
[융합연구팀 심홍매]
NLP 분야에서 2020년 Top 10 키워드를 뽑는다면 GPT-3(Language Models are Few shot Learners) 당연히 순위 내에 있을 겁니다. 현재까지도 GPT-3의 엄청난 양의 매개변수와 우수한 성능은 여전히 NLP 분야 내외를 막론하고 인기를 더해가고 있습니다. 그러나 NLP 연구원으로서 최첨단 연구에 대한 GPT-3의 가장 큰 기여는 일반 작업( 특히 zero-shot , few-shot ) 에서 Prompt-tuning 기술의 응용 가능성을 입증한 것이라고 생각합니다. GPT-3 이전에는 Prompt-tuning이 주로 언어 모델에 포함(잠재)된 지식을 탐색하는 데 사용되었다면 GPT-3 이후 Prompt-tuning은 다양한 유형의 NLP Task (멀티 모달 Task, 코드 작성 Task 등)에 사용되었으며 지난 2년 동안 아주 핫한 키워드로써 관련 논문들이 많이 쏟아져 나왔습니다.
Prompt-tuning과 GPT-3의 상호 이루어낸 성취는 NLP 개발의 역사에서 무시할 수 없다고 생각합니다. Prompt-tuning 기반의 GPT-3는 다양한 유형의 Task를 수행하는데 있어서 좋은 성능을 냈지만 생각해보면 이처럼 놀라운 Task 들을 수행할 수 있는 GPT-3에 더 좋은 zero-shot , few-shot 학습 능력이 있지 않을까? Prompt-tuning 이 GPT-3를 사용하는 가장 좋은 방법인가?하는 궁금증들을 한번쯤은 가지게 될 것입니다.
최근 Google 연구원들은 GPT-3(175B) 보다 적은 매개변수(137B)를 사용하여 25개 Task 중 19개 Task에서 GPT-3을 크게 능가하는 Istruction Tuning (명령/지침 조정)방법인 FLAN (Finetuned LANguage Models are zero-shot Learners)을 제안함으로써 GPT-3가 더 강해질 수 있음을 알렸습니다.
GPT-3 ( LANguage Models are zero-shot Learners)과 비교 시 FLAN의 차별 성은 바로 finetune에 있습니다. FLAN의 핵심 아이디어는 다양한 NLP Task를 Natural Language Instructions 형태(일종의 Task 명령 혹은 지침)로 변형해서 이러한 과제를 풀도록 fine-tuning 하는 것입니다. (아래 [그림 1] 내의 (C) 참고)
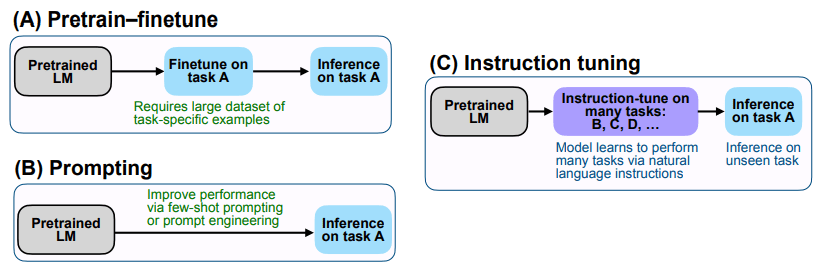
좀 더 자세히 설명을 드리면 FLAN은 먼저 Pretrained LM을 번역, 상식 추론, 감정 분류 등을 포함한 많은 다양한 NLP Task를 수행할 수 있도록 fine-tuning 합니다. 예를 들면 아래 [그림 2]과 같이 번역 Task에 대해서는 “Translate this sentence to Spanish” 를, 감정 분류 Task에 대해서는 “Is the sentiment of this movie review positive or negative?”라는 명령/지침을 이용합니다. 모델이 이러한 명령어/지침이 포함된 정보를 이용하여 다양한 Task를 수행할 수 있도록 fine-tuning 완료하면, 최종 학습을 안 한 추론 Task인 “Does the premise entail the hypothesis?”라는 명령에 대해서도 기존 지식을 더 잘 활용하여 답할 수 있습니다.
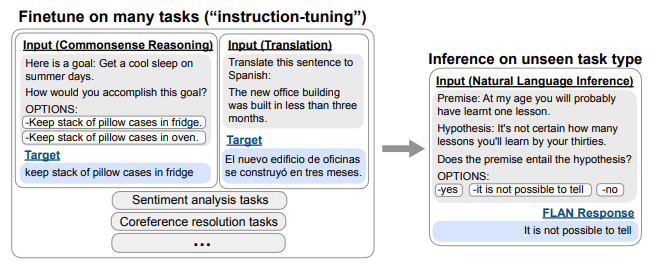
논문에서 저자들은 FLAN이 웹 페이지, 프로그래밍 언어, 대화 및 Wikipedia 문장에 대한 학습 후 명시적으로 학습되지 않은 Task에 대해서도 작동하는 방법을 학습 할 수 있음을 발견했습니다. 이처럼 Instruction Tuning은 모델에게 일종의 명령/지침으로 표현된 NLP Task를 수행하는 방법을 가르쳐서 자연어를 처리하고 이해하는 능력을 향상 시킬 수 있습니다. 즉, 자연어의 진정한 의도를 부분적으로 이해할 수 있음을 의미합니다.
