
[분석지능개발팀 박효주]
딥러닝 기술의 발전으로 AI 모델의 성능은 점점 향상되고 있고 있습니다. 하지만 그만큼 모델의 크기는 점점 거대해지고 추론 속도는 느려지고 있습니다. 더 좋은 GPU를 사용하면 효과를 볼 수 있지만 그 비용이 매우 크기 때문에, AI 서비스를 효율적으로 운영하기 위해서 모델의 경량화는 선택이 아닌 필수가 되었습니다.
모델을 경량화하기 위해서는 PyTorch 혹은 TensorFlow 등으로 학습해서 나온 모델을 ONNX 또는 TensorRT 포맷으로 변환해야 합니다. 하지만 이렇게 변환된 모델을 사용하려면 별도의 추론 코드를 작성해야 하고, 여기서 성능을 더 올리기 위해서는 추론 코드를 C++로 작성해야 하는데 이 과정이 쉽지 않습니다. 이런 어려운 부분을 Triton Inference Server를 이용하면 쉽게 해결할 수 있습니다.
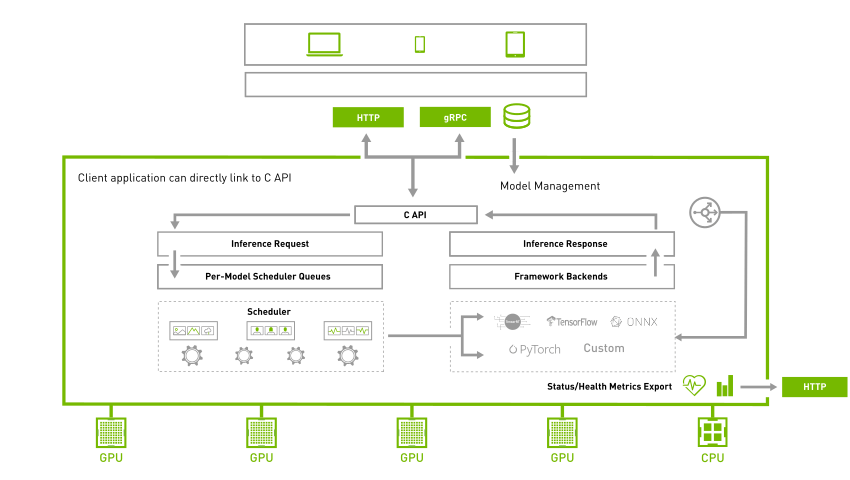
Triton Inference Server
Triton Inference Server는 고성능 추론에 최적화된 오픈소스 소프트웨어입니다. 다양한 모델 포맷, 특히 TensorRT의 추론 기능을 제공하기 때문에 별도의 추론 코드를 작성할 필요가 없으며, C++ 기반으로 만들었기 때문에 Python보다 빠른 속도로 추론이 가능합니다. 실제로 사용할 때는 아래 config.pbtxt처럼 모델의 배포 스펙만 정의하면 Triton Inference Server로 바로 배포가 가능합니다.
name: "cifar10_vgg16_pt"
platform: "pytorch_libtorch"
max_batch_size: 8
dynamic_batching {
max_queue_delay_microseconds: 100
}
instance_group [
{
count: 1
kind: KIND_GPU
}
]
input [
{
name: "input__0"
data_type: TYPE_FP32
dims: [ 3, 32, 32 ]
}
]
output [
{
name: "output__0"
data_type: TYPE_FP32
dims: [ 10 ]
}
]
< config.pbtxt 예시 >
Triton Inference Server를 사용했을 때의 주요 장점을 정리하면 아래와 같으며, 이외에도 다양한 기능들을 제공합니다.
- 다양한 모델 프레임워크 지원 및 추론 기능 제공
- C++ level의 고성능 추론
- Kubernetes를 이용한 확장 및 모니터링 지원
- 모델 앙상블
- Single GPU, Multiple Model
- 모델 버전 관리
성능 비교
실제로 Triton Inference Server를 사용했을 때 어느 정도 효과가 있는지 확인해보겠습니다. 확인을 위해 CIFAR-10 이미지를 이용해서 PyTorch로 VGG16 모델을 학습했고, ONNX와 TensorRT로 각각 변환한 뒤 모델의 메모리 사용량과 처리량을 비교했습니다. TensorRT의 경우 FP32에서 FP16으로 양자화(Quantization)해서 비교했습니다.
