
[선행연구팀 최현우]
지난 5월 딥마인드는 ‘Reward is Enough’라는 제목의 강화학습 논문을 발표했습니다. 저자들은 ‘포만감을 높이려는 다람쥐’와 ‘청결을 유지하려는 주방로봇’의 예시를 들어, 적절한 보상이 정의된다면 이를 극대화하는 과정에서 지능과 관련된 (인지, 기억, 계획, 운동 등의) 다양한 능력을 자연스럽게 활용하고 의사 결정을 내릴 수 있다고 주장하였습니다.

사람들도 무언가를 달성하기 위한 상황 판단 및 의사 결정 능력은 다양한 시행착오를 통해 스스로 터득하게 되는 경우가 많습니다. 강화학습 자체가 이러한 사람의 학습 원리와 유사하기 때문에, 적절한 보상 체계가 AGI를 달성하는 데에 핵심적인 역할을 할 것이라는 이러한 주장도 어느 정도 논거를 갖추고 있습니다. 다만 다소 도발적(?)이기까지 한 제목 때문이었을지는 몰라도 ‘실체가 없는 주장이다’, ‘실생활의 문제는 명확한 보상을 정의하기 어렵다’와 같은 회의적인 시각들도 여럿 나타나고 있었습니다.
XLand: 새로운 강화학습 환경
사실 Reward is Enough는 구체적인 구현 결과가 포함되지 않은 주장이었기 때문에 더 많은 공격을 받았던 걸 수도 있겠습니다. 이러한 시선을 의식이라도 한 듯 최근 딥마인드에서 XLand라는 새로운 강화학습 환경에서의 실험 결과를 발표했습니다.
현재 AI 연구는 사전학습 된 모델을 원하는 task에 맞게 미세조정하는 방식으로부터, 적은 데이터로도 성능을 확보하는 few-shot, 심지어 zero-shot learning까지 나아가고 있습니다. 반면에 강화학습은 새로운 작업을 배우기 위해 사전학습 된 모델을 활용하지 못하고 항상 처음부터 학습을 다시 해야 하는 치명적인 단점을 가지고 있는 것처럼 보였습니다. 이러한 배경에서, 강화학습도 한번 습득한 지식을 일반화하여 새로운 task에도 적용할 수 있다! 라는게 이번 발표의 핵심적인 결과입니다. 확실히, 새로운 task에 대해 효율적인 학습이 가능하다면 이는 AGI에 상당히 근접한 형태라고 여길 수 있을 것 같습니다.

저자들은 이를 입증하기 위해 강체 물리학 시뮬레이션이 가능한 XLand 엔진을 구축하고, 에이전트를 교육하기 위한 다양한 환경과 목표를 자동으로 생성하였습니다. 에이전트가 “보라색 큐브 근처”로 가는게 목표일 수도 있고, “보라색 큐브 근처에 있거나 노란색 구체를 빨간색 바닥에 놓기”와 같은 더 복잡한 목표가 주어질 수도 있습니다. “상대방을 보고 상대방이 나를 보지 못하게 하는” 숨바꼭질과 같은 경쟁적인 목표도 존재합니다.
각 에이전트는 XLand 내 4,000개의 고유한 세계에서 약 700,000개의 고유한 게임을 플레이했으며, 340만 개의 고유한 작업에 걸쳐 2,000억 단계의 학습을 거쳤습니다. 그 결과 사전에 학습하지 않은 새로운 task에 대해서도 약 30분의 미세조정 만으로 상당한 성능을 확보할 수 있다는 것을 보여주었습니다. 반면에 처음부터 학습한 모델에서는 성능이 거의 0으로 나타났습니다(비교 대상이 2,000억 건의 학습을 했으니 어떻게 보면 당연한 결과이긴 하겠지만요).
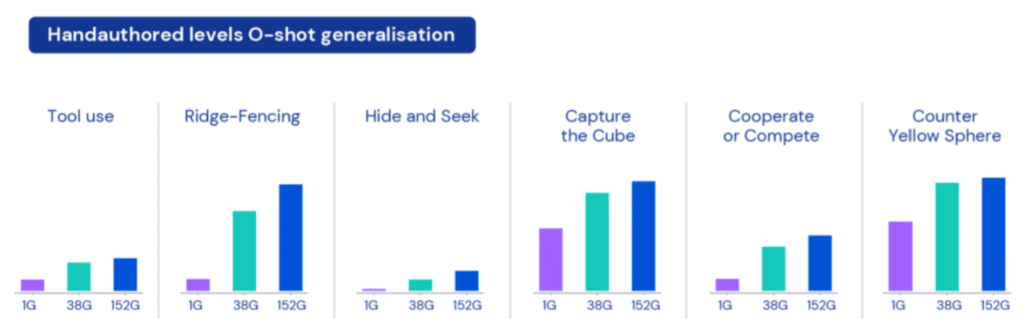
저자들은 각각의 문제를 풀기 위해 에이전트가 취하는 행동들이 우발적으로 보일 수는 있지만 그럼에도 일관적으로 나타나며, 이는 에이전트가 보상 체계를 명확하게 이해하고 있는 것이라고 주장합니다.
강화학습은 AGI가 될 수 있을까
상술한 바와 같이 저자들은 사전학습 된 강화학습 모델이 다양한 신규 task에 대해 빠르게 적응할 수 있다는 가능성을 보여주었습니다. 하지만 여전히 real world 문제를 굉장히 단순화시켰을 뿐이라는, 기존의 비판적인 시각들을 돌파하기는 다소 어려울지도 모르겠습니다.
저자들도 학습이 잘 되지 않은 실패 사례를 논문 내에서 몇 가지 소개하였는데 이 부분이 상당히 흥미롭습니다. 먼저 사전학습에서 등장하지 않았던 균열(함정)이 등장할 경우, 에이전트는 자신이 함정에 빠질 수 있다는 가정을 하지 못해 계속 목표에 도달하지 못하는 모습을 보여주었습니다. 주변 오브젝트를 이용해 경사면을 만들어 윗층으로 가는 문제는 풀 수 있지만, 여러 층의 경사를 연속으로 만들어야 하는 문제는 풀지 못합니다(이 부분은 확실히 시행착오의 차원이 너무 커져서 풀지 못하는, 강화학습의 한계가 나타나는 것 같습니다). 또한 두 에이전트의 목표가 다를 경우, 상대 에이전트의 목표를 이해하지 못해서 자신의 목표도 달성하지 못하는 상황에 처하기도 하였습니다.
강화학습이 사람의 학습 패턴을 따라한 기법인데도, AI가 풀기 어려운 문제를 어떻게 사람은 쉽게 풀 수가 있는지 신기한 부분이 참 많은 것 같습니다. 에이전트의 행동 선택지가 적은 시뮬레이션 환경에서도 2,000억 건의 학습을 거쳤다는 점에서 아직까지 AGI를 주장하기에는 그 한계가 뚜렷해 보이기도 합니다.
그럼에도 강화학습 모델을 유연하게 사용할 수 있는 방법을 (아마도) 최초로 보여줬다는 점 만으로도 많은 진전을 보여줬다고 생각할 수도 있겠습니다. 후속 연구에서 실패 사례들을 해결할 단서를 찾을 수 있을지 대단히 궁금해지는 상황입니다 🙂
References
- https://deepmind.com/research/publications/2021/Reward-is-Enough
- https://deepmind.com/blog/article/generally-capable-agents-emerge-from-open-ended-play






