
썸네일 출처: Google Imagen를 통해 생성됨(text: 사하라 사막에서 밀짚모자와 네온 선글라스를 쓴 작은 선인장)
[가상인간연구팀 심홍매]
텍스트, 이미지, 음성 데이터 등 다양한 형태(modality)로 이루어진 데이터 특징을 효과적으로 학습하기 위한 방법을 Multimodal learning이라고 하는데요, 최근 국내외 학계 및 업계에서는 멀티모달 인공지능(AI) 모델 관련 연구들을 활발히 진행하고 있으며 이미 업계들에서는 우수한 성능의 서비스들도 출시하고 있습니다. 오늘 그중 몇개의 대표적인 Multimodal 연구사례에 대하여 간단히 소개해 드리도록 하겠습니다.
[Nvidia GauGAN]
2019년에 Nvidia는 GAN(generative adversarial networks)을 기반으로 대략적인 스케치를 사실적인 이미지로 바꿔주는 실시간 AI 페인팅 애플리케이션인 GauGAN 을 발표하였습니다. 2년 후 NVIDIA는 GauGAN의 후속 제품인 GauGAN2를 공식 출시했습니다. GauGAN2는 그림마저 필요 없고 간단한 텍스트를 입력하면 이에 부합되는 이미지를 알아서 만들어 줍니다.
공식 블로그에 기재되어 있는 예시와 같이 “ocean waves hitting rocks on the beach”를 입력하면 모델은 점진적 조정을 통해 입력 된 텍스트와 일치하는 이미지를 생성 할 수 있게 됩니다
