文本到SQL是自动将自然语言转换为SQL的任务。我在底部分享的帖子是由Microsoft的Aerin Kim撰写的,它是关于Text-to-SQL的良好组织。考虑到世界上作为关系数据库存在大量数据,并且SQL是用于从该数据库获取信息的标准语言,因此可以说,如果完善了Text-to-SQL,则可以创建许多应用程序。可以轻松预测。
首先,研究中使用的数据集是WikiSQL,它是由CRM公司SalesForce使用Amazon Mechanical Turk构建的。 (在底部附加链接)

使用此数据集的早期研究基于各种自然语言“转化”研究中使用的seq2seq模型。打个比方,它是一种将人类语言“转换”为SQL语言的技术。相关地,SalesForce发表了一篇名为Seq2SQL的论文。 (附上以下链接)
数据库。但是,用户从数据库检索事实的能力是
由于对SQL等查询语言缺乏了解而受到限制。我们
提出Seq2SQL,这是一种用于翻译自然语言的深度神经网络
寻求…
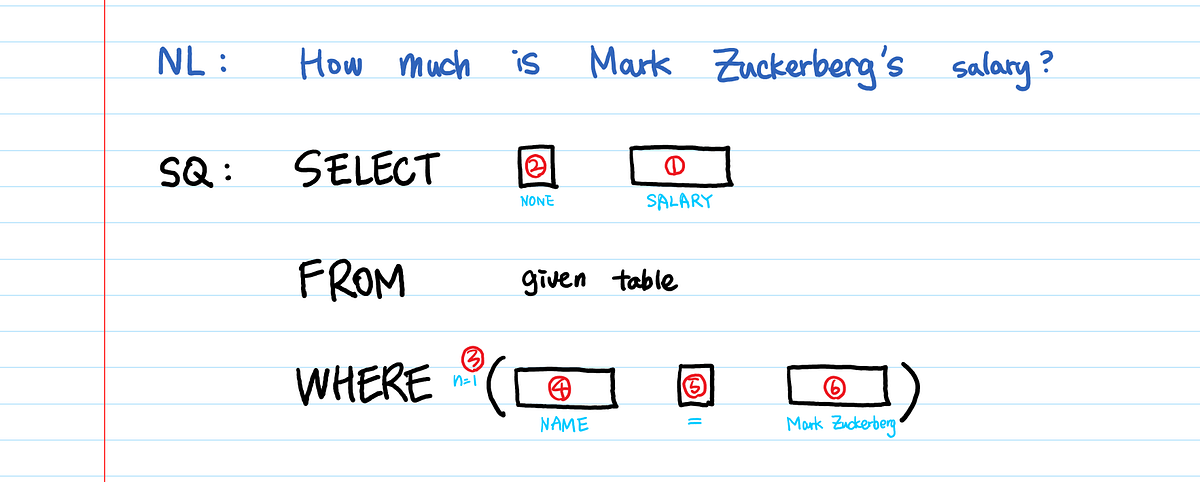
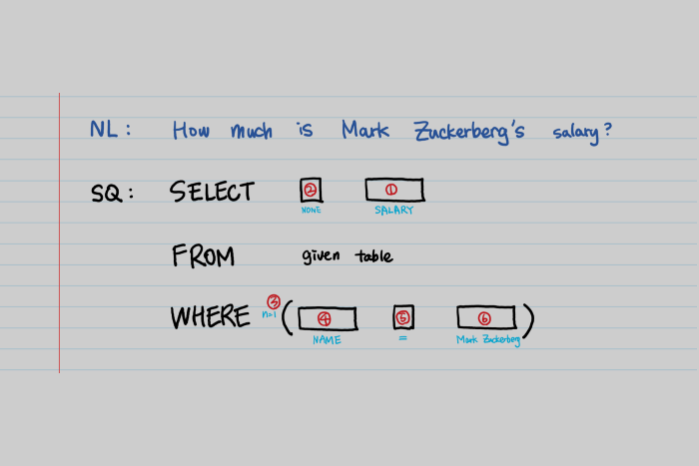
以上论文发表于2017年,目前的SOTA是分类模型,不是自然语言转换模型。换句话说,它使用一种预测可能出现在SQL语句中的每个短语(SELECT,FROM,WHERE)的参数的方法。在共享的文章中,我们将SQL语句总共分为6种类型(SELECT,AGGREGATION,WHERE条件数,WHERE列,WHERE运算符,WHERE值),并训练了每种分类模型。
但是,使用预训练的语言模型(BERT等)来应对自然语言的可变性(相同的词但不同的表达),注意力用于将自然语言映射到数据库模式,并且使用一种称为执行指导解码的技术来提高性能。介绍了。结果,对于WikiSQL来说,结果是相当不错的,但是并非所有问题都得到了解决。这是因为WikiSQL本身的使用限制太多。
例如,WikiSQL实际上并没有经常使用的JOIN操作。另外,没有语义值只能通过知道当前日期(例如“上个月”)来知道。此外,具有类似名称的模式,即“估计年薪”和“当前薪水”,“创建日期”和“修改日期”,“最终薪水”和“年薪”等。它是干净的数据,但是实际使用的数据库通常充满了模棱两可的模式。^^作者尝试了几种方法来解决这些问题,但是最后,没有为这些突变设计一个更复杂的模型,而是学习我们选择以多种方式应用多种技术来增强数据。
实际替代人类还远远不够,但我认为这项研究显示了足够的潜力。但是,当前基于分类的技术已经超越了基于生成技术的性能,并且这完全是针对SQL语言量身定制的,因此我想知道这种趋势将来是否还会继续。