
[선행연구팀 송지현]
MIT 연구팀이 개발한 TadGAN 알고리즘은 시계열 데이터를 분석하여 이상탐지를 하는데에 있어 기존에 알려진 모델들에 비해 좋은 성능을 내는 것으로 알려져 있습니다.
현재 많은 이상탐지를 연구하는 업체들이 다양한 분야(금융 및 우주항공 그리고 IT, 보안 및 의료 영역)에서 TadGAN을 활용하여 연구중으로 알고 있습니다.
이상 징후 탐지를 위한 현재 최첨단 비지도 학습 방법은 확장성 및 이식성 문제로 어려움을 겪고 있습니다. 이에 GAN(Generative Adversarial Network)을 기반으로 구축된 unsupervised learning 이상 탐지 접근 방식인 TadGAN 을 도입함으로 기존에 시계열 데이터 분석의 방식과는 다른 놀라운 효과를 내고 있으며 곳곳에서 많은 추가 연구가 진행되고 있습니다.
TadGAN 동작 원리[학습과 예측]
Train 데이터를 기반으로 Reconstructed data를 구축하고, 새로운 데이터가 들어오면 기 구축된 Reconstructed data와 새로운 데이터 사이에 이상 구간을 탐지하여 Anomaly error score를 계산하고 threshold에 맞게 이상탐지 구간을 탐지합니다.
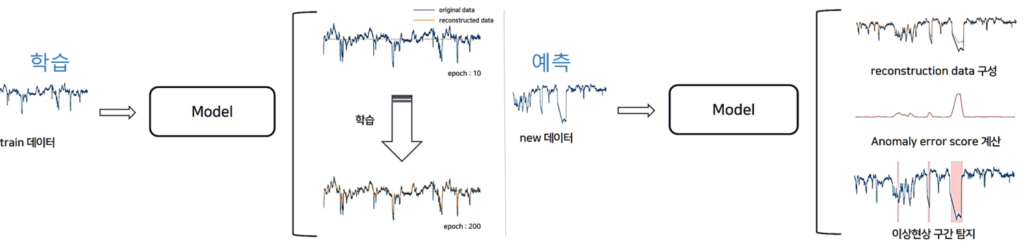
TadGAN 전체 프로세스
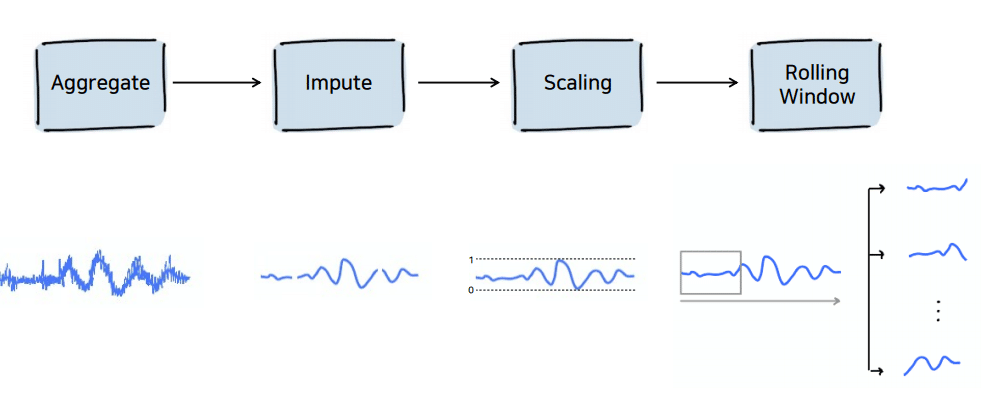
1. 데이터 전처리
정해진 초 단위로 훈련 샘플을 얻기 위해 original 시계열 데이터를 신호 세그먼트로 나누기 위해 슬라이딩 윈도우를 도입합니다.
