
특수 훈련을 받으면 입술 움직임만으로 무슨 말 하는지 알 수 있다고 하는 이야기를 들은 적이 있는데요, 링크글의 연구는 이것을 AI로 실현한 것입니다^^ Lip2Wav라고 불리는 이 기술은 이미지로부터 ConvNet을 이용하여 feature를 추출한 후, attention 기반의 speech decoder로 mel cepstrum을 생성해냅니다. 그 후엔 보코더를 붙여서 합성을 하는데, 결과가 꽤 흥미롭습니다. (링크글에 데모 영상 있습니다) 깃헙에는 코드는 물론 데이터셋까지 공개되어 있습니다.
MIT의 Speech2Face, 즉 음성신호로부터 얼굴을 생성해내는 기술을 볼 때도 많이 놀랐었는데 Lip2Wav도 재미있네요. 두 연구 공히 encoder-decoder 구조를 가지고 있는데, 다양한 입출력에 대한 A2B 형태의 다양한 연구들이 계속 나올 것으로 기대됩니다. 아래는 Lip2Wav의 프로젝트 페이지입니다.
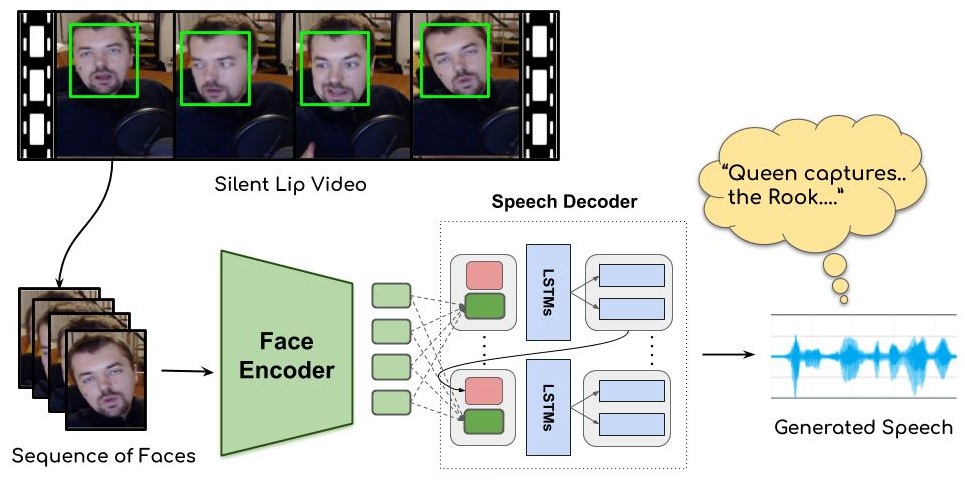
Learning Individual Speaking Styles for Accurate Lip to Speech Synthesis
Centre for Visual Information Technology (CVIT) is a research centre at International Institute of Information Technology, Hyderabad.
또한, 저자는 코드와 학습 데이터도 공개해 놓았습니다. 이에 대한 링크도 함께 첨부합니다.

Rudrabha/Lip2Wav
This is the repository containing codes for our CVPR, 2020 paper titled “Learning Individual Speaking Styles for Accurate Lip to Speech Synthesis” – Rudrabha/Lip2Wav

COVE – Computer Vision Exchange
Lip2Wav is a dataset for benchmarking speaker-specific lip to speech synthesis in unconstrained settings. It contains over 100 hours of video content of 5 speakers uttering natural speech in real-world environments. It is designed to investigate the question: “How accurately can we infer an individu…






