
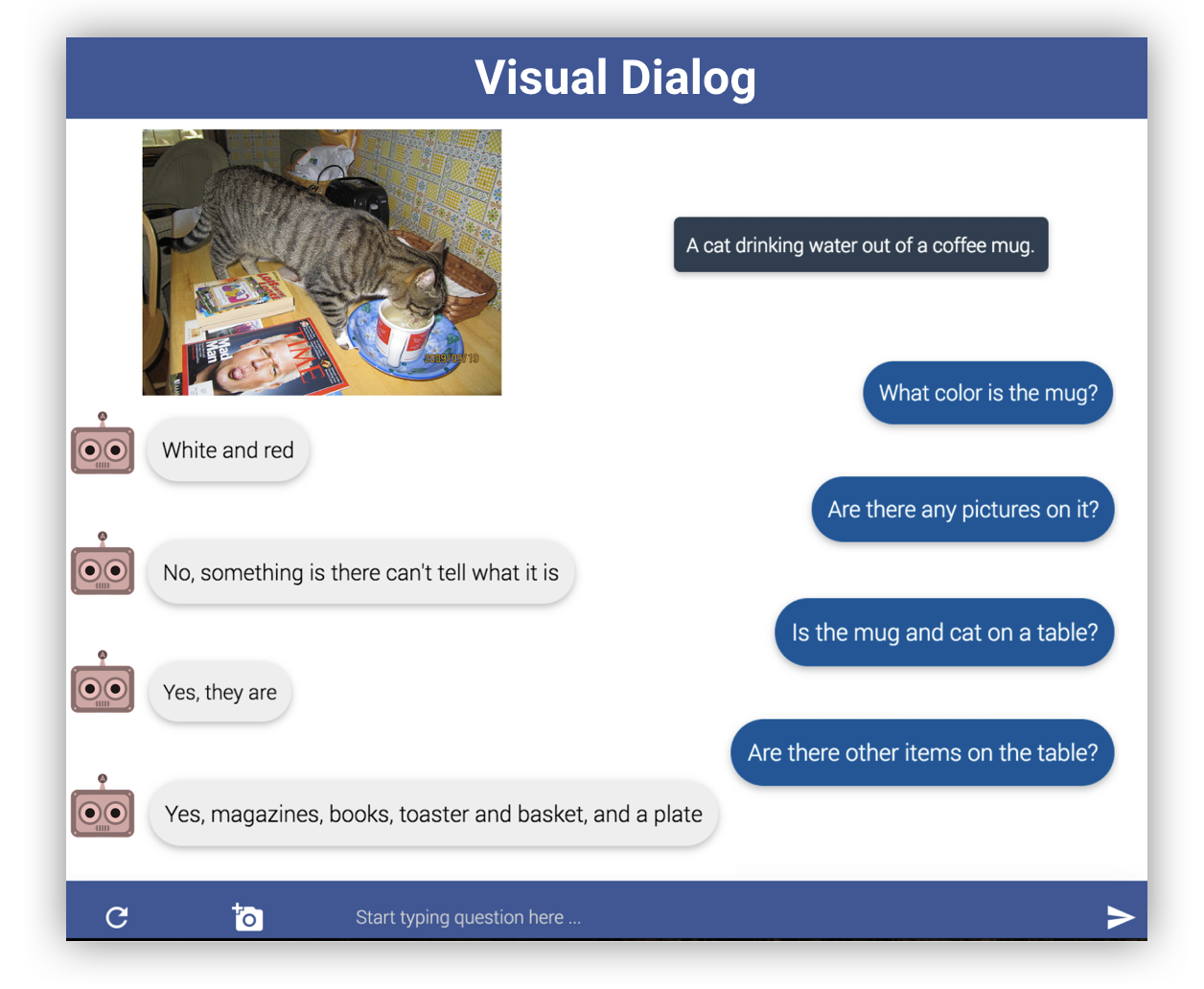
Visual Dialog task는 질의 응답으로 이루어지는 Q&A task에 이미지를 추가한 멀티모달 task입니다. 예를 들어 흰색 고양이와 검은색 강아지가 함께 있는 사진을 주고 “고양이 옆 동물은 무슨 색이야?”라고 물어보면 “검은색”하고 대답하는 식이지요. 구체적으로, 이미지와 dialog history, question을 주면 answer를 생성하는 task입니다. Visual Dialog 사이트에 가 보면 데이터셋이 공개되어 있고 v1.0 기준 12만개 이미지와 120만개 텍스트 문장이 있습니다. (이미지 1개당 대화 1개) 아래 링크는 Visual Dialog 사이트의 데이터셋 페이지입니다.
이 사이트에서는 매년 challenge를 개최하는데 아래의 영상은 MReaL-BDAI 라고 부르는 시스템으로 1위를 차지한 팀의 기술 소개 영상입니다. 평가 메트릭 중 하나인 NDCG 기준, 2위를 10점 가까이 상회하는 놀라운 점수를 냈습니다. (74.57)
그러나 이 기술의 논문을 읽어보면 새로운 모델 구조가 아니리 기존 NDCG 59점대의 기술에 여러 가지 (task 의존적) 직관에 의한 최적화 기술로 74점까지 끌어올립니다. (2스텝 학습법이라고 소개된 방법 만으로 NDCG를 10점 올립니다) 그리고 후속 논문을 통해 현재 정의된 Visual Dialog Task에 최적화 시킨 방법들을 자세히 설명합니다. 아직 그 논문을 다 읽어보지는 못했지만 특정 Task 혹은 특정 metric에 최적화시킨 경향이 있다고 생각하고 있습니다. (예를 들어 MRR의 경우 3위 팀보다 10점 이상 뒤집니다) 논문 링크도 첨부합니다.
MReaL-BDAI, for Visual Dialog Challenge 2019: two causal principles for
improving Visual Dialog (VisDial). By “improving”, we mean that they can
promote almost every existing VisDial model to the state-of-the-art performance
on t…
Visual Dialog Task가 일정 부분 문제가 있고 평가 메트릭 또한 실제 성능과는 괴리가 있지만 멀티모달 대화는 향후 챗봇의 방향 중 하나가 될 수 있는 중요한 분야라고 생각합니다. 사람끼리 이야기 할 때는 언어적 정보에만 의존하는 것이 아니라 시각적 정보, 청각적 정보, 후각적 정보 등 다양한 정보에 의존합니다. 챗봇이 우리의 표정을 읽고 대화를 걸어올 수도 있고 우리가 보는 것과 같은 것을 ‘보고’ 듣는 것을 ‘듣고’ 하면 대화의 폭이 훨씬 넓어질 거라고 봅니다. 함께 BTS 공연을 보고 들으며 우리와 대화하는 챗봇을 기대해 봅니다.






