
썸네일 출처: GauGAN2 데모 페이지를 통해 신규 생성된 이미지입니다.(input text:은하수별 나무)
[융합연구팀 심홍매]
2019년에 열린 GTC 컨퍼런스에서 Nvidia는 GAN(generative adversarial networks)을 기반으로 대략적인 스케치를 사실적인 이미지로 바꿔주는 실시간 AI 페인팅 애플리케이션인 GauGAN 을 발표하였습니다. 그로부터 2년이 지난 최근 NVIDIA는 GauGAN의 후속 제품인 GauGAN2를 공식 출시했습니다. GauGAN2는 그림마저 필요 없고 간단한 텍스트를 입력하면 이에 부합되는 이미지를 알아서 만들어 줍니다. 이는 분할 맵핑, 복구 및 텍스트-이미지 생성 기술을 하나의 모델에 결합하여 텍스트와 간단한 그림을 입력하면 사실적인 예술을 만들 수 있는 강력한 도구입니다.
공식 블로그에 기재되어 있는 예시와 같이 “ocean waves hitting rocks on the beach”를 입력하면 모델은 점진적 조정을 통해 입력 된 텍스트와 일치하는 이미지를 생성 할 수 있게 됩니다. 다음 링크를 통해 GauGAN2 데모에 대하여 체험을 해볼수 있습니다.

출처: Nvidia 공식 블로그 (링크)
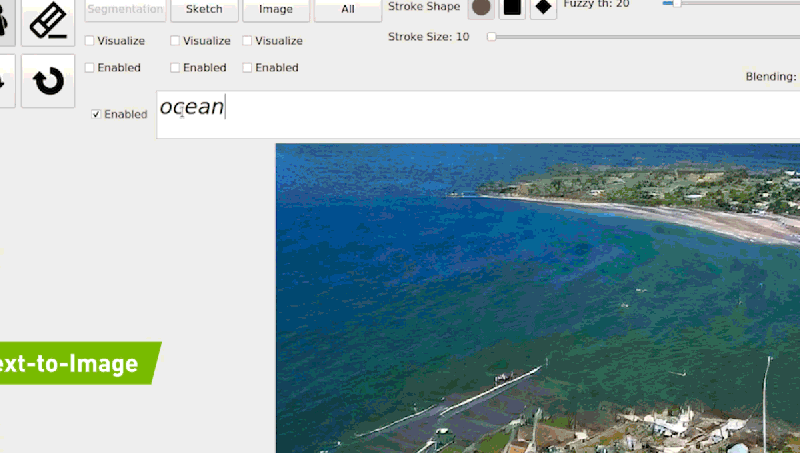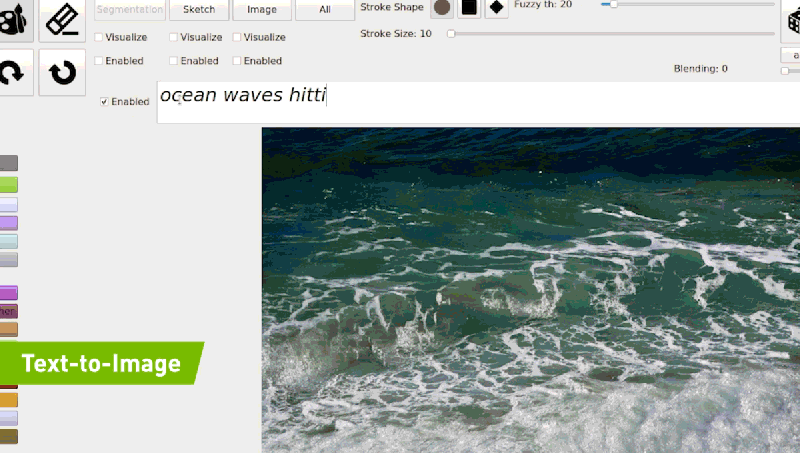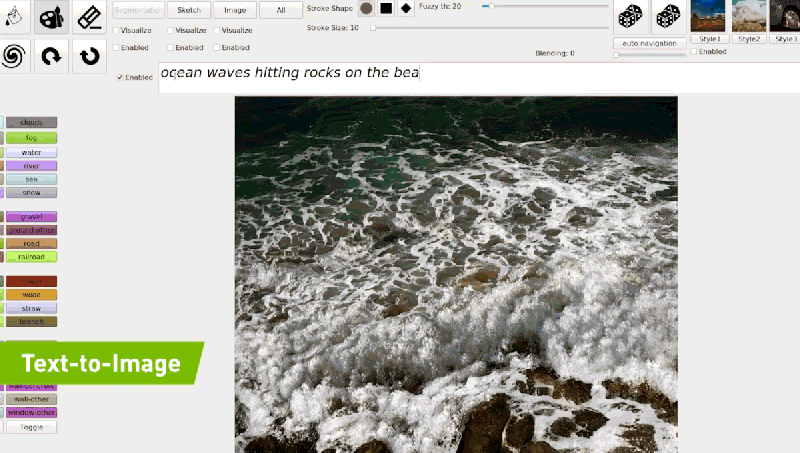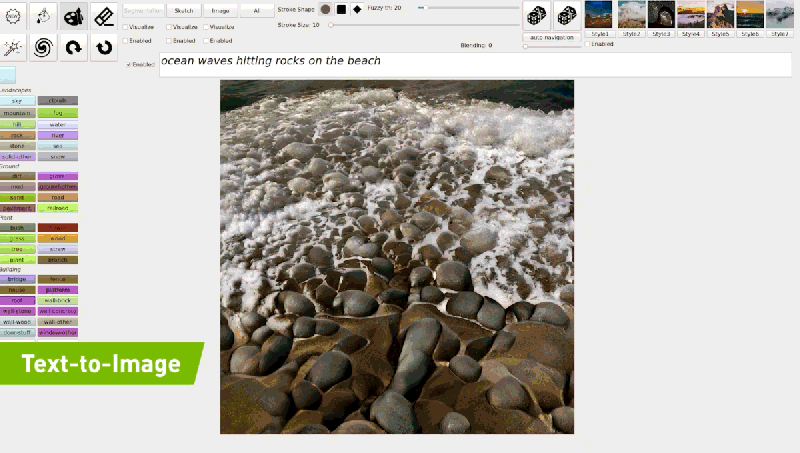
2019년부터 Nvidia는 백만 개 이상의 Flickr 이미지를 통해 학습 된 GauGAN 시스템을 개선하기 시작했습니다. GauGAN과 달리 GauGAN2는 1,000만개의 이미지로 훈련되어 자연어 설명을 풍경 이미지로 변환할 수 있습니다. 아티스트들은 이를 통해 사실적인 이미지 생성 뿐만이 아니라 현실에 존재하지 않는 예술적인 장면까지도 묘사할 수 있습니다.
