
[서비스개발팀 황준선]
기계학습 모델을 지도 학습할 때 라벨간 데이터의 개수가 불균형한 데이터셋을 훈련 데이터로 삼을 경우, 비율이 작은 라벨에 속한 샘플들에 대한 학습이 잘 이루어지지 않는 현상을 겪게 됩니다. 단순히 샘플의 개수 자체가 적다면 당연히 학습이 잘 이루어지지 않을 것이며, 샘플이 충분히 학습할만큼은 있다고 하더라도, 비율 차이가 극심하다면 모델은 편향성을 가지게 될 것입니다. 특히, 예를 들어 비정상 데이터를 분류하는 문제거나 분류해야되는 라벨이 너무 많은 문제인 경우에 흔히 발생하는 현상입니다. 이러한 경우에 아무리 좋은 state-of-the-art 모델을 사용한다고 하더라도, 제대로된 성능을 이끌어내기 힘들어집니다. 이러한 문제를 해결하기 위한 방법으로 크게 4가지가 있습니다.
- 적절한 평가 지표 사용
불균형 데이터셋 문제를 직접적으로 해결하는 방법에 속한다기 보다, 현재 학습된 모델을 정확히 해석 및 파악하여 후술할 해결 방법을 적용하기 위한 첫걸음이라고 할 수 있습니다. 예를 들어, 라벨 0과 1을 이진 분류하는 문제이며, 전체 데이터셋 대비 라벨 0에 속하는 샘플 비율이 99%, 라벨 1에 속하는 샘플 비율이 1%라고 가정해보겠습니다. 만약 학습된 모델이 모든 데이터를 0으로 분류한다고 한다면, 이 모델의 정확도(accuracy)는 99%가 될 것입니다. 이 accuracy가 틀린 지표는 아니지만, 과연 이 99%라는 성능 지표가 이 모델의 성능을 제대로 이야기해줄 수 있을까요? 보편적으로 우리는 이러한 데이터에서 0을 정확히 분류하는 것이 아니라 1을 정확히 분류하고 싶어합니다. 그렇다면, 이 지표는 가치있다고 할 수 없을 것입니다. 따라서 accuracy 뿐만 아니라 여러가지 측면을 볼 수 있는 다음과 같은 평가 지표[1]를 사용하는 것이 좋습니다.
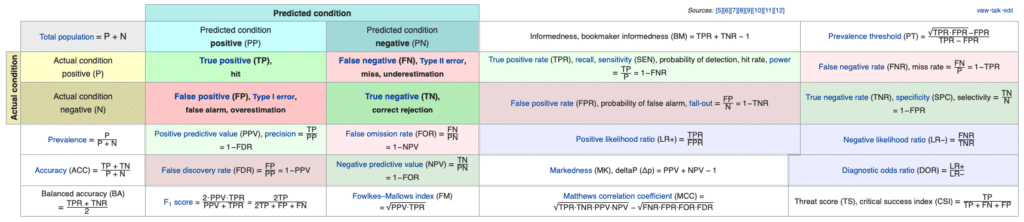
- 정밀도 (Precision): True Positive / (True Positive + False Positive); 모델이 True라고 분류한 것 중에서 실제 True인 (맞춘) 비율
- 재현율 (Recall): True Positive / (True Positive + False Negative); 실제 True인 것 중에서 모델이 True라고 예측한 (맞춘) 비율
- F1 score: 2 * Precision * Recall / (Precision + Recall); 정밀도와 재현율의 조화 평균
- ACU: 모든 임계값에서 분류 모델의 성능을 보여주는 그래프인 ROC 커브의 아래 영역 넓이를 의미
위 지표들 중에서 비율이 적은 라벨에 대한 정밀도와 재현율이 굉장히 낮게 나오는 것을 확인할 수 있습니다. 즉, 해당 라벨에 대한 학습이 잘 이루어지지 않은 것입니다.
- 학습 데이터셋 샘플링
위 평가 지표를 통해 모델의 학습이 잘 이루어지지 않았다고 판단될 경우, 가장 먼저 간단하게 적용해볼 수 있는 전략입니다. 라벨간 비율을 맞춰주는 방법으로 불균형 문제를 해결할 수 있습니다.
- Under-sampling[2]: 많은 비율을 차지하는 샘플의 개수를 줄여서 균형 데이터셋을 만드는 것, 데이터의 양이 충분할 때 사용할 수 있는 방법.
