
다수의 convolution layer로 구성된 AlexNet이 등장한 이래 딥러닝 모델의 구조에 대한 많은 연구들이 있어 왔습니다.
예를 들어, Google Inception은 3×3, 5×5, 7×7 등 서로 다른 커널 크기를 갖는 convolution layer를 각기 만들고 concatenation하는 방식으로 파라미터 당 효율을 올리는 방법을 사용했고, Microsoft ResNet은 skip connection, 즉 convolution layer를 거치지 않는 data path를 하나 더 만들고 convolution layer를 거친 결과와 더하는 방법으로 수천 개 이상의 레이어를 갖는 복잡한 구조에서도 gradient vanishing이 생기지 않도록 했습니다. 이 두 가지 방법들은 간단하면서도 효율적이어서 다른 딥러닝 모델들을 설계하는데에도 활발하게 사용되고 있습니다.
한편, 접근법은 다르지만 파라미터 당 성능을 높이면서도 복잡도를 낮추기 위해서 Google MobileNet과 Xception에서는 depthwise separable convolution이라는 기술이 사용되었으며 ShuffleNet에서는 랜덤으로 셔플링을 하는 layer를 추가하는 방식으로 복잡도를 낮추었습니다.
다만, inception의 경우 3×3, 5×5, 7×7 커널을 조합해서 사용하는 것이 수학적으로는 7×7 커널만을 사용하는 것에 대한 부분 집합이어서 모델 표현력 향상이라기 보다는 복잡도 감소에 그 의의가 있는데, 사실상 하나의 커널을 사용하는 것에 비해 다수의 data path가 생김으로 인해 파라미터 수 감소에 비해 속도 향상이 크지 않습니다. 이는 depthwise separable convolution도 마찬가지인데, group convolution의 한 가지 형태인 depthwise convolution의 경우 2D convolution과 1D convolution의 조합으로 볼 수 있으며 이 경우 3D convolution을 사용하는 것에 비해 파라미터 수는 비약적으로 감소하지만 실제 구현 후 성능 향상 폭은 그리 크지 않습니다. 이는 하나의 병렬 연산을 두 개의 연산으로 분해하는데서 오는 효율성 하락이라고 볼 수 있습니다.
ResNet의 경우는 왜 학습이 잘 되는지에 대해서 많은 부속 연구들이 있어 왔습니다. Convolution layer를 통과한 신호와 그렇지 않은 신호를 더하는 것이 마치 원 신호를 예측 값과 잔차 신호로 분해하는 것과 닮았기 때문에 상대적으로 변이가 줄어든 잔차 신호의 모델링을 더 효과적으로 할 수 있다는 해석(모델링 파워 증가)이 있었던 반면, 단순히 다수의 레이어를 더 작은 레이어들로 분할하여 학습한 후 앙상블하는 형태(학습 기법)에 불과하다는 의견도 있었습니다. 부연 설명을 하자면, 후자의 경우 skip connection이 사용되는 것이 사실 convolution layer 하나를 건너 뛰는 역할을 할 수 있기 때문에 결과적으로 레이어의 수를 줄이는 효과를 낸다는 것입니다.
개인적으로 ResNet 계열의 딥러닝 모델을 학습시키면서 weight의 변화를 지속적으로 관찰해 본 경험도 이와 유사했습니다. 즉, 학습 초기에는 skip connection이 더 많이 사용되지만 학습이 점차적으로 진행되면서는 skip connection의 역할이 줄어드는 것입니다. 또한, 학습 단계에선 ResNet을 사용하지만 학습이 완료된 후 skip connection을 제거하고 몇 epoch의 학습을 더 진행시켜서 유사한 성능을 내는 사례도 본 적이 있습니다.
RepVGG의 저자들은 Inception이나 Residual Network과 같은 다중 data path와 복잡한 구조를 사용하지 않고 convolution layer만으로 성능을 올리는 시도를 하였습니다. 이 시도가 재미있는 것이, 학습 단계와 추론 단계에서 모델 구조를 다르게 쓰는 것입니다. 다음은 논문에 포함되어 있는 그림입니다:
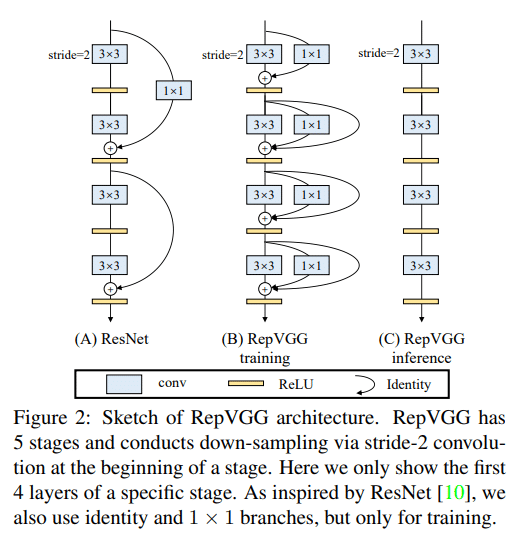
일반적으로 ResNet에서는 Input-Relu-Conv-Output 조합을 반복하는데, Input을 1×1 convolution으로 차원을 맞춘 후 Output에 더하는 방식을 사용합니다. Input과 Output 사이에는 비선형 함수인 Relu가 있습니다. 이에 비해 RepVGG에서는 선형 연산 단계인 Conv 자체를 여러 개의 data path로 분할합니다. 분할된 각각의 path는 3×3 convolution, 1×1 convolution 등 다양한 커널을 갖는 convolution들로 구성됩니다. 이렇게 학습을 수행했더니 gradient vanishing 문제 없이 학습이 잘 수행되었으며, ResNet 등 기존 모델에 비해서 오히려 더 우수한 성능을 갖도록 할 수 있었다고 합니다.
여기에서 주목할 부분은 선형 연산 단계만이 여러 개의 data path로 분할되었기 때문에, 학습이 완료된 이후 이 data path들은 단순 계산에 의해 하나의 convolution으로 합쳐질 수 있습니다. RepVGG의 저자들은 이 것을 structural re-parameterization이라고 명명했으며, 이 과정을 거치고 나면 결국 단순한 convolution 연산 하나로 수렴하게 되어, 추론 단계에서 활용할 수 있습니다. RepVGG에서는 결과적으로 3×3 convolution만을 사용하였으며 skip connection을 사용하지 않기 때문에 VGG-like라고 표현하였습니다. 이렇게 구현된 결과물은 data path도 단순하며 하드웨어 구현에도 유리합니다. 실제 실험 결과, 소프트웨어로 구동시켰을 경우에도 ResNet보다 훨씬 더 빠르고 성능도 좋다고 합니다.
위의 결과는 Residual Network이 결국 모델 표현력 향상 기술이 아니라 학습 용이성 향상 기술이라는 점을 시사합니다. 물론 그렇다고 해서 Residual Network이 유용하지 않은 기술이라는 의미는 아니지만, skip connection의 역할에 대해서 좀 더 명확하게 이해할 수 있었다는 점에서 RepVGG의 실험 결과는 더 흥미롭습니다. RepVGG github 공유합니다.







