

[선행연구팀 김성현]
자연어처리 분야에서 pre-trained language model (PLM) 전략이 훌륭한 성공을 거두자, 더 많은 데이터를 이용해 더 큰 PLM을 개발하는 것이 하나의 트랜드로 자리잡았습니다.
그리고 얼마 전, NVIDIA에서는 GPT-3의 무려 4배 가까이 되는 530B개의 파라미터짜리 모델을 공개했습니다.
이 모델은 기존의 Megatron-LM 모델과 Turing-NLG 모델을 결합하여, “Megatron-Turing NLG” (MT-NLG) 라는 이름으로 명명됐습니다.
모델의 학습은 DGX A100 80G 서버 560대를 하나의 클러스터로 묶어서 학습했다고 합니다. 정말 NVIDIA가 아니고서는 실험도 불가능할 정도의 모델이네요!
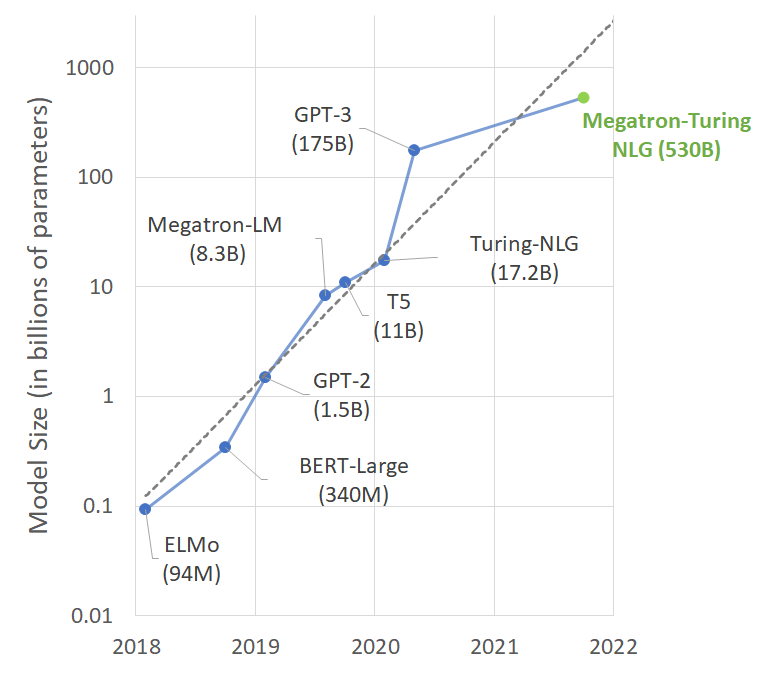
총 105개의 transformer layer로 구성되어 있고, zero-, one- 그리고 few-shot learning task에서 최고의 성능을 보였다고 합니다.
이렇게 큰 모델을 학습하는데는 단순히 많은 돈, 많은 데이터, 많은 GPU만을 필요로 하지 않습니다.
아래의 문제들 때문인데요, 우선 (1) GPU의 메모리는 한정되어 있고, 엄청 큰 hyper parameter를 모두 학습하는데는 절대 충분하지 않습니다. (2) 학습 알고리즘 최적화, 데이터 처리 방법, 소프트웨어-하드웨어 최적화를 모두 고려하지 않으면, 비현실적으로 학습시간이 오래 걸릴 수 있습니다.
이번에 공개된 MT-NLG의 경우, Microsoft와 NVIDIA가 협업하여 전례없는 모델 학습 효율을 달성해서 만들어낼 수 있었다고 합니다 🙂
즉, 하드웨어와 소프트웨어의 시스템 구조까지 모두 파악하고 있어야 효율적인 학습이 가능하다는 거겠죠?
더 자세한 이야기는 (링크) 에서 확인해보실 수 있습니다.
학습 최적화 관련해서 추가로 재밌게 읽은 논문이 있어서 공유드립니다.
제목(How to train BERT with an academic budget)에서 알 수 있듯이, BERT같은 large scaled model들을 어떻게 최적화하여 저렴하게 학습할 수 있는지에 관한 논문입니다.
본 논문에서는 먼저 학습 환경부터 제한하여 설정했는데요, (1) 24시간 내에 학습될 것, (2) 8개의 NVIDIA Titan-V GPU (각각 12GB) 로 학습을 시도했다고 합니다.
참고로, 8개의 Titan-V GPU로 24시간 학습하는 것은 4개의 RTX 3090 GPU로 하루, 40GB짜리 1개의 A100 GPU로 2.4일 학습한 것과 유사하다고 하네요 🙂
학습 데이터는 영어 wikipedia, Toronto BookCorpus로부터 획득한 16GB의 텍스트 데이터를 이용했다고 합니다.
학습은 BERT-style의 transformer encoder와 MLM objective로 진행하였습니다.
또한, sentence classification task를 목적으로 학습하는 PLM이기 때문에, 128개로 token 길이를 제한하였는데, 이는 BERT의 원 논문에서도 적용된 방법이라고 합니다. (학습의 초기 90%는 127 토큰으로, 나머지 10%는 512 토큰으로 학습)
효과가 미비한 것으로 잘 알려진 것과 마찬가지로, next sentence prediction (NSP) 는 학습에서 제거하고 single sentence만 학습했으며, 학습 시간에 포함되는 validation loss를 계산하는 시간마저 줄이기 위해, 30분마다 0.5%의 validation set만을 계산했다고 합니다.
모델의 사이즈는 BERT-large와 동일하게 세팅했으며, DeepSpeed를 통해 data parallelization, mixed-precision 을 적용했습니다.
MLM prediction head를 sparse token prediction으로 바꾸었으며, APEX LayerNorm을 적용함으로써 학습을 최적화했습니다.
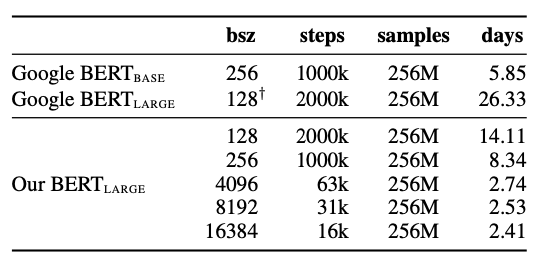
결론적으로, 이렇게 최적화 BERT model의 경우, 동일한 batch size (bsz)로 학습할 때는 기존 BERT 대비 2배 정도 빠른 속도로 학습했고, batch size를 최대한으로 늘리자 2.41일 만에 학습이 가능했다고 합니다 🙂

단 24시간으로 학습을 제한한 경우, 기존 PLM과 유사한 성능을 보였다고 하네요! 🙂
학습 최적화 관련된 기술은 앞으로도 계속 발전중입니다!
나중에는 개인 PC로 GPT-3를 학습할 수 있는 기술도 가능할지 모르겠네요 😀