- Over-sampling[3]: 적은 비율을 차지하는 샘플의 개수를 늘려서 균형 데이터셋을 만드는 것, 데이터의 양이 충분하지 않을 때 사용할 수 있는 방법. (ex. repetition, bootstrapping, SMOTE, ROSE)
위 두가지 방법을 적절히 조합하면[4] 더 좋은 샘플러를 만들 수 있을 것입니다. 그리고 딥러닝 프레임워크로 흔히 사용하는 PyTorch에 적용 가능한 Imbalanced Dataset Sampler[5]가 공개 되어있으니 참고하면 좋을 것 같습니다. 하지만, 분류하고자 하는 라벨에 속한 데이터가 극도로 적어 학습하기에 충분하지 않은 경우 샘플링 방법만으로 해결이 불가능할 수 있습니다.
- 데이터 증가 (Augmentation)
데이터의 수가 극도로 적은 경우에 사용할 수 있는 방법입니다. 하지만, 이러한 데이터 증가 방식은 도메인에 따라 태스크에 따라 적용 여부와 방법이 갈라질 것입니다.
- Image Augmentation

- Text Augmentation
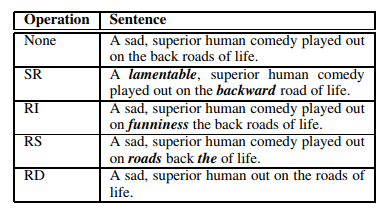
위 예시는 이미지와 텍스트 데이터에 대해 보편적으로 적용하는 Data Augmentation 기법입니다. 이미 비율이 많은 라벨이 아닌 비율이 적은 라벨의 샘플들은 Augmentation하여 학습에 사용하면 성능을 올릴 수 있습니다.
- 불균형 데이터셋을 위한 손실 함수 사용
마지막으로, 불균형 데이터에 맞는 손실 함수를 사용하는 것입니다. 불균형 데이터에 가장 대중적으로 사용하는 손실 함수 중 하나는 Focal Loss[6]입니다. 이 외에도 여러가지 손실함수가 존재하며, CVPR 2021에서 소개될 LADE Loss[7]도 있습니다.
- Focal Loss: 분류 에러에 근거하여 손실값에 가중치를 부여하여 해결
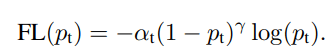
LADE Loss: 불균형 학습 데이터의 라벨 분포를 타겟 데이터의 라벨 분포로 변화(Distribution Shifting)하여 해결
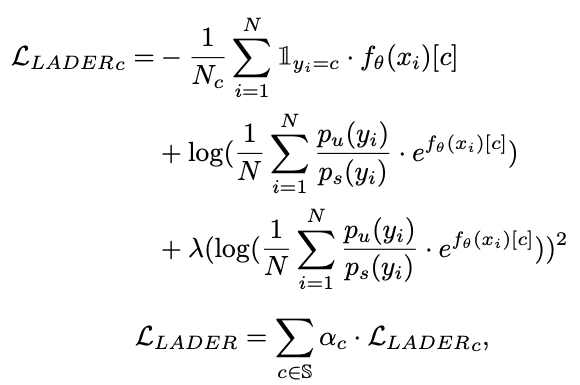
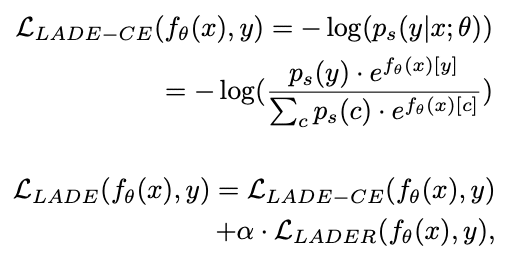
서술한 방법보다 더 근본적인 해결 방법은 데이터셋을 더 확보하는 것입니다. 하지만 적절한 데이터셋을 수집하는 것과 라벨링 작업에 드는 비용이 상당합니다. 해결하고자 하는 문제에 동원되는 데이터셋의 양이 기계학습 모델을 학습시킬만큼 충분히 확보되지 않는다면 위 모든 방법을 동원해도 해결하지 못할 수 있습니다. 데이터셋이 충분하지만, 불균형이 심한 경우 위의 방법을 적용하여 성능을 이끌어낼 수 있을 것입니다. 마지막 방법인 손실 함수를 사용한 방법을 코드로 공유하고 포스팅을 마치겠습니다.
https://github.com/Joonsun-Hwang/imbalance-loss-test/blob/main/Loss%20Test.ipynb
[1] https://en.wikipedia.org/wiki/Precision_and_recall
[2] https://imbalanced-learn.org/stable/under_sampling.html
[3] https://imbalanced-learn.org/stable/over_sampling.html
[4] https://imbalanced-learn.org/stable/combine.html
[5] https://github.com/ufoym/imbalanced-dataset-sampler
[6] https://arxiv.org/abs/1708.02002
[7] https://github.com/hyperconnect/LADE






