
[前研究组柳熙Jo]
自深度学习热潮的早期以来,翻译一直是一个研究课题。现在在任何领域都使用的注意力,也是第一个提出的解决 Seq2Seq 结构问题的方法。在过去的 10 年中,基于深度学习的翻译器的性能一直在稳步提升,这种翻译器性能的提升解决了许多语言障碍。
当前的翻译技术主要集中在文本到文本(text-to-text translation,T2TT)上。虽然文本的抽象对于将模型提升到一定程度非常有用,但它存在消散对话中各种非语言元素的问题。这个问题在对话中尤为明显。当两个不同语言的人使用翻译器时,我们通常会经历一个类似‘L1语音→L1识别(L1文本)→L1L2翻译(L2文本)→L2 TTS(L2语音)”的过程。通过识别和翻译消失的非语言信息成为当前翻译人员无法解决的障碍。
为了解决这个问题,谷歌在 2019 年发布了 Translatotron,今年 7 月发布了 Translatotron 2。 Translatotron 与传统翻译模型的主要区别在于,它侧重于语音到语音(speech-to-speech translation,S2ST)。发表该模型的论文称,S2ST与T2TT相比,具有可以在语音输出中反映L1的非语言信息,以及由于计算过程减少而减少时间和错误等优点, 等等。
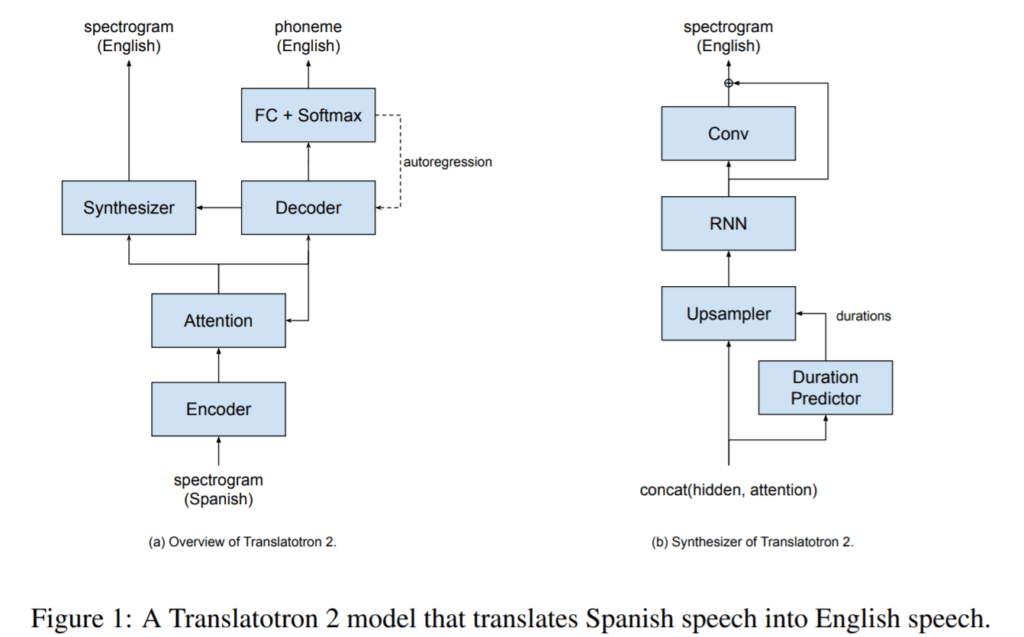
Translatotron 2 的粗略结构接近于混合 ASR 和 TTS 模型的结构。它接收L1语音信息(mel-spectrogram)并用解码器(ASR)预测L2音素,同时在计算L2音素(TTS)之前通过合成器结合解码器输出和注意力来预测L2 mel-spectrogram。因此,模型中不考虑 L1 音素。
当然,这种结构说明S2ST技术还有很多障碍需要克服。所提出的模型通过文本输出的解码器更接近于语音到文本到语音的结构,而不是目标语音到语音。模型的质量也很可能会根据 L1 和 L2 之间的差异程度而有所不同。特别是,用于解码器的注意力在具有不同词序的语言(例如韩语)中表现出的性能要低得多。但是,尽管如此,这些模型还是在问,“深度学习难道不会让我们有一天克服我们面临的许多语言障碍吗?”这也提高了预期。
参考
Jia, Y.、Ramanovich, M.T.、Remez, T. 和 Pomerantz, R.(2021 年)。 Translatotron 2:强大的直接语音到语音翻译。 arXiv 预印本 arXiv:2107.08661.
Jia, Y., Weiss, RJ, Biadsy, F., Macherey, W., Johnson, M., Chen, Z., & Wu, Y. (2019)。使用序列到序列模型的直接语音到语音翻译。 arXiv 预印本 arXiv:1904.06037.