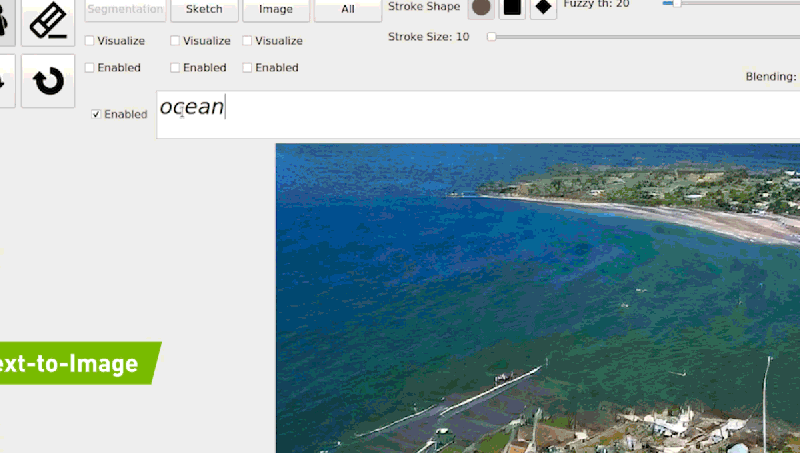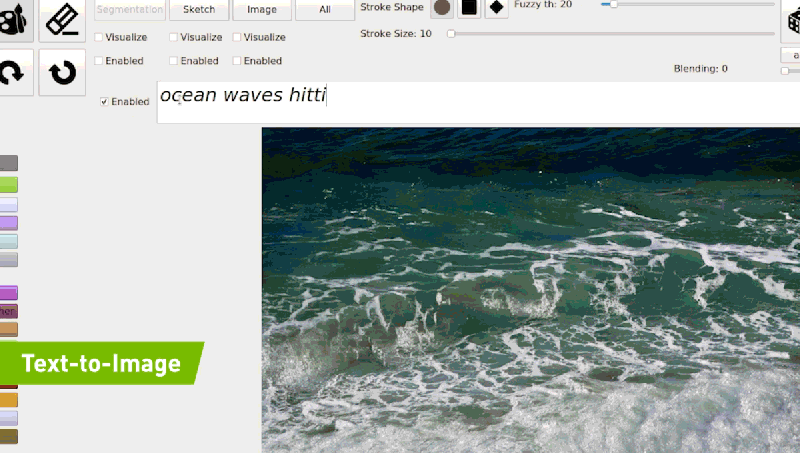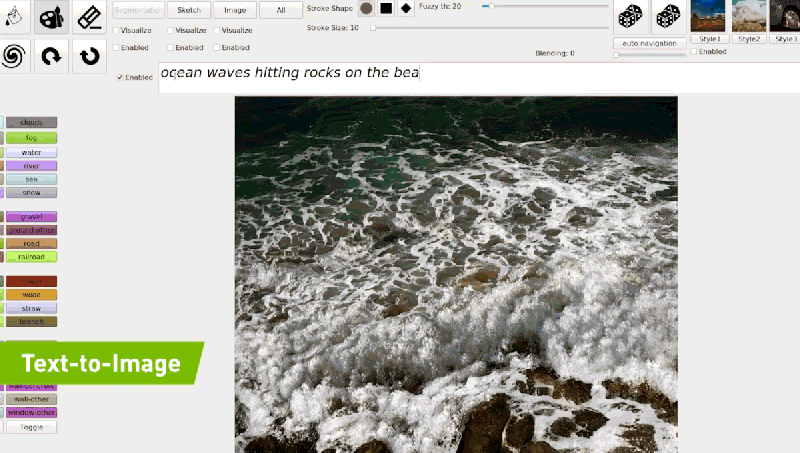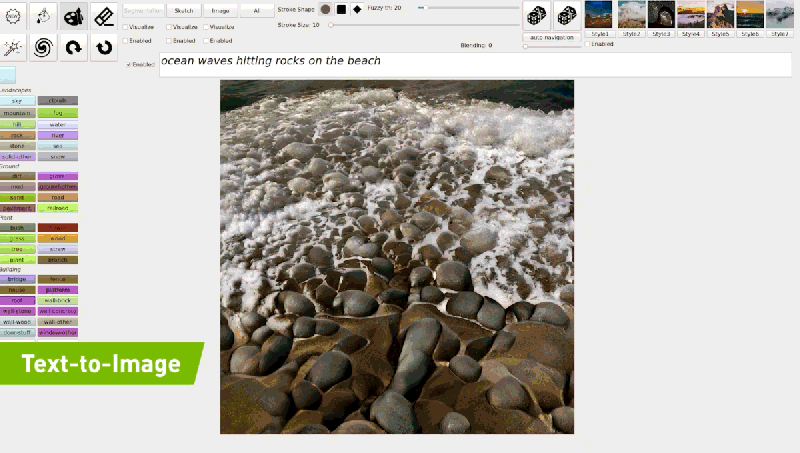
GauGAN2는 다양한 텍스트 프롬프트와 스케치를 통해 사용자에게 보다 세밀한 컨트롤과 빠른 장면 커스터마이징을 제공해주고 있습니다.
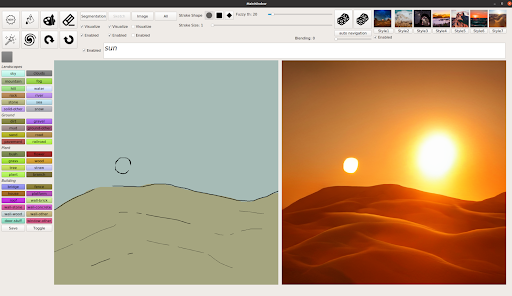
사용자는 상상한 장면의 모든 요소를 직접 그리지 않아도 됩니다. “호수 위의 은하수”와 같은 짧은 문구를 입력해 이미지의 주요 특징과 테마를 빠르게 생성할 수 있습니다. 스케치를 통해 호수를 더 크게 만들거나 전경에 몇 그루의 나무를 추가하고 하늘에 별을 더 생성하는 등 사용자 정의 또한 가능합니다. ‘고갱2’는 현실기반의 이미지뿐 아니라 다른 세상의 풍경도 묘사할 수 있다. 예를 들어 영화 ‘스타워즈’ 시리즈에서 두 개의 태양이 있는 상징적인 행성 타투인(Tatooine)의 풍경을 재현하려면 ‘사막’, ‘모래언덕’, ‘태양’이라는 텍스트만으로 시작점을 만들고, 이를 바탕으로 사용자가 두 번째 태양을 스케치해 넣으면 됩니다.
