자연어 처리 분야에 적용하기 위해서 만들어진 transformer는 최근 텍스트 뿐 아니라 이미지나 동영상과 같은 다양한 데이터에 대해서도 적용되어 우수한 성능을 보여주고 있습니다. 하지만 텍스트와 이미지, 동영상은 각각 1D, 2D, 3D 데이터라는 차이만 있을 뿐 근본적으로 일렬로 나열된 비구조화 데이터라고 볼 수 있습니다. 따라서 크게 바꾸지 않고도 같은 transformer 알고리즘을 적용할 수 있습니다.
현실 세계의 데이터들은 독립적으로 존재하는 것이 아니라 데이터들간의 관계에 의해 구조화된 형태를 가지는 것이 많습니다. 넷플릭스나 유튜브의 동영상들과 사용자들의 선호도, 게이머들과 그들이 플레이한 게임이나 구매한 아이템들, 더 나아가 인간의 지식 자체도 단순 나열이 아니라 서로 복잡하게 얽혀 있는 구조화된 데이터에 가깝습니다. 이러한 데이터들을 표현하기 위한 수단으로 최근 그래프 데이터베이스가 각광받고 있습니다. 각 데이터들은 그래프 데이터베이스 내의 entity로 표현되며, 각 entity들은 relationship으로 연결되고, 각 relationship들은 property를 갖습니다.
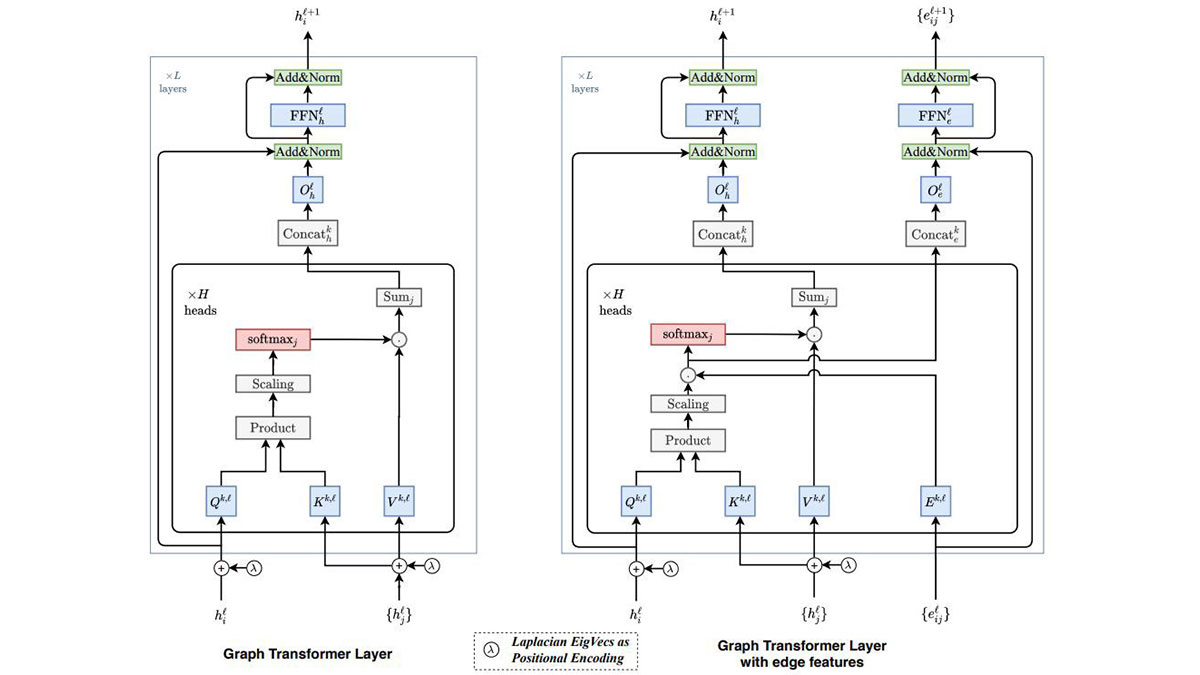
Graph transformer는 기존 transformer를 변형하여 그래프로 표현된 구조화된 데이터를 입력으로 사용할 수 있도록 한 것입니다. 즉, 각 데이터들 각각의 특성 뿐 아니라 데이터들 간의 관계도 함께 학습하는 것을 목표로 합니다. 이를 위해서 크게 두 가지 부분이 변경되었습니다.
첫 번째는 attention입니다. 자연어 데이터의 경우 attention은 보통 문장 내 모든 다른 단어들과의 연결을 통해 구현됩니다. 물론 attention을 그래프 내 모든 노드들과의 연결을 통해 구현할 수도 있겠지만 많아 봐야 수십 단어 정도에 불과한 문장 내 단어 수에 비해 그래프 데이터베이스 내의 노드 수는 엄청나게 많을 수 있기 때문에 효율적이지 않습니다. Graph transformer에서는 attention을 인접한 노드들과의 연결로 제한함으로써 이러한 문제를 완화시켰습니다. 적용 분야에 따라서는 인접한 노드(1차 이웃) 뿐 아니라 인접한 노드들과 다시 인접한 노드들(2차 이웃)로 확장할 수도 있을 것 같습니다.
두 번째는 positional encoding입니다. Positional encoding은 주어진 데이터에서 각 entity의 고유한 위치 정보를 보존하기 위해서 사용됩니다. 예를 들어 문장 내 각 단어들은 서로 다른 positional encoding vector를 갖게 되며, 이를 반영함으로써 문장 내 단어 출현 순서가 변경되었을 때 서로 다른 의미를 갖도록 학습할 수 있습니다. 다만 1차원 나열 형태인 자연어의 문장과는 달리 그래프의 노드들은 훨씬 더 복잡하게 연결되어 있기 때문에 좀 더 일반적인 방식을 사용해야 합니다. Graph transformer에서는 그래프에서 각 노드들의 연결 형태를 행렬로 표현한 adjacent matrix의 확장 형태인 Laplacian matrix를 다수의 eigenvector들로 분해해 놓고 모든 노드들은 이 eigenvector들 중 일부를 선택하여 positional encoding vector로 사용합니다. 이러한 Laplacian positional encoding을 선형적으로 이어진 그래프에 대해서 적용해 보면 기존 transformer에서 사용되는 sinusoidal positional encoding과 동일하게 되기 때문에 저자들은 이 방식이 기존 방식을 확장한 형태라고 이야기하고 있습니다.
그간 연구되어온 AI 기술들이 주로 텍스트, 이미지, 비디오, 음성과 같은 미디어 데이터를 대상으로 해 왔다면, 향후에는 구조화된 데이터를 대상으로 한 AI 기술들이 점차 더 많이 등장하지 않을까 예상해봅니다. Graph transformer와 관련된 기사를 공유합니다.