
Google Lyra는 생성 모델에 기반한 새로운 음성 압축 방식으로서, 기존 음성 압축 방식들이 원본 수준의 음질, 즉 transparent quality를 얻기 위해 약 8-16kbps 정도가 필요한 것을 크게 향상시켜서 3kbps의 낮은 대역폭 만으로도 transparent quality를 얻을 수 있는 것이 특징입니다. 다음은 관련 블로그 글입니다:
음성 압축은 오디오 압축, 이미지 압축, 동영상 압축과는 구분되는 특징을 가지고 있습니다. 예를 들어 오디오 압축은 수 많은 음원들이 합쳐진 형태를 다루어야 하므로 음원 생성 모델이 아니라 청각 모델, 즉 인간의 귀가 가지는 특성을 모델링하는 방식으로 발전해 왔습니다. 이미지 압축은 저주파 성분이 고주파 성분보다 더 시각적으로 민감하다는 시각적 특성을 일부 반영하긴 하지만 음성 압축이나 오디오 압축처럼 적극적으로 인지 특성을 활용하고 있지는 못합니다. 동영상 압축은 기본적으로 이미지 압축 기술에 기반하며, 시계열 인접 이미지들의 높은 유사성을 활용하는 움직임 추적 기술이 추가됩니다.
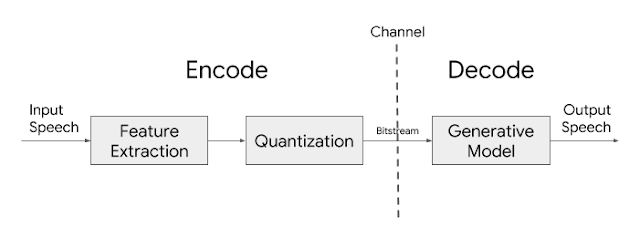
이에 반해, 음성은 생성 메커니즘이 명확하게 규명되어 있기 때문에 인간의 발성 기관을 모델링하는 방식으로 압축 기술이 발전되어 왔습니다. 구체적으로는 폐의 수축에 의한 날숨이 성대를 통과하면서 그 떨림 여부에 의해서 유성음 혹은 무성음 신호가 만들어지며, 구강의 형태와 혀의 위치에 따라 특정 주파수 영역이 강조되게 되는 절차를 거칩니다. 이를 위해 저대역 음성 압축 알고리즘들은 성대의 떨림 주파수(F0), 유성음 혹은 무성음 여부(voiced/unvoiced), 주파수 강조 형태(spectral envelope)를 파라미터로 추출한 후, 이를 양자화하여 전송한 후 합성하게 됩니다. 이러한 방식을 parametric speech coding이라고 하는데, Google Lyra도 기본적으로는 같은 구조를 가지고 있습니다.
다양한 음성 압축 기술 중 1987년에 Griffin에 의해 발표된 MBE(multi-band excitation)도 parametric speech coding 구조를 가지고 있습니다. MBE는 주파수 영역을 균등 크기의 밴드들로 분할하고, 이 밴드들의 에너지를 전송하며, 유/무성음 정보 또한 밴드별로 각각 판단하게 됩니다. 특징적인 부분이라면 MBE의 복호화부, 즉 음성 신호를 복원하는 부분에서는 Griffin-Lim 알고리즘이 사용되는데, 딥러닝 기반 TTS에서도 많이 활용되고 있는 알고리즘과 동일합니다. 어떤 신호라도 다수의 사인파의 합으로 표현 가능하며, 각 사인파는 각각의 에너지와 위상 정보를 가지게 됩니다. Griffin-Lim 알고리즘은 에너지만 주어지고 위상 정보가 없을 때, 신호를 복원하기 위한 방법인데, WaveNet 계열의 알고리즘에 비해 음질 측면에서는 근본적인 한계를 가지고 있습니다.
Google Lyra에 대한 상세한 기술적 내용이 공개되지는 않았지만, MELP(mixed-excitation linear prediction)와 유사한 방식을 따르고 있다고 알려져 있습니다. MELP는 MBE와 유사한 방식이지만 spectral envelope을 복수개의 밴드별 에너지로 표현하는 MBE에 비해 선형 예측 계수를 계산하여 전송함으로써 더 효율성을 높이고 있습니다. 또한, 유/무성음 정보도 밴드별로 전송하는 것이 아니라 주로 유성음은 저주파 영역에, 무성음은 고주파 영역에 존재한다는 것을 이용하여 cut-off frequency만을 전송하고, 이보다 낮은 대역은 유성음으로, 나머지 대역은 무성음으로 표현하게 됩니다.
이로부터 예측해보면, Google Lyra는 MELP와 유사한 구조를 가지고 있지만 합성기로 Griffin-Lim 알고리즘 대신 WaveRNN을 사용한 것으로 추정됩니다. 딥러닝 기반 TTS의 경우도 인코더 부분이 같더라도 합성기 알고리즘의 종류에 따라서 음질 차이가 크게 난다는 것을 감안하면 MELP의 합성기를 Griffin-Lim 대신 WaveRNN으로 대치함으로써 음질을 크게 향상시킬 수 있었던 것으로 보입니다.
Griffin-Lim에 비해 WaveRNN은 여전히 복잡도가 매우 높고, 음성 신호 전송에 필요한 대역폭은 이미지나 동영상에 비해서 월등히 낮기 때문에 압축율을 높여야 하는 필요성이 상대적으로 낮은 것은 사실입니다. 예를 들어 16kbps를 3kbps로 낮추면 1/5로 대역폭이 감소한 것이지만 Full-HD 동영상을 전송하기 위해 필요한 대역폭이 수Mbps 이상임을 감안하면 전체 감소폭은 1%에 불과합니다. 따라서 유튜브와 같은 동영상 서비스에 Google Lyra와 같은 기술을 적용할 필요는 크지 않다고 보입니다. 대신, 클럽하우스와 같이 최근 활용도가 급격히 증가되고 있는 오디오 기반 서비스들의 경우에는 매우 유용할 거라고 생각되며, 이 경우 주요 기술적 과제는 온디바이스에서의 동작, 즉 복잡도를 가급적 낮추는 것이 될 것입니다. 기존 음성 압축 기술들은 이미 스마트폰에서 효과적인 방식으로 기 구현되어 있을 뿐 아니라 배터리 소모량도 월등히 낮을 것이기 때문입니다.