GauGAN2는 1,000만개의 풍경 이미지 데이터를 사용하였기에 풍경 생성에만 중점을 둡니다. nvidia 연구팀은 또한 이미지에 사람이 포함된 장면이 없는지 확인 하기 위하여 이미지 검토 관련 작업을 하고 있습니다.”라고 밝혔으며 이렇게 하면 GauGAN2의 편견을 줄이는데 도움이 될수 있고, 비록 아직 데모 단계이지만 추후 풍경뿐만이 아니라 다양한 이미지 생성을 위해 관련 된 편견성을 줄이기 위한 작업도 함께 할 예정이라고 입장을 밝혔었습니다.
[OpenAI DALL·E]
2021년 Open AI에서는 원하는 것을 텍스트로 설명하면 이미지로 생성해주는 DALL.E는 를 소개했었습니다. 이 서비스는 고해상도의 이미지를 짧은 시간 내에 생성하고 포토샵이나, 디지털 아트 기술 없이도 간단한 도구와 텍스트 수정으로 이미지를 쉽게 편집할 수 있다는 장점이 있습니다. 1년 후 Open AI에서는 DALL.E 의 후속 버전인 DALL.E 2를 발표하게 되었는데요, 당시 생성된 이미지들의 놀라운 성능들로 인해 몇주간 트위터에서 큰 파장을 일으켰었습니다. 기존 DALL.E는 종종 일반 배경에 대해 만화같은 방식으로만 이미지를 렌더링할 수 있었으나 새로운 DALL-E 2는 복잡한 배경, 피사계 심도(depth of field) 효과, 사실적인 그림자, 음영 및 반사가 포함된 사진 같은 고해상도 이미지를 생성할 수 있게 되었습니다. 기존 DALL-E가 256×256 이미지를 생성한 것에 비해 DALL-E 2는 이를 4배 업스케일링하여 1024×1024까지의 해상도를 지원한다고 합니다.

더불어 DALL-E 2는 자연어로부터 이미지를 생성할 뿐만 아니라, 기존 이미지에 대해 원하는 방향으로의 수정을 할 수 있습니다. 원래 상업용 이미지를 만들 때도 시안을 뽑은 후 디자이너와의 협의를 통해 이를 점차 수정하는 과정을 거치는데, DALL-E 2에도 자연어로 이런 요청을 할 수 있다는 것입니다.
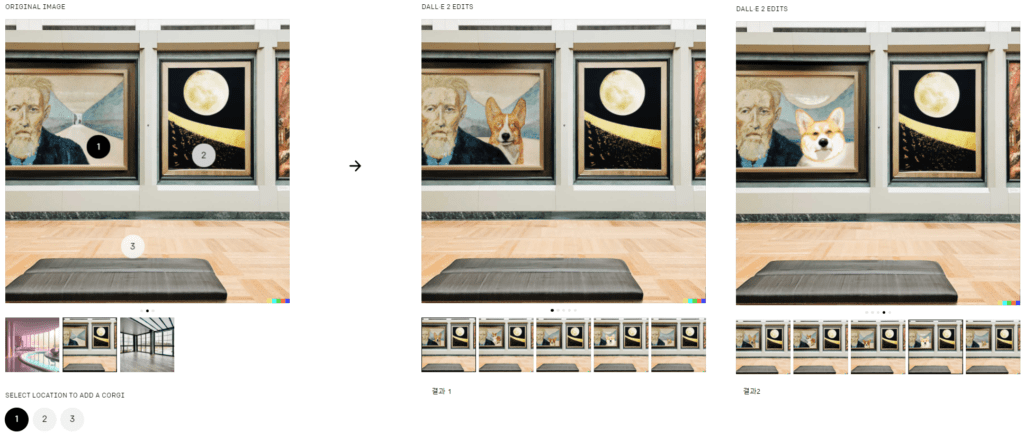
오픈AI는 GPT-3 때와 마찬가지로 신뢰할 수 있는 소규모 이용자에게 DALL-E 2를 선 공개한 이후에 개선 작업을 거쳐 일반 대중에게 공개할 계획이라고 합니다. GPT-3는 공격적이거나 유해한 텍스트를 생성하는 문제가 있었습니다. 하여 오픈AI는 GPT-3 이용자들로부터 피드백을 받아서 더 안전한 버전인 ‘인스트럭트GPT(InstructGPT)’를 만들었습니다. DALL-E 2에서도 이용자 피드백을 활용해서 제품을 개선하고자 한다고 밝혔습니다. 오픈AI는 우선 초기 이용자들에게 다양한 방식을 이용해 DALL-E 2가 공격적이거나 유해한 이미지를 생성하게 만들어 보라고 권장하는 방식들을 통해 발견된 문제들을 모두 해결하고 나면 DALL-E 2를 더 많은 사람들에게 공개할 예정이라고 합니다.
