
[선행연구팀 이정우]
최근의 강화학습은 다양한 과제에서 AI agent가 인간의 성능을 압도할 수 있음을 보여줬습니다. 하지만, 학습되지 않은 AI agent는 사람과 비교했을 때, 많은 시간의 학습을 요구하며 다양한 과제들에 대한 일반화 성능이 좋지 못하다는 단점을 가지고 있습니다. 반면 사람은 AI agent와 다르게, 새로운 상황에 잘 적응하며, 새로운 지식을 계속해서 학습해 나아갈 수 있는 능력을 가지고 있습니다. 이런 사람의 능력을 참고해 Continual Learning이 탄생하게 되었습니다. 이번 글에서는 Towards Continual Reinforcement Learning: A Review and Perspectives (Khetarpal et al., 2020)을 통해 현실 세계의 상황과 잘 맞는 Continual Reinforcement Learning에 대해 소개하고자 합니다.
- Reinforcement Learning
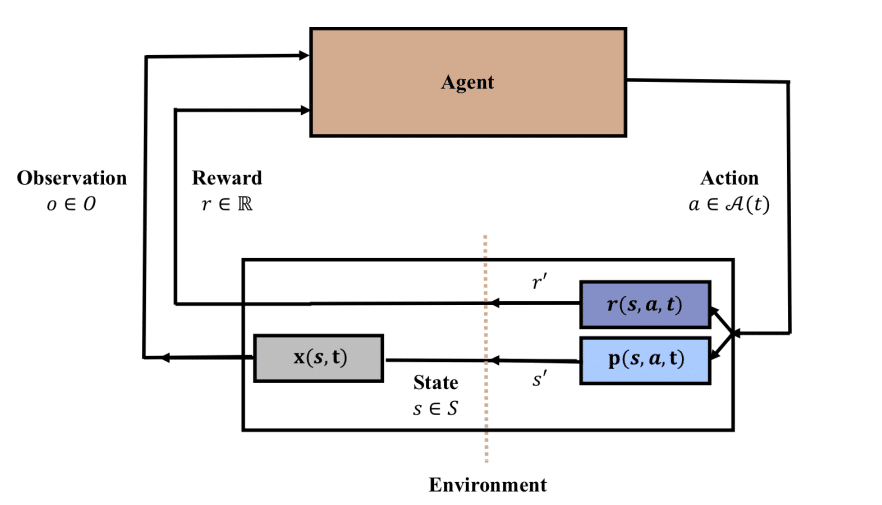
위 그림은 기본적인 강화학습의 형태를 나타냅니다. 논문의 저자들은 강화학습의 state, action, reward가 시간에 의존되는 부분을 이야기 합니다. 만약 environment가 다시는 과거로 돌아갈 수 없는 infinite 시나리오라면, 현실 세계의 기준으로 과거에 이미 지나간 상태는 다시 돌아갈 수 없기 때문에, non-stationary의 관점으로 볼 수 있습니다. 이처럼 자연스러운 시간의 흐름이 있고 과거의 능력을 유지 시켜야 하는 조건은 Continual Learning을 실험하고 검증하기에 최고의 조건입니다.
- Continual Learning
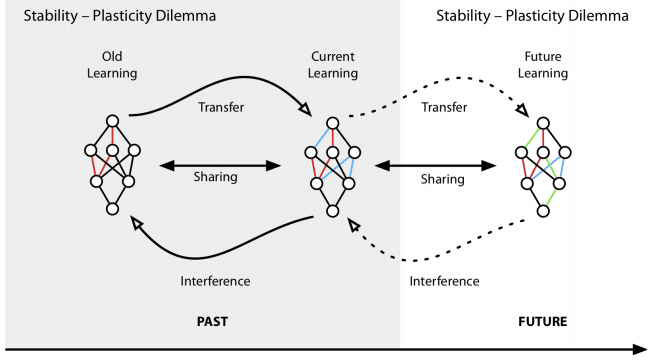
Continual Learning은 “안정성-가소성 딜레마”를 해결하는 것이 목적 입니다. 안정성을 위해 가소성을 희생 시키면 과거에 학습한 부분을 유지할 수 있지만, 그만큼 새로 학습한 지식에 대해 약할 수 있습니다. 반대의 경우 새로운 지식에 집중되며, Catastrophic Forgetting 문제가 발생할 수 있습니다. 안정성과 가소성 사이에서 과거 학습에 대한 능력을 유지하며 지속적인 새로운 학습이 가능하게 만드는 것이 Continual Learning의 핵심 입니다.
