
[선행연구팀 심홍매]
Open AI의 GPT-3, NAVER의 Hyper CLOVA 와 같은 초 거대 언어 모델이 공개되면서 최근에는 이를 활용한 다양한 사례 및 서비스들도 많이 쏟아져 나오고 있습니다. 이와 같은 초 거대 언어 모델들은 모두 gradient 업데이트 없이도 새로운 Task(=작업)와 관련된 간단한 예시들을 제시해주는 것 만으로도 새로운 Task를 수행하는 방법을 스스로 배울 수 있다는 놀라운 능력을 갖고 있습니다. 하지만 이러한 언어 모델들은 텍스트 기반의 Task들은 잘 수행하는데 반해, Visual Task와 같은 텍스트 이외의 Task들에 대해서는 실력을 충분히 발휘하지 못하고 있습니다.
최근 DeepMind에서는 자기 회귀 언어모델 대상으로 Visual Task를 수행할 수 있는 Frozen이란 방법을 논문을 통해 공개하였습니다. 해당 논문에서는 few-shot learning 능력을 “multi-modal”로 이전하는 간단하고 효과적인 방법을 제안하였습니다. 이미지-캡션 페어 데이터를 이용하여 각 이미지를 연속적인 임베딩의 시퀀스로 나타낼수 있도록 vision encoder를 학습함으로써 pre-trained, frozen 언어 모델이 이 prefix 정보를 이용하여 적절한 캡션을 생성 할 수 있도록 하였습니다.
그림 [1]은 논문에서 소개하는 vision encoder가 포함된 전체 시스템 구조입니다. 그림에서 2개의 Language Model의 매개변수는 고정되어 있고 변하지 않은 Frozen 상태입니다. Vision Encoder는 왼쪽의 이미지 인코딩 정보와, 오른쪽 캡션의 일부 인코딩 정보를 이용하여 Language Model(Self Attention Layers) 이 캡션의 남은 부분을 생성 할 수 있게 학습을 하도록 되었습니다. 언어 모델의 가중치는 고정된 상태로 유지되지만 gradient 는 이미지 인코더를 처음부터 훈련하기 위해 이를 통해 역 전파됩니다.
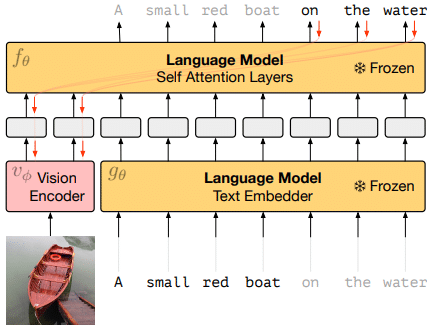
위의 구조를 이용하여 학습 완료 된 Frozen을 본 논문에서는 multimodal few-shot learner 라고 부르고 있습니다. Frozen은 단일 이미지-캡션 쌍으로 학습되지만 일단 학습되면 여러 이미지와 텍스트로 정렬된 세트에도 효과적으로 대응할 수 있습니다. 뿐만 아니라, 사전 훈련된 언어 모델을 활용하여 VQA(시각적 질문 답변)와 같이 훈련되지 않은 multi-modal tasks에서도 새로운 작업을 학습하는 놀라운 능력을 갖고 있습니다. 논문에서는 multi-modal task에서의 frozen의 few-shot learning 성능을 향상하기 위하여 여러 Task 대상으로 shot 들을 비교하면서 실험을 진행하였습니다.
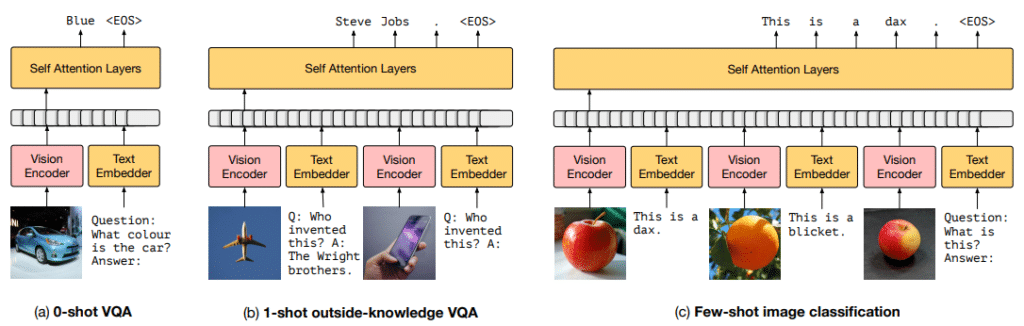
아래 그림 [3] 은 Frozen 모델에 위의 실험을 통해 얻은 최적의 세팅을 적용한 후 테스트 데이터 대상 테스트한 결과입니다. 그림의 첫번째 라인을 보면, 2개의 이미지와 캡션을 예시로 넣고 마지막에 이미지와 “해당 사람은 어떤 사람인지”란 텍스트 정보를 제시어로 해주면, 모델은 최종 겁에 질린 “공포”emoji를 생성해줍니다. 두번째 라인도 비슷한 형식의 예시를 넣어주는데요, 여기서 이미지 정보로는 “비행기”라는 정보만 얻을 수 있지만 언어 모델에 사실적 지식도 포함되어 있어 최종 모델은 비행기를 발명한 사람에 대하여 “라이트 형제”라는 답변을 생성해줄 수가 있습니다. vision 정보와 언어 모델의 사실적 지식 정보를 결합하여 이와 같은 Task를 수행 할 수 있는 게 Frozen의 매력 포인트라고 할 수 있습니다.

Frozen을 개발하는 목표는 특정 Task에서 성능을 최대화하는 것이 아니었기에 작업을 수행함에 있어서 필요한 능력은 갖추고 있지만, few-shot으로 학습하는 특정 Task에 대한 SOTA의 성능과는 아직 차이가 있습니다. 하지만 벤치마크에서 제공하는 필요한 교육 예시를 다 보지 않고도 다양한 Task들에서의 성능이 기준선을 훨씬 능가하고 있습니다. 또한 그림 [3]에서 볼 수 있듯이 Frozen은 종종 매력적인 출력을 생성함으로써, 이는 이미지에 대하여 진정으로 개방적이고 제약이 없는 언어적 해석을 하기 위한 시스템으로 볼 수 있습니다.
지금까지 Frozen를 이용하여 대규모 언어 모델을 multimodal few-shot learning 시스템으로 변환하는 방법을 소개해드렸습니다. 좀 더 자세한 사항은 논문을 참조하면 됩니다.
Reference
[1] Tsimpoukelli, M., Menick, J., Cabi, S., Eslami, S. M., Vinyals, O., & Hill, F. (2021). Multimodal Few-Shot Learning with Frozen Language Models. arXiv preprint arXiv:2106.13884.
[2] https://www.youtube.com/watch?v=FYA_jwPpXi0