[Google Imagen]
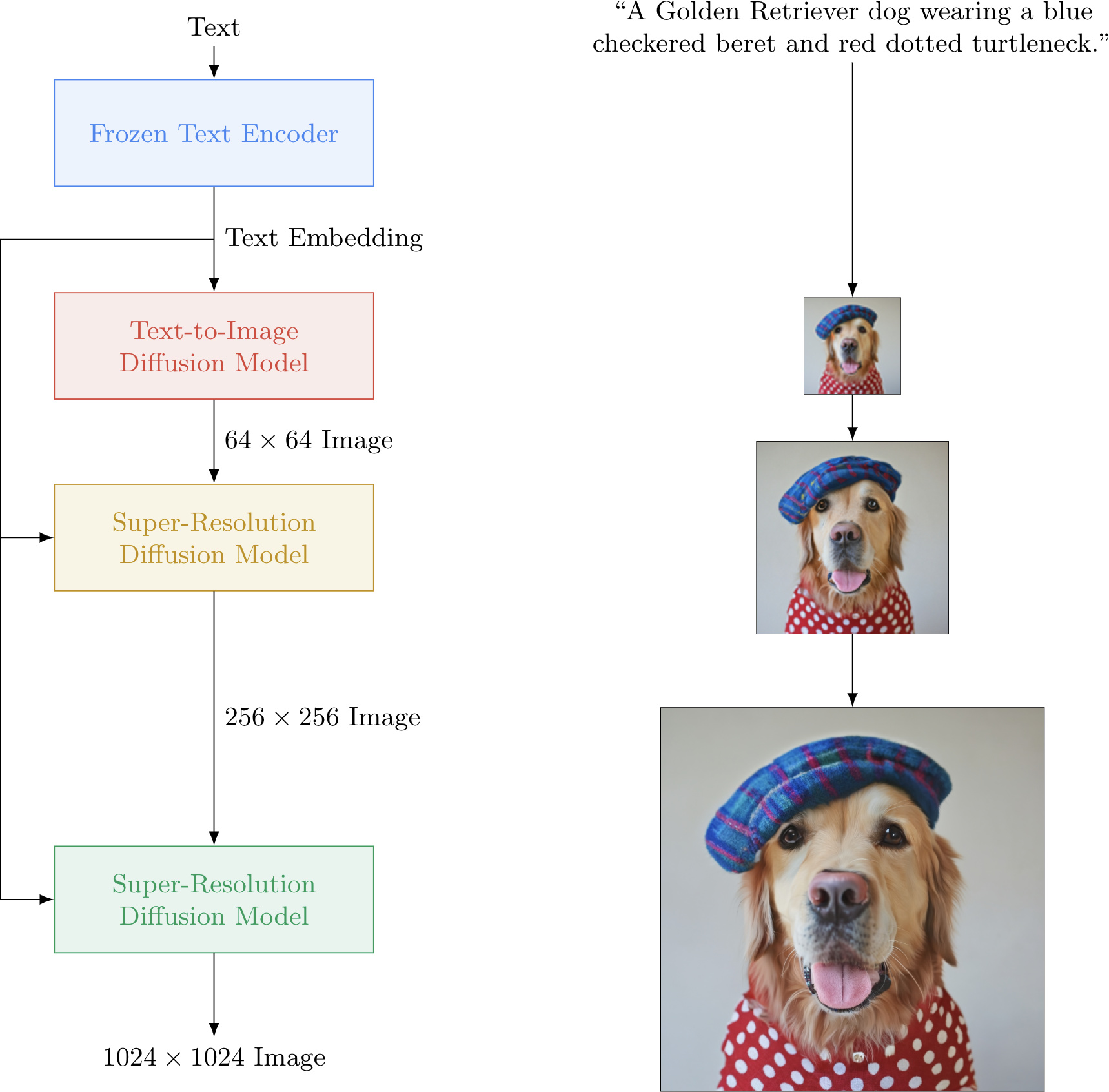
최근 구글에서도 텍스트 입력을 기반으로 사실적인 이미지를 생성할 수 있는 텍스트-이미지 확산 모델(Diffusion Model)인 Imagen을 공개하였습니다. 구글 연구팀은 기존의 유사 AI들도 환상적이고 흥미로운 다양한 이미지를 생성 할 수 있지만, Imagen이 생성한 이미지는 정확성과 이미지의 충실도(fidelity)에서 더 뛰어나다고 주장하고 있습니다. Imagen 공식 사이트에는 입력된 텍스트와 그에 따라 생성된 이미지의 사례들이 소개되어 있습니다. 이러한 이미지들은 마치 사람이 직접 포토샵을 한 것처럼 착각할 정도의 깔끔하고 높은 해상도의 퀄리티를 갖고 있습니다.

Imagen은 텍스트를 이해하는 대형 변환기(transformer) 언어모델의 성능을 기반으로 정확도 높은(high-fidelity ) 이미지를 생성하는 확산 모델을 결합하였습니다. 구글 연구팀은 Imagen을 통해 텍스트 전용 말뭉치로 사전 훈련된 거대 언어모델의 텍스트 임베딩이 텍스트-이미지 합성(text encoding)에 상당이 효과적이라는 것을 발견했다고 합니다.
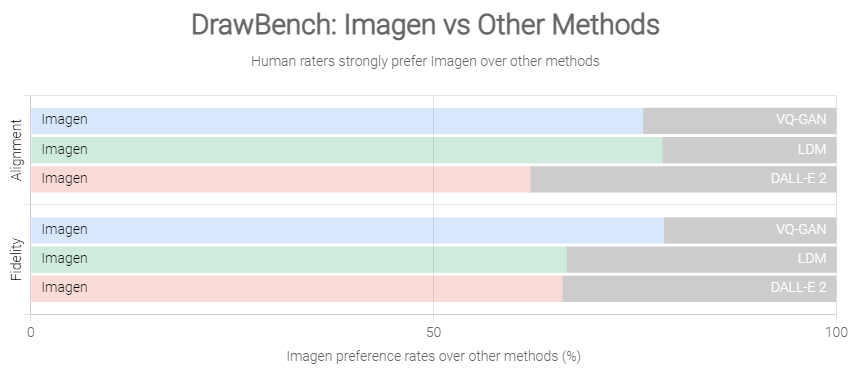
