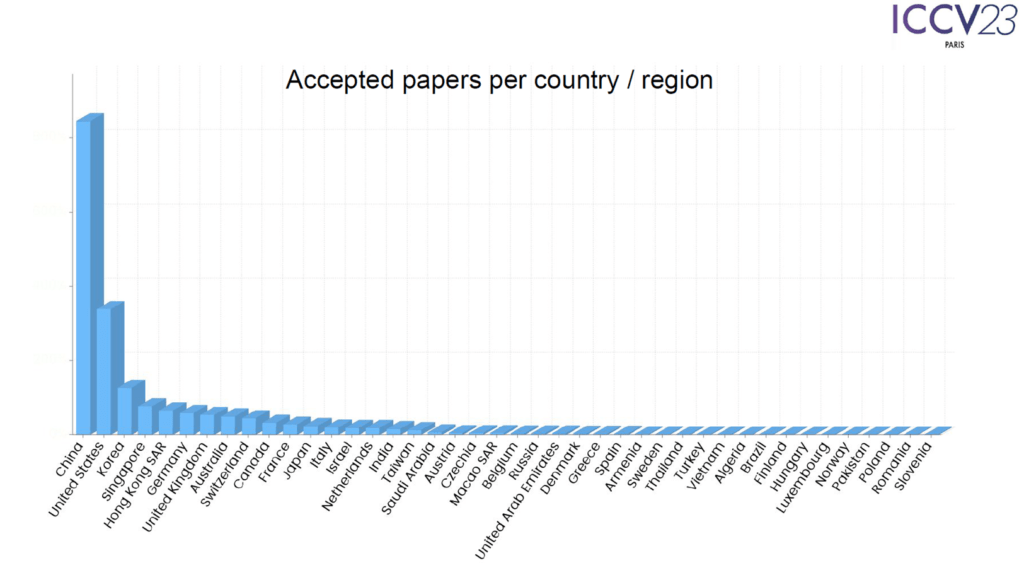
학회의 시작은 오프닝과 논문 시상식으로 시작되었습니다. 오프닝의 경우 참가자 현황과 어떤 주제로 많이 제출되는지 그리고 그 중 얼마나 게재 되었는지 등의 학회 운영 현황에 대해서 이야기하는 과정이었습니다.
위 통계 자료는 공개된 ICCV 2023의 Opening 발표 자료를 가져온 것으로 주요 내용을 요약하면 아래와 같습니다.
- 논문 제출이 많은 국가 순서는 (1. 중국, 2. 미국, 3. 프랑스, 4. 한국, 5. 독일, 6. 영국, ….) 순서
- 2021년 코로나 사태 이후 온라인으로 진행되어서 참가자가 줄었지만 회복세를 보이고 있다
- 제출 대비 게재 비율은 25%에서 30%
- 가장 많은 제출이 있었던 주제는 (1. 3D, 2. Image / Video generation, 3. camera senso, 4. vision-language, …) 순서
Paper Awards
이후에는 수상 논문을 4개 발표했는데 주제 별로 Best Student Paper 1개, Best Paper Honorable Mention 1개, Best Paper (Marr Prize) 2개 의 논문이 해당되었습니다.
Best Student Paper에 해당되는 논문은 “Tracking Everything Everywhere All At once”로 optical flow 혹은 particle video tracking 알고리즘이 occlusion 이후 tracking이 잘 안되는 문제에 대한 해답을 제시하는 논문이었습니다.

Best Paper Honorable Mention은 Meta의 “Segment Anything”이 수상했는데 vision-language model을 활용하여 image segmentaion 분야에 한 획을 그었기 때문에 수상이 놀랍지는 않았습니다.

Best Paper (Marr Prize)의 경우 2개 논문이 수상했는데, “Passive Ultra-Wideband Single-Photon Imaging”, “Adding Conditional Control to Tex-to-Image Diffusion Model” 두 가지 입니다. 앞의 논문의 경우 발표를 들어보면, 센서 하드웨어 분야의 연구로 보여지는데 딥 러닝이 컴퓨터 비전 분야에 쓰이기 시작한 이후에도 꾸준하게 관련 분야가 연구되어 왔음을 실감할 수 있었습니다. 후자의 경우는 diffusion 생성 model을 이미지 기반으로 제어하는 것에 대한 연구로 유명한 ControlNet 입니다. 이 역시 파급 효과를 생각했을 때 놀랍지는 않았습니다. 이를 시작으로 비슷한 주제의 간소화된 버전으로 볼 수 있는 T2I-Adapter, 비슷한 사용 방식으로 image 기반으로 prompt를 추출하여 생성 과정에 적용하는 형태의 IP-Adapter 등으로 diffusion model의 생성 과정에 인간이 용이하게 개입할 수 있는 방법들에 대한 연구들이 진행되었기 때문에 충분히 납득 가능한 선택이었습니다.

Keynote: Interactive Learning in the Era of Large Models

Keynote는 로봇과 인간이 비전 기반으로 상호작용하는 AI를 만드는 과정을 설명하는 내용이었습니다. 주로 다룬 내용은 로봇이 비전 기반으로 인간과 상호작용이 가능하도록 학습하려면 일반적인 Vision-language 학습 데이터 기반으로는 안되고 언어적인 표현에 수정이 필요하다는 것, 로봇 시스템을 위한 model의 base가 되는 LLM(Large Language Model)의 역할, 등 실제로 개발 과정을 동영상 등의 시각 자료를 활용하면서 예시를 보여주며 설명했기 때문에 재미있게 들을 수 있었습니다.
마치며…
ICCV 2023 참관 이후 생각해봤을 때 컴퓨터 비전은 한동안 Diffusion 기반의 생성 모델 파생 연구들이 계속 지배하게 될 것으로 보여집니다. 하지만 변화가 없었던 것은 아닌데, 우선 연구 주제가 2D에 대한 것을 넘어서 3D, Video 등에도 Diffusion 기반 연구들을 적용하는 시도들이 주류가 된 것으로 보여집니다. 또한 생성 모델 이외의 segmentation 등의 model의 경우 성능이 한계 점에 가깝게 도달했기 때문에 여러 분야의 model들 심지어 컴퓨터 비전 분야 외의 model 까지 융합해서 로봇, 차량 자율주행등 사업적인 가치를 가질 수 있는 것에 연구가 집중되는 것 같다는 느낌을 받았습니다.