실용적 관점으로 볼 때 GauGAN2는 영화, 소프트웨어, 비디오 게임, 제품, 패션 및 인테리어 디자인에 잠재적으로 응용할 수 있는 시각적 크리에이티브 생성기라고 할 수 있습니다. Nvidia에서는 GauGAN의 첫번째 버전이 영화와 비디오 게임의 컨셉 아트를 만드는 데 사용되었다고 주장했는데요, 마찬가지로 GauGAN2도 추후 개선 후 오픈 소스 코드를 제공하여 향후 실 서비스에 적용 할 예정이라고 합니다.
올해 초 OpenAI에서는 이미지 버전의 GPT-3라 불리는 120억 개의 매개변수가 포함된 DALL-E를 출시했습니다. 해당 모델은 GauGAN2와 마찬가지로 자연어로 표현된 수많은 개념을 적절한 이미지로 변환하여 놀라움을 자아냈습니다. 이러한 유형의 생성 모델의 한 가지 단점은 편향(bias)될 수 있다는 것입니다. 예를 들어 DALL-E에서 OpenAI는 CLIP 모델을 통해 생성된 이미지의 품질을 개선하였지만 몇달전 연구에서는 CLIP에 인종 및 성별 관련하여 편견 문제가 있음이 밝혀졌습니다 (참고 링크). Nvidia 측 에서는 “현 모델에는 1억개 이상의 매개변수가 있고 데모 단계여서 학습 시간은 1개월 미만입니다. 학습 이미지는 풍경 이미지 데이터를 사용하였기에 GauGAN2는 풍경 생성에만 중점을 둡니다. 연구팀은 또한 이미지에 사람이 포함된 장면이 없는지 확인 하기 위하여 이미지 검토 관련 작업을 하고 있습니다.”라고 하였으며 이렇게 하면 GauGAN2의 편견을 줄이는데 도움이 될수 있고, 비록 아직 데모 단계이지만 추후 풍경뿐만이 아니라 다양한 이미지 생성을 위해 관련 된 편견성을 줄이기 위한 작업도 함께 할 예정이라고 밝혔습니다.
기존의 DALL-E 발표 했을 때와 마찬가지로, 사람들은 찬사를 보내기도, 염려를 표하기도 합니다. GauGAN2는 아직 초기 단계여서 완벽한 수준은 아니지만 간략한 설명으로 원하는 이미지를 바로 만들 수 있어 다양한 창작에 활용 할 수 있다는 점이 놀랍기만 한 것 같습니다. 앞으로도 해결해야 할 문제점들은 많겠지만 관련 된 기술이 점차 진화하고 더 정교해져서 사람들에게 도움을 줄 수 있는 서비스로 되길 기대해봅니다!
Reference
https://blogs.nvidia.com/blog/2021/11/22/gaugan2-ai-art-demo/