공개된 논문에 의하면 Imagen의 성능 평가를 위해 텍스트-이미지 모델에 대한 벤치마크인 DrawBench를 사용해 Imagen을 VQ-GAN+CLIP, Latent Diffusion Models 및 DALL-E 2를 포함한 최신 방법들과 비교한 결과, [그림 7]과 같이 평가자들이 다른 모델보다 Imagen을 선호한다는 것을 발견했다고 합니다.
아래 [그림 8]은 평가에 사용된 텍스트 및 각 모델에 대한 이미지 생성 결과입니다. 그중 “A horse riding an astronaut.” prompt 에 대응되는 결과를 보면 “우주 비행사를 타고 있는 말”인데 모두 “말을 타고 있는 우주 비행사”에 대응되는 이미지를 생성한 것을 볼 수 있습니다. “A panda making latte art.”에 대해서는 Imagen은 부합되는 이미지를 생성했으나 DALL.E 2는 “펜더라떼 아트”에 대응되는 이미지를 생성한 걸 볼 수 있습니다. 또한 컬러 카테고리 관련 된 실험에서 “A black apple and a green backpack.” prompt에 대해 Imagen은 검정 사과, 초록색 백에 부합되는 이미지를 생성했으나, DALL.E 2는 초록색 사과, 검정 백이란 prompt 에 부합되지 않는 이미지를 생성한 걸 확인 할 수 있습니다. 이처럼 여러 예시들을 봤을 때 Imagen이 더 사실적인 이미지를 생성하지만 color , aligned 관련해서 모델들은 여전히 어려움을 겪고 있음을 확인 할 수 있습니다.

