
Google Lyra是一种基于生成模型的新语音压缩方法,通过极大地提高原始语音的声音质量(即大约需要8-16 kbps),可以仅以3 kbps的低带宽获得透明质量。获得透明的质量,其特点是在那里。以下是一些相关的博客文章:
语音压缩具有与音频压缩,图像压缩和视频压缩不同的特征。例如,音频压缩已经演变成一种模型化人耳特性的方法,而不是声源生成模型,而是听觉模型,因为它必须处理多种声源结合在一起的形式。图像压缩部分反映了低频成分比高频成分在视觉上更敏感的视觉特征,但是它没有积极地利用语音压缩或音频压缩等认知特征。视频压缩基本上基于图像压缩技术,并且添加了在时间序列上利用相邻图像的高度相似性的运动跟踪技术。
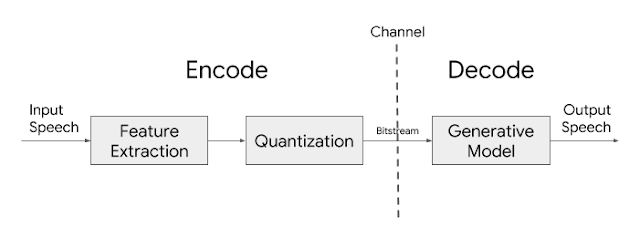
另一方面,由于已经清楚地识别了声音产生的机理,因此已经开发了压缩技术作为对人声器官进行建模的方法。具体地,取决于由肺的收缩引起的呼气是否通过声带而产生发声或不发声的信号,并且根据嘴的形状和舌头的位置来强调特定的频率范围。为此,低频带语音压缩算法提取人声振动频率(F0),有声或无声声音(发声/无声)和频率增强形式(频谱包络)作为参数,对其进行量化,传输,然后合成它们。这种方法称为参数语音编码,与Google Lyra基本具有相同的结构。
在各种语音压缩技术中,格里芬(Griffin)于1987年发布的MBE(多频带激励)也具有参量语音编码结构。 MBE将频域划分为相等大小的频带,传输这些频带的能量,并确定每个频带的有声/无声信息。如果是特征部分,则MBE解码器(即恢复语音信号的部分)将使用Griffin-Lim算法,该算法与基于深度学习的TTS中广泛使用的算法相同。任何信号都可以表示为多个正弦波之和,每个正弦波都有自己的能量和相位信息。 Griffin-Lim算法是一种在仅提供能量而没有相位信息的情况下恢复信号的方法,与WaveNet系列算法相比,Griffin-Lim算法在音质方面有根本的局限性。
尽管尚未公开有关Google Lyra的技术细节,但已知遵循类似于混合激励线性预测(MELP)的方法。 MELP与MBE相似,但是与MBE相比,MELP通过计算和传输线性预测系数来提高效率,MBE将频谱包络表示为每个频带的能量。另外,不是每个频带都发送浊音信息,而是利用低频区域存在浊音而高频区域存在浊音这一事实,仅发送截止频率。表达。
据此预测,假定Google Lyra具有类似于MELP的结构,但使用WaveRNN代替Griffin-Lim算法作为合成器。在基于深度学习的TTS的情况下,即使编码器部分相同,但考虑到音质差异很大,通过用WaveRNN代替Griffin-Lim代替MELP合成器似乎可以显着提高音质合成器算法的类型。
与Griffin-Lim相比,WaveRNN仍然非常复杂,语音信号传输所需的带宽明显低于图像和视频,因此增加压缩率的需求确实较低。例如,如果将16 kbps降低到3 kbps,则带宽减少到1/5,但是考虑到传输Full-HD视频所需的带宽为几Mbps或更高,则总减少量仅为1%。因此,将Google Lyra之类的技术应用于YouTube之类的视频服务似乎没有太大的必要。取而代之的是,它将对近年来使用迅速增长的基于音频的服务(例如Clubhouse)非常有用,在这种情况下,主要的技术挑战将是降低复杂性,即在设备上的操作越多越好。现有的语音压缩技术已经在智能手机中得到了有效的实施,电池消耗将大大降低。