FLAN의 논문에서는 12개의 카테고리와 총 62개의 공통 자연어 처리 및 생성 Task 관련 데이터를 선택하여 tuning 실험을 수행했습니다. ([그림 3] 참고)
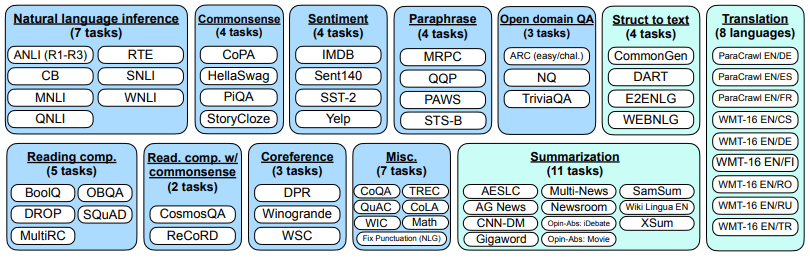
저자들은 기본 언어 모델로 137B 크기의 자기 회귀 언어 모델(Base LM)을 이용하였습니다. Instruction Tuning 파이프라인은 60개 이상의 nlp task들에 대한 모든 데이터 세트를 혼합하고 각 데이터 세트에서 샘플을 무작위로 추출합니다. 각 데이터 세트의 샘플 수는 크게 다르며 일부 데이터 세트에는 천만 개 이상의 훈련 샘플(예: 번역)이 있어서 최종 각 데이터 세트의 학습 예제 수는 30,000개로 제한하였습니다. 실험에서는 T5-11B 및 GPT-3을 기준 모델로 사용했습니다.
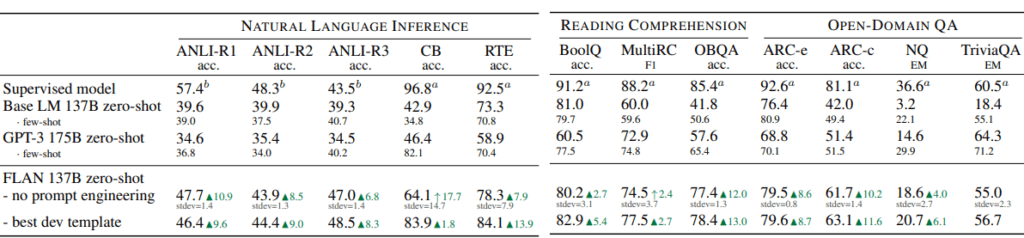
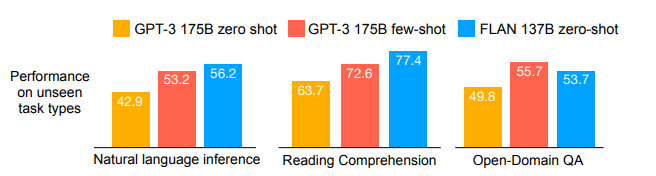
실험 결과 자연어 추론 Task 및 QA Task에서 FLAN은 zero-shot 시나리오에서 이미 few-shot GPT-3보다 결과가 좋았으며 많은 Task에서는 Supervised model과 비슷한 성능을 달성했습니다.(아래 [그림 4], [그림 5] 참고.) 이 외의 다양한 Task에 대한 실험 결과들도 논문에 포함되어 있으니 필요하시면 직접 논문을 확인 바랍니다.
NLP 관련 분야에 익숙한 분들은 이 글이 또 다른 “A+B” Task(A=prompt tuning, B=Multi-task Learning)이라고 생각할 수도 있습니다. 그러나 이러한 A+B가 향후 일반 자연어 처리 모델을 수행하는 솔루션/방법이 될 수 있다고 생각합니다. 첫째, 많은 양의 레이블이 지정되지 않은 말뭉치를 통해 수천억 개의 매개변수가 있는 대규모 자기 회귀 사전 훈련 모델을 훈련하거나 혹은 기 존재하는 훈련 모델을 선택하고 , 두 번째 단계에서 이러한 모델은 Instruction Tuning을 통해 이해와 생성 Task를 fine-tuning 할 수 있습니다. fine-tuning 과정에서 코스 학습과 유사한 방법을 사용하여 먼저 하위 수준 Task(예: NER 식별, 시퀀스 시멘틱 어노테이션)을 학습한 다음 상위 수준 Task(예: 논리적 추론, QA)을 학습할 수 있습니다. 또한 먼저 리소스가 풍부한 Task(예: 영어/빅 데이터 Task)를 배운 다음 더 적은 리소스(예: 기타 언어/적은 데이터 Task)를 학습하고 Adapter를 이용하여 모델의 Task별로 관련 부분을 유지합니다. 마지막으로 모델이 새 데이터와 새 Task에 대해 추론할 수 있도록 명령/지침을 제공합니다. 이러한 versatile한 방법은 충분히 활용한다면 또 어떠한 새로운 Task들을 수행 할 수 있을 지 기대가 됩니다.!
참고 문헌:
https://arxiv.org/pdf/2109.01652.pdf






