
[선행연구팀 유희조]
번역은 딥러닝 붐이 일던 초기부터 연구되던 주제입니다. 지금은 어느 분야에서든 사용되는 attention 역시 최초는 Seq2Seq 구조가 갖는 문제를 해결하기 위해 제안된 방법이었습니다. 근 10여년 간 딥러닝 기반 번역기의 성능은 꾸준히 개선되어 왔고 이런 번역기 성능의 개선은 언어에 의한 장벽을 많은 부분 해소시켜주었습니다.
현재의 번역 기술은 대부분 text-to-text에 포커스를 맞추고 있습니다 (text-to-text translation, T2TT). 그리고 텍스트의 추상성은 모델을 일정 수준까지 끌어올리는데는 큰 도움이 되지만 대화 내의 다양한 비 언어적 요소를 사라지게 하는 문제가 있습니다. 특히 대화에서 이런 문제는 두드러지게 나타나게 됩니다. 언어가 다른 두 사람이 대화할 때 번역기를 이용한다면 우리는 통상 ‘L1 speech → L1 recognition (L1 text) → L1L2 translation (L2 text) → L2 TTS (L2 speech)’와 같은 과정을 거치게 됩니다. 인식과 번역을 거치면서 사라지는 비언어적 정보들은 현재의 번역기로는 해소되기 어려운 장벽이 되고 있습니다.
이와 같은 문제에 대한 해결책으로 Google은 2019년에 Translatotron을, 그리고 이번 7월에 Translatotron 2 를 공개했습니다. Translatotron과 기존의 번역 모델과 가장 큰 차이점은 speech-to-speech에 포커스를 맞추고 있다는 점입니다 (speech-to-speech translation, S2ST). 모델을 발표한 논문은 S2ST가 T2TT에 비해 L1의 비언어적 정보를 그대로 음성 산출에 반영할 수 있다는 점, 그리고 연산 과정 등의 감소로 인한 시간 및 오류 감소 등의 장점을 가지고 있다고 이야기하고 있습니다.
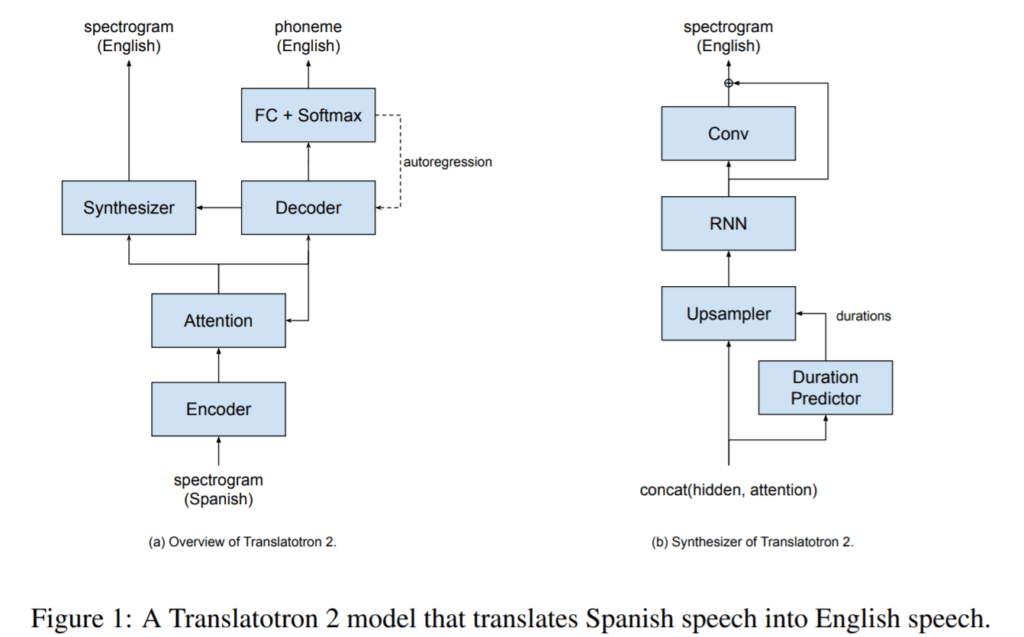
Translatotron 2의 대략적인 구조는 ASR과 TTS를 혼합한 모델에 가깝습니다. L1의 음성 정보(mel-spectrogram)를 입력받아 L2 phoneme을 decoder로 예측하고 (ASR), 동시에 L2 phoneme을 산출하기 전의 decoder 출력과 attention을 결합하여 synthesizer를 통해 L2 mel-spectrogram을 예측합니다 (TTS). 따라서 L1 phoneme은 모델에서 고려되지 않습니다.
물론 이와 같은 구조는 S2ST 기술이 아직은 넘어야 할 장애물이 많다는 것을 보여주고 있습니다. 제안된 모델은 text 산출을 위한 decoder를 거침으로써 목표로 하는 speech-to-speech보다는 speech-to-text-to-speech의 구조에 가까워졌습니다. 거기에 L1과 L2의 차이의 정도에 따라서 모델의 퀄리티 또한 달라질 가능성이 높습니다. 특히 decoder를 위해 사용된 attention은 한국어와 같은 어순이 다른 언어에서는 훨씬 더 낮은 퍼포먼스를 보일겁니다. 하지만 그럼에도 불구하고 이런 모델들은 ‘딥러닝이 언젠가 우리가 겪는 수많은 언어의 장벽을 언젠가 뛰어넘을 수 있도록 해주는 것이 아닐까?’ 라는 기대 또한 들게 만듭니다.
Reference
Jia, Y., Ramanovich, M. T., Remez, T., & Pomerantz, R. (2021). Translatotron 2: Robust direct speech-to-speech translation. arXiv preprint arXiv:2107.08661.
Jia, Y., Weiss, R. J., Biadsy, F., Macherey, W., Johnson, M., Chen, Z., & Wu, Y. (2019). Direct speech-to-speech translation with a sequence-to-sequence model. arXiv preprint arXiv:1904.06037.