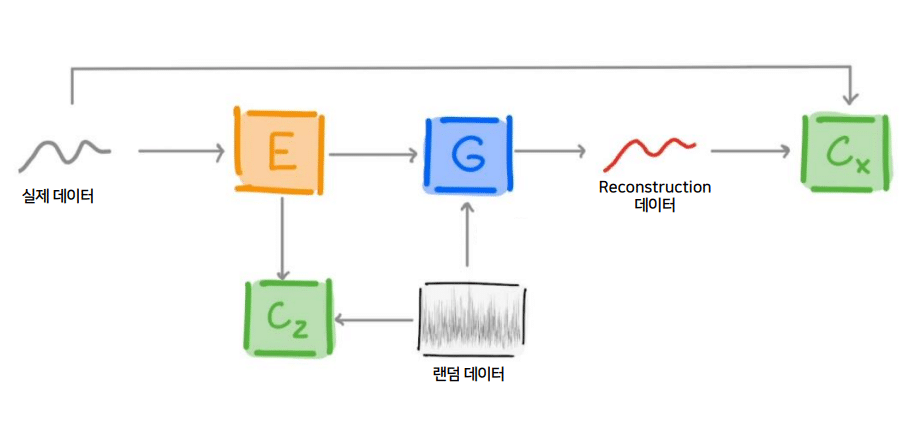
2. 모델 훈련
Critic X: 실제 데이터와 랜덤 데이터를 Generator로 바꾼 데이터를 구별하도록 훈련 / Critic Z: 램덤 데이터와 실제 데이터를 Encoder로 바꾼 데이터를 구별하도록 훈련하여 Reconstruction data 구축을 완료합니다.
3. 예측
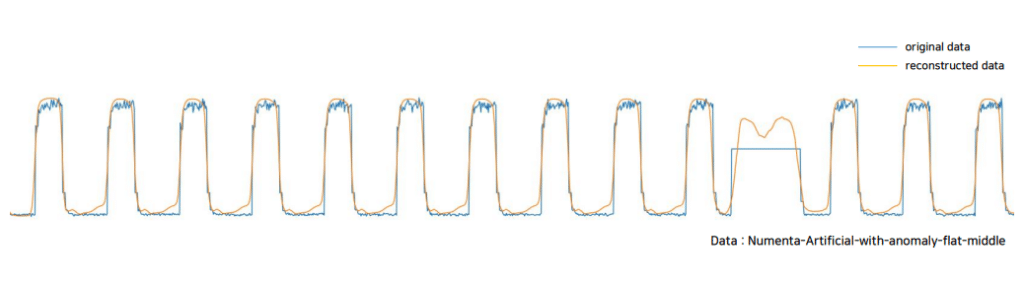
Original data 기준으로 reconstructed data가 잘 구축된 것을 볼 수 있습니다.
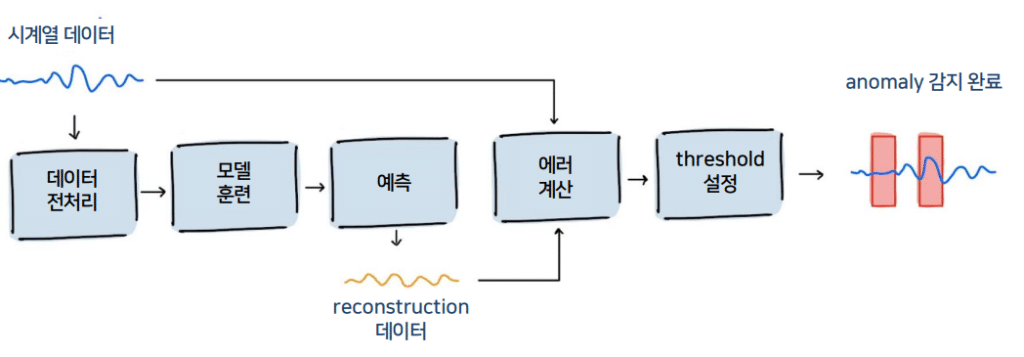
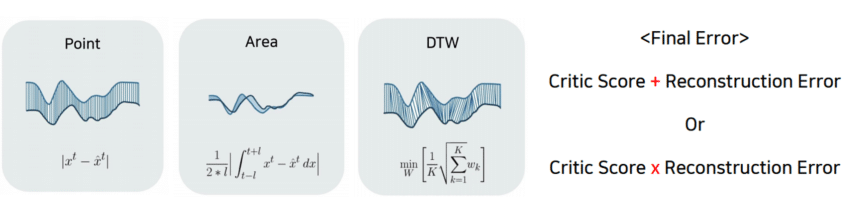
4. 에러 계산
실제 데이터와 Reconstruction 데이터의 차이를 계산하도록 합니다. Critic Score는 앞에서 훈련한 Critic 점수를 에러 계산에 활용하여 주어진 데이터가 얼마나 진짜와 비슷한지 표현하는 점수 입니다.
