

[선행AI기술팀 방나모]
최근 몇 년간 자연어처리 기술은 눈부신 발전을 했습니다. 지금은 자연어처리 기술이 많은 산업 분야에 적용되어 사람의 수고를 덜어주는게 일반적인 상황이 되었습니다.
소프트웨어 개발 분야는 자연어처리 기술을 가장 적극적으로 이용하는 분야 중 하나입니다. 그 배경에는 자연어처리 연구자들이 적극적으로 연구중인 코드 자동생성 모델들이 있습니다.
이번 포스팅에서는 코드 자동생성 모델과 오픈소스 그리고 무료 서비스들을 이용하여 vscode에서 나만의 Code assistant를 extension 형태로 만들어 사용하는 법을 알아보겠습니다.
사전 준비 사항
이번 포스팅은 어떤한 GPU 자원도 없는 상황을 가정하여 진행됩니다. 그래서 우리가 사용해야할 서비스는 2가지가 있는데 바로 协作实验室과 ngrok입니다.
먼저, 协作实验室에서는 무료 사용자도 15GB의 Vram을 수 시간동안 사용할 수 있는데, 우리는 이를 이용해 코드 자동완성 모델을 올리고, colab notebook 안에서 간단한 백엔드 코드를 작성할 예정입니다. ngrok은 localhost를 public url로 연결해주는 서비스인데 이를 이용해 vscode의 extension에서 보내는 요청을 colab 세션에서 처리할 수 있게 연결하는 터널을 만들 겁니다.
포스팅을 끝까지 따라가기 위해서는 아래 3가지가 먼저 준비되어야합니다.
이 세가지만 준비 되었다면 이제 약 20줄만의 코드로 vscode에서 나만의 code assistant를 이용해볼 수 있습니다.
Colab에서 백엔드 개발하기
이제 우리는 새로운 colab notebook을 열어 아주 간단한 백엔드 서버를 만들어야합니다. 본격적으로 코드를 작성하기에 앞서 개발에 필요한 모듈을 colab에 설치하겠습니다.
!pip install fastapi uvicorn nest-asyncio pyngrok accelerate다음으로, ngrok을 이용하기 위해 ngrok configuration에 인증 토큰을 입력해야합니다. 인증 코드 입력은 아래 코드로 간단히 입력할 수 있습니다. ngrok 인증 토큰은 이 페이지에서 확인할 수 있습니다.
!ngrok config add-authtoken <YOUR_NGROK_AUTHTOKEN>이제 본격적으로 개발에 들어갈 차례입니다. 먼저 필요한 모듈을 import하고 코드 자동완성 모델을 로드하겠습니다. 이번 포스팅에서는 코랩 환경에서도 충분히 사용할 수 있는 codegemma-2b 모델을 활용하겠습니다.
from transformers import AutoModelForCausalLM, AutoTokenizer
from fastapi import FastAPI
from pyngrok import ngrok
import uvicorn
import torch
import nest_asyncio
HF_TOKEN = <YOUR_HF_TOKEN>
model = AutoModelForCausalLM.from_pretrained(
"google/codegemma-2b",
device_map="auto",
token=HF_TOKEN
)
tokenizer = AutoTokenizer.from_pretrained("google/codegemma-2b", token=HF_TOKEN)
다음으로, request를 처리할 로직을 작성하고, FastAPI 프레임워크를 사용해 URL에 대한 함수로 정의해주겠습니다. vscode에는 huggingface에서 개발한 llm-vscode라는 오픈소스 extension이 존재합니다. llm-vscode는 ollama, tgi, 拥抱的脸 등의 백엔드 서버와의 통신을 원활하게 해주는 extension입니다. tgi 등의 추론 서버를 구축하면 속도나 활용성 면에서 이점이 있으나, 协作实验室에서 도커를 사용하기 어려운 점을 고려하여 추론 서버를 사용하지 않고, 추론 서버의 output 포맷에만 맞춰 로직을 개발하겠습니다. 또한 request 처리 역시 llm-vscode에서 보내는 request 포맷을 가정하고 코드를 작성하겠습니다.
