Text-to-SQL은 자연어를 SQL로 자동 변환하는 Task입니다. 하단에 공유한 글은 Microsoft 소속의 Aerin Kim이 작성한 글인데, Text-to-SQL에 대해서 잘 정리되어 있습니다. 세상에는 수 많은 데이터들이 Relational Database로 구축되어 있고, 이 Database에서 정보를 취득하기 위해 사용되는 표준 언어가 SQL이라는 것을 감안하면 Text-to-SQL이 완벽하게 될 경우 수 많은 적용 분야를 만들 수 있을 거라는 것을 쉽게 예측할 수 있습니다.
먼저, 연구에 사용된 Dataset은 CRM 업체인 SalesForce가 Amazon Mechanical Turk를 활용해서 구축한 WikiSQL입니다. (하단 링크 첨부)

이 Dataset을 사용한 초기 연구들은 다양한 자연어 “변환” 연구에서 사용되는 seq2seq 모델에 기반하고 있습니다. 비유를 들자면, 인간의 언어에서 SQL이라는 언어로 “번역”하는 기술인 셈입니다. 관련하여, SalesForce는 Seq2SQL이라는 제목의 논문을 발표했습니다. (하단 링크 첨부)
databases. However, the ability for users to retrieve facts from a database is
limited due to a lack of understanding of query languages such as SQL. We
propose Seq2SQL, a deep neural network for translating natural language
quest…
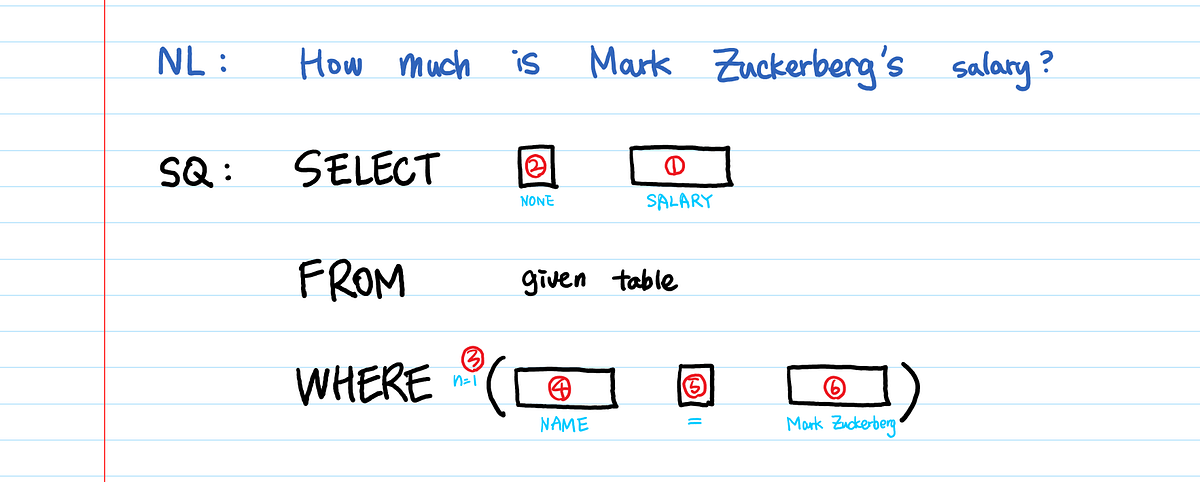
위의 논문은 2017년에 발표되었는데, 현재의 SOTA는 자연어 변환 모델이 아니라 분류 모델입니다. 즉, SQL 구문에서 등장할 수 있는 각 phrase(SELECT, FROM, WHERE)들의 인자를 예측하는 방법을 사용합니다. 공유한 글에서는 SQL 구문을 총 6개 타입으로 분류하고 (SELECT, AGGREGATION, number of WHERE conditions, WHERE column, WHERE operators, WHERE value) 각각 분류 모델을 학습시켰습니다.
다만, 자연어의 변이성 (같은 말인데 표현이 다름) 대응을 위해서는 pre-trained language model(BERT 등)을, 자연어와 데이터베이스 스키마 매핑을 위해서 attention을 사용하였고, 성능 향상을 위해 execution-guided decoding이라고 불리는 기법을 도입하였습니다. 그 결과, WikiSQL 대상으로 상당히 좋은 결과를 보였지만 문제가 다 해결된 것은 아닙니다. 실제로 사용하기에는 WikiSQL 자체가 너무 제한적인 형태의 데이터이기 때문입니다.
예를 들어, WikiSQL은 실제로 빈번하게 사용되는 JOIN operation이 없습니다. 또한, “last month”와 같이 현재 날짜를 알아야만 알 수 있는 semantic한 값이 존재하지 않습니다. 그 외에도 유사한 이름의 스키마, 즉 ‘연봉 추정치’와 ‘현재 연봉’, ‘생성날짜’와 ‘수정날짜’, ‘최종연봉’과 ‘연봉’ 등 실제로 데이터베이스를 설계한 사람이 아니면 애매한 값들이 없는 매우 깨끗한 데이터인데, 실제로 사용되는 데이터베이스들은 애매 모호한 스키마로 가득찬 경우가 많습니다^^ 저자는 이러한 문제들을 해결하기 위해서 여러 가지를 시도했지만, 결국 이러한 변이들에 대해서 모델을 더 복잡하게 설계하는 대신, 학습 데이터를 여러 가지 방법으로 augmentation하는 기술들을 다수 적용하는 방향을 택했습니다.
아직 실제로 인간을 대치하거나 할 정도는 아니지만 충분한 가능성을 보여주는 연구라고 생각합니다. 다만, 현재 분류 기반 기술이 생성 기반 기술의 성능을 상회하고 있는데, 이는 다분히 SQL이라는 언어에 맞춰진 것이므로 이러한 경향이 앞으로도 계속 유지될 지 궁금해집니다.