DALL-E와 마찬가지로 Imagen도 아직은 대중에게 공개되지 않을 거라고 합니다. 구글은 여러 가지 이유로 일반 대중이 사용하기에 아직 적합하지 않다고 말했습니다. 한 가지 예로, 텍스트-이미지 모델은 일반적으로 웹에서 수집하고 선별되지 않은 대규모 데이터 세트에 대해 학습되므로 많은 문제가 발생할 수 있습니다.
이외에도 국 내 외에는 다양한 멀티모달 서비스나 연구사례들이 많은데요, 최근 중국 칭화대에서는 텍스트를 입력하면 4초 분량의 32 frame 동영상을 생성할 수 있는CogVideo(Large-scale Pretraining for Text-to-Video Generation via Transformers)란 모델을 공개했습니다. 아직 논문은 공개되어 있지 않고 결과 물만 정리해둔 상태입니다. 해당 기술도 아직은 성숙되지 않았지만, 기타 기술의 발전속도를 참고한다면 해당 모델들의 성능도 급성장 할 것 같습니다. 그때 해당 기술을 잘 활용한다면 단순히 말로 직접 애니메이션이나, 영화, 뮤직비디오 등도 만들 수 있지 않을까 조심스럽게 생각을 해봅니다.
[Conclusion]
텍스트-이미지 , 텍스트-비디오 등과 같은 멀티모달은 확실히 환상적인 창의적 잠재력을 가지고 있지만 문제가 많은 것은 사실입니다. 예를 들어 가짜 뉴스, 스팸 메일 또는 괴롭힘에 사용되는, 원하는 거의 모든 이미지를 생성하는 시스템을 상상해 봅시다. 학계와 업계에서 모두 우려했듯이 이러한 시스템은 사회적 편견도 인코딩하며 그 결과는 종종 인종 차별적이거나 성 차별적이거나 다른 방식으로 안 좋은 결과를 초래하게 될 수도 있습니다. 지금도 짧은 시간 내에 고해상도 고 퀄리티의 이미지를 생성할 수 있는데 앞으로 상업적으로 사용할 수 있는 품질의 이미지를 생성 할 수 있다면, 지금보다 더 쉽게 딥페이크 이미지를 만들어 낼수 있고, 해당 이미지를 이용하여 동영상까지 제작을 한다면 더 많은 사람들에게 범죄를 저지르는데 악용되는 건 불가피 하게 될 것입니다.
기술 자체를 발전시키는 한편 , 위와 같이 사회적으로 해결해야 할 문제들도 함께 공존하게 되는데요, 좋은 기술들이 악용되지 않도록 함께 고민하고 대책을 마련하면서 기술을 발전시킨다면 앞으로도 더 상상치 못하는 무궁무진한 사람들에게 도움을 줄 수 있는 연구와 서비스들이 나오지 않을까 기대해봅니다!
Reference
[1] https://gweb-research-imagen.appspot.com/
[2] https://arxiv.org/pdf/2205.11487.pdf
[3] https://blogs.nvidia.co.kr/2021/11/24/gaugan2-ai-art-demo/
[4] https://openai.com/dall-e-2/#demos
[5] https://smilegate.ai/2021/11/24/let-an-ai-paint-for-you-gaugan2/
[6] https://github.com/THUDM/CogVideo
[7] http://www.aitimes.com/news/articleView.html?idxno=144897
[8] http://www.aitimes.com/news/articleView.html?idxno=143854
[9] https://www.cctvnews.co.kr/news/articleView.html?idxno=232608