app = FastAPI()
@app.post('/generate')
async def generate(request:dict):
# request 처리
inputs = tokenizer([request["inputs"]], return_tensors="pt").to(model.device)
parameters = request["parameters"]
# generate method에 사용되지 않는 parameter pop
return_full_text = parameters.pop("return_full_text")
# 코드생성
output = model.generate(**inputs,**parameters)
return_text = tokenizer.decode(output[0], skip_special_tokens=True)
# 생성된 부분만 슬라이싱
if not return_full_text:
return_text = return_text[len(request["inputs"]):]
# text-generation-inference의 output format으로 맞춰 return
return {"generated_text":return_text}이제 사실상 백엔드 로직 개발은 완료되었습니다. 마지막으로 해야할 것은 ngrok으로 공용 localhost와 public url을 연결하는 터널을 만들고 uvicorn으로 app을 실행시키면 백엔드 개발은 완료됩니다.
아래 코드를 통해 colab의 localhost와 연결된 public url을 확인해줍니다.
ngrok_tunnel = ngrok.connect(8000)
print(f"URL: {ngrok_tunnel.public_url}")마지막으로, nest_asyncio로 asyncio의 event loop을 가능하게 한 뒤, uvicorn으로 app을 실행시켜줍니다.
nest_asyncio.apply()
# ngrok tunnel과 연결된 8000번 포트 사용
uvicorn.run(app, host="0.0.0.0", port=8000, reload=False)llm-vscode extension 설치 및 설정
이제 실질적인 코드 작성은 모두 끝났습니다. 이제 vscode를 켜 extension 탭에 들어가서 llm-vscode를 설치합니다.
이제 llm-vscode의 설정값을 적절히 바꿔주면 이제 vscode에서 Code assistant를 사용할 수 있습니다. vscode에서 설정 창은 ctrl+',' (Window), cmd+',' (Mac) 단축키로 쉽게 들어갈 수 있습니다. 설정창에 들어갔다면 검색창에 llm을 입력합니다. 우리가 변경해야할 설정값은 아래와 같습니다.
- Llm: Backend
- Llm: Config Template
- Llm: Fill In The Middle
- Llm: Tokens To Clear
- Llm: Url
协作实验室에서 개발을 진행할 때, output 포맷을 tgi 형태로 맞추었기 때문에 Backend를 tgi로 선택합니다. 또한, llm-vscode에서 Config Template을 제공하는 모델이 아닌 codegemma-2b를 사용하고 있으므로 Config Template은 Custom으로 설정합니다.
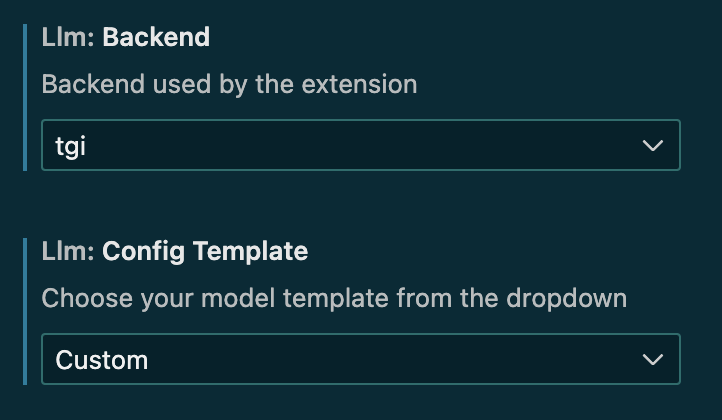
이제 Fill In The Middle에 사용되는 토큰을 codegemma가 학습할 때 사용한 토큰 형태로 바꿔줘야 합니다. codegemma는 prefix, suffix, middle 토큰으로 각각 <|fim_prefix|>, <|fim_suffix|>, <|fim_middle|> 토큰을 사용했습니다.
여기서 prefix 토큰은 코드의 시작, suffix는 커서의 위치 그리고 middle 토큰은 코드의 끝에 위치하게 됩니다. 이 토큰들은 모델이 코드의 중간 부분을 완성하는 능력을 학습하는데 사용됩니다.