- Continual Reinforcement Learning
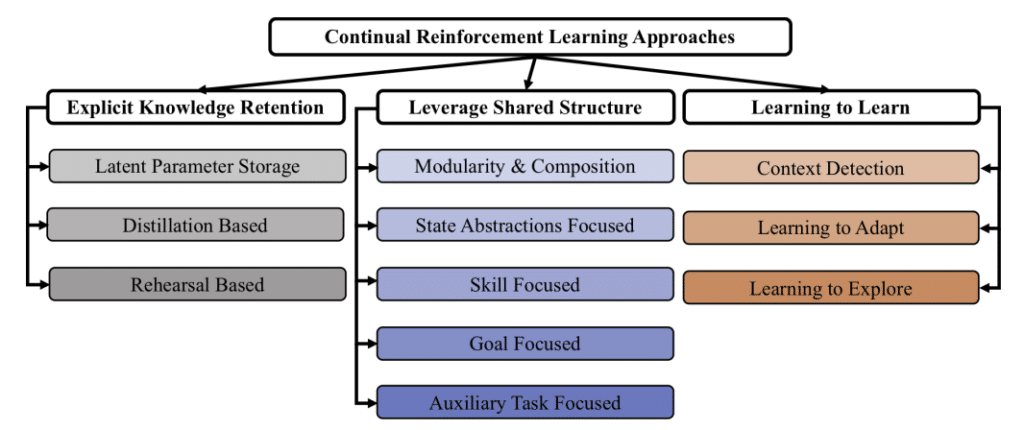
Continual RL은 크게 3가지 목표를 가지고 있습니다.
- Explicit Knowledge Retention: 학습을 하면서 발생하는 catastrophic forgetting 방지를 통해 지식을 유지하며, 안정성을 높이고 최적의 가소성을 얻을 수 있도록 합니다.
- Leverage Shared Structure: 계속해서 학습하는 AI agent의 경우 문제를 해결하기 위한 구조적인 측면과 과거에 해결한 하위 문제에서 얻은 해결책을 재사용 하며, 자동적으로 계획, 학습 및 추론으로 활용됩니다. 이처럼 공유 구조를 잘 사용하도록 합니다.
- Learning to Learn: 마지막으로 학습하는 방법 자체를 배우도록 하는 것을 목표로 합니다. 기본적으로 meta-learning과 같은 목표를 가집니다.
크게 3가지 목표를 통해 사람과 같이 과거의 지식은 유지하면서, 얻어진 지식들의 공유 구조를 파악해 재활용하고, 학습하는 방법 자체를 배워 발전하도록 합니다.
- Evaluating Continual Reinforcement Learning
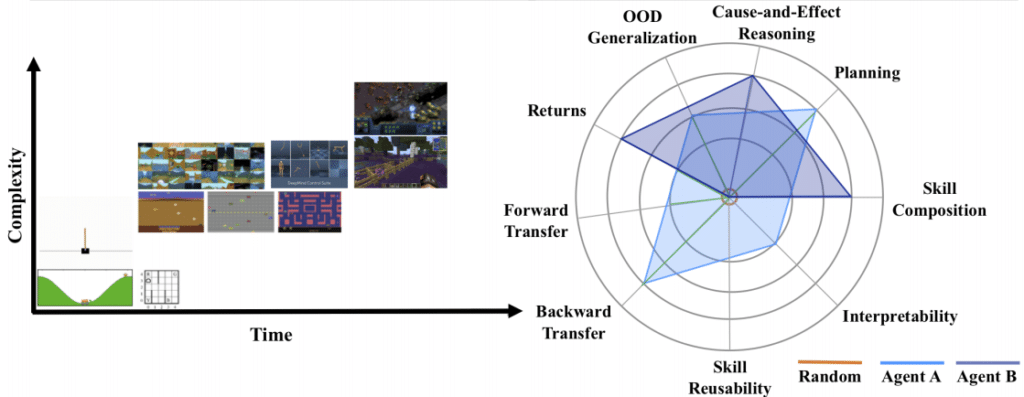
앞서 이야기한 Continual RL의 다양한 부분을 평가하기 위해, 논문에서는 Continual RL agent 평가를 위한 7가지 지표를 설명 합니다.
- Catastrophic Forgetting (Forward and Backward Transfer): AI agent가 새로운 관련된 상황에서 이전에 습득한 지식을 효과적으로 사용하는 가를 평가 합니다(Forward transfer) 현재의 상황에서 이전에 학습한 비슷한 기능의 성능을 향상 시킬 수 있는 지 평가 합니다(Backward transfer).
- Skill Reusability: 새로운 경험하지 못한 상황을 만났을 때, 이전에 배운 기술을 재사용하고 새로운 기술을 만들어 낼 수 있는 지 평가합니다.
- Interpretability: 학습된 representation, 얻어진 행동, value function, policy를 정성적으로 평가해 학습률과 점수 발전에 사용합니다.
- Skill Composition: Agent가 본 데이터를 통해 이전에 배운 것을 더 효과적으로 활용하는 지 평가합니다.
- Planning: 습득한 지식을 활용해 미래를 효과적으로 계획할 수 있는 지 평가합니다.
- Cause and Effect Reasoning: Agent가 환경에서의 규칙과 객체를 실제로 학습하고 있는 지 인과분석을 통해 측정 합니다.
- OOD (Out of Distribution) Generalization: zero-shot을 통해 Return을 예측하는 것과 샘플의 복잡성을 통해 agent의 일반화 성능을 평가 할 수 있습니다.
사람과 같은 학습 과정을 만들어 내기 위해 이번 글에서 소개한 Continual RL과 함께 lifelong learning, online learning, never-ending learning 등 다양한 분야들이 존재합니다. 최근 떠오르고 있는 continual learning과 일부 분야에서 사람의 성능을 뛰어넘는 reinforcement learning의 조합인 continual RL이 또다른 성장의 가능성을 보여줄지 지켜보면 좋을 것 같습니다.
- Reference
https://arxiv.org/abs/2012.13490