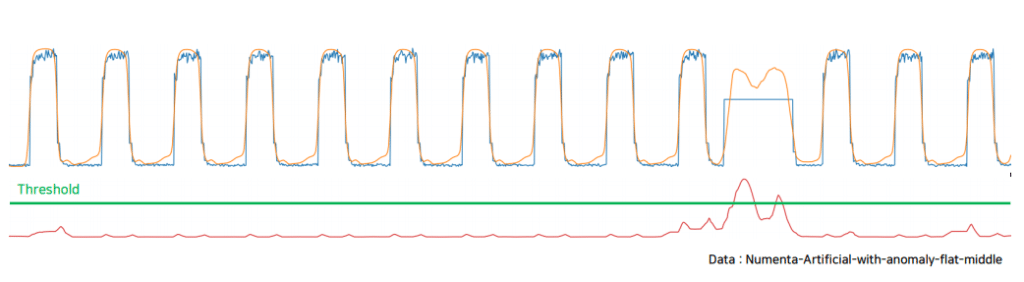
5. Threshold 설정
아래 빨간색 Error score가 threshold 기준으로 얼마나 크게 넘어섰는지를 설정하고 Anomaly의 정도를 감지합니다.
6. Anomaly 감지
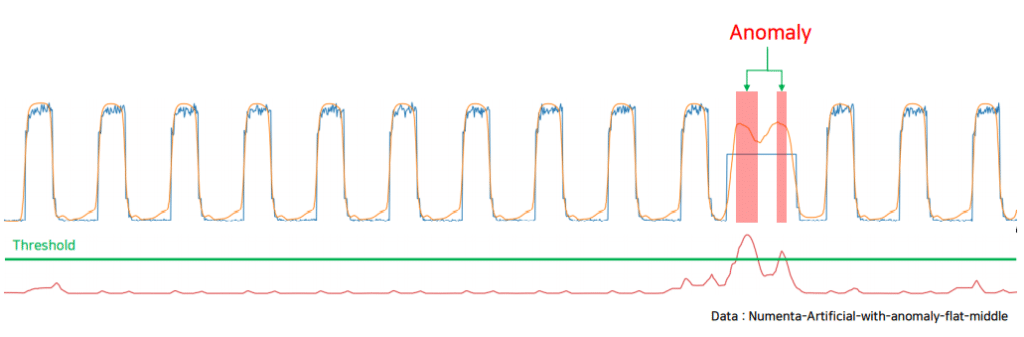
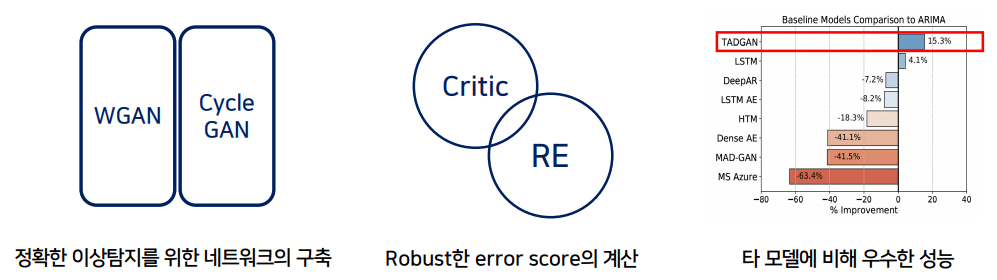
TadGAN의 우수성
Timeseries Anomaly Detection GAN, 시계열 데이터 이상탐지에 최적화된 GAN 모델로 다른 이상탐지 모델에 비해 우수한 성능을 내고 있으며 다양한 분야에 인정받고 있습니다.
TadGAN의 한계점과 성능 향상을 위한 방안
설정에 따라 크게 성능의 차이가 있고, 데이터에 따라 달라지는 최적의 설정값이 현재 모델의 한계점으로 보여지고 있습니다.
또한 unknown anomaly 를 포함한 unlabeled dataset에 대해 모델 성능을 평가할 방법이 없는 것으로 알려져 있습니다.
이를 극복하기 위해서는 Mid-range등 anomaly score의 분포 자체를 평가하는 기준의 도입으로 적용하여 성능을 평가할 방안을 마련하면 성능 평가가 가능합니다.
Raw data에 labeled anomaly case를 인위적으로 생성해서 그것을 기준으로 최적화 하면 드물어서 힘들었던 모델 최적화를 잘할 수 있습니다.
앞으로도 TadGAN을 바탕으로 어렵다고만 생각하던 시계열 데이터 분석에 발전이 있길 바래봅니다.
- 참고 : markr 2021 online seminar