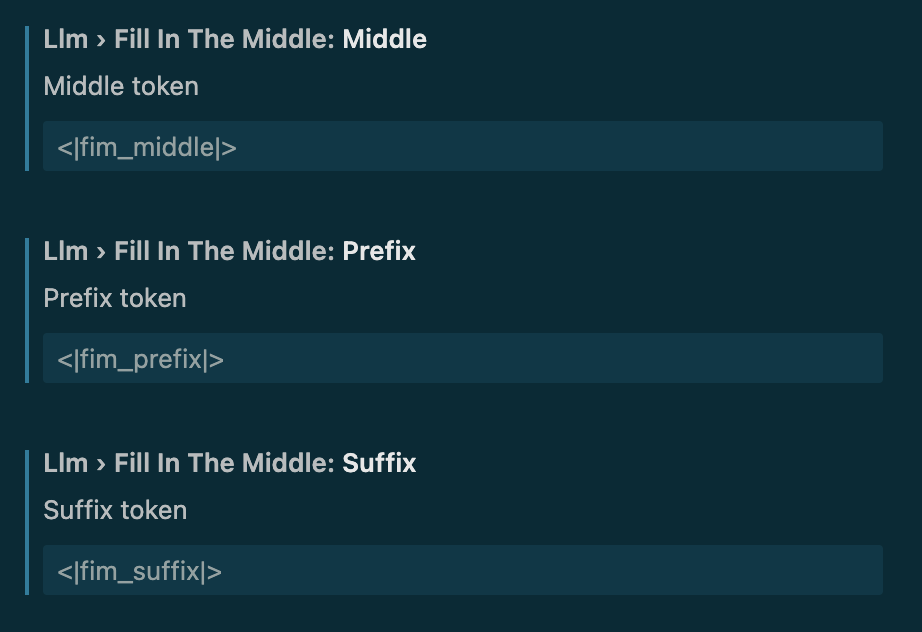
이제 특수한 목적으로 학습에 사용된 코드와 상관 없는 토큰들을 Tokens To Clear에 추가해줍니다. 여기에 추가해야할 토큰은 <|fim_prefix|>, <|fim_suffix|>, <|fim_middle|> 그리고 <|file_separator|> 토큰입니다.

마지막으로, settings.json을 열어 url(end point)을 ngrok으로 생성된 public url로 입력합니다. 이 때, 协作实验室에서 백엔드를 구현할 때 generate 함수를 /generate url로 바인딩 해주었기 때문에 <NGROK_PUBLIC_URL>/generate로 입력해줍니다.

결과
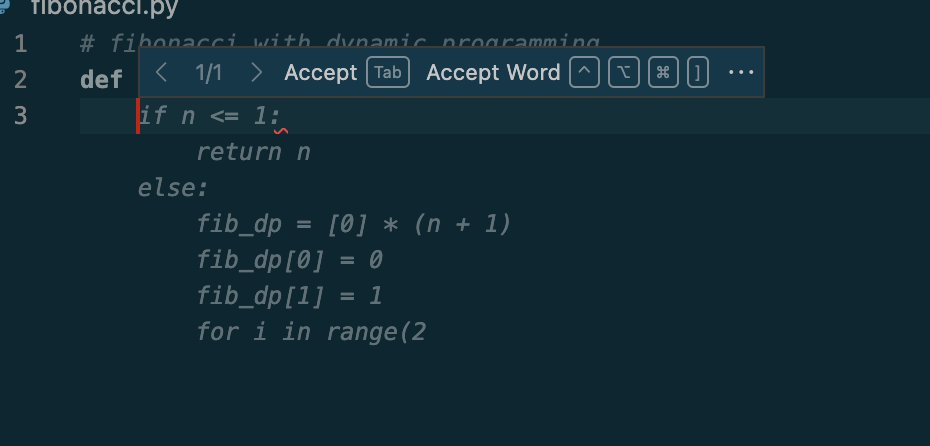
모든 준비가 끝났습니다. 이제 작업 중인 코드로 돌아가면 모델이 생성한 코드가 고스트 텍스트로 나타나는 것을 볼 수 있을 것입니다!
아래는 간단한 피보나치 함수를 정의하는 코드입니다. def fibonacci_dp(n):까지만 작성했음에도 피보나치 함수가 생성되는 것을 확인할 수 있습니다.
参考
- https://github.com/huggingface/llm-vscode
- https://github.com/huggingface/llm-ls
- https://ai.google.dev/gemma/docs/codegemma?hl=ko
- https://huggingface.co/google/codegemma-2b
- https://pyngrok.readthedocs.io/en/latest/