메모리 사용량
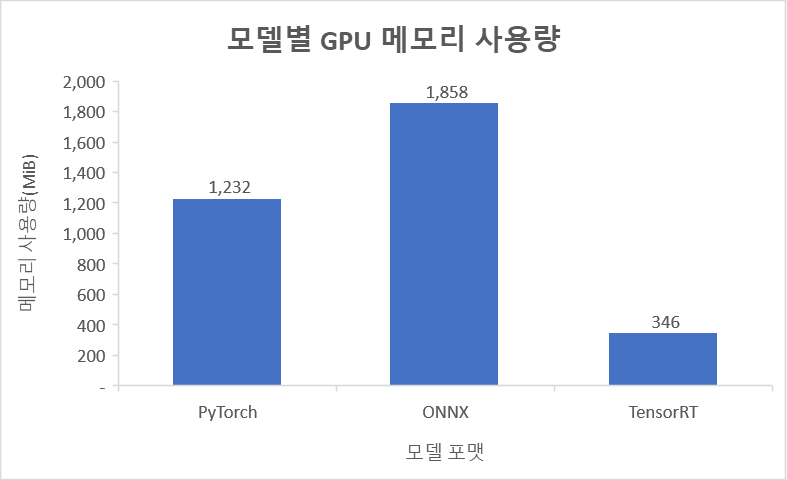
차트는 각 모델 포맷별로 배포 시 GPU 메모리 사용량을 측정한 결과입니다. 결과를 보면 기존PyTorch 모델과 비교했을 때 ONNX의 경우 메모리를 더 많이 사용하고 있지만, TensorRT의 경우 절반도 안 되는 메모리만 사용되는 것을 볼 수 있습니다.
처리량
처리량 측정은 NVIDIA에서 제공되는 Performance Analyzer를 이용했습니다. Concurrency를 1에서 10까지 높여가면서 각 모델 포맷의 처리량을 비교했으며, 각각의 모델을 배포할 때 PyTorch와 ONNX는 max-batch를 8로, TensorRT는 1로 설정하고 진행했습니다.
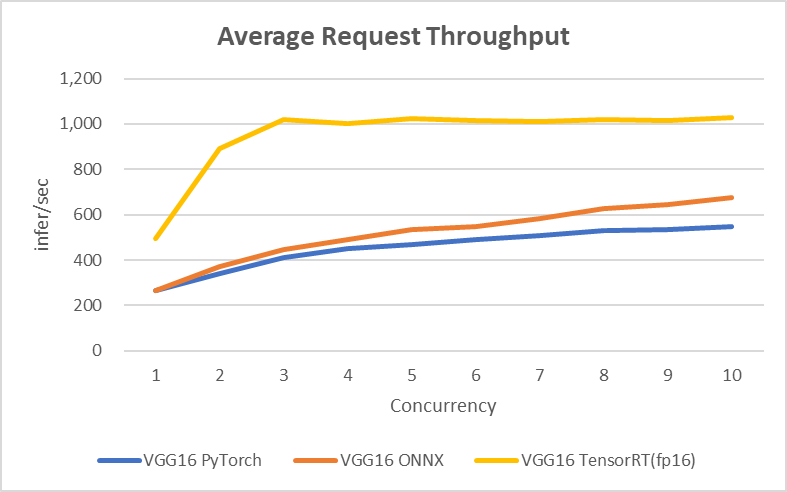
결과를 보면 ONNX의 경우 Concurrency가 높아질수록 PyTorch보다 처리량이 약간 높아지지만, TensorRT의 경우 처리량이 약 2배 이상 높은 것을 확인할 수 있습니다. TensorRT가 batch 처리되지 않기 때문에 Concurrency 3부터 처리량이 올라가지 않지만, 그걸 감안하더라도 TensorRT의 처리량이 압도적으로 높은 것을 볼 수 있습니다.
마침
GPU 자원의 사용료가 비싼 만큼 모델의 자원 사용량과 처리량에 대한 최적화는 AI 서비스 성공 여부에 큰 부분을 차지하고 있습니다. 최근 가장 크게 화제가 되고 있는 생성모델의 경우도 자원 사용량과 처리량 측면에서 매우 효율이 낮기 때문에, 이러한 최적화를 잘 적용해서 효율적으로 배포할 필요가 있습니다.
Reference
- https://www.economist.com/interactive/briefing/2022/06/11/huge-foundation-models-are-turbo-charging-ai-progress
- https://developer.nvidia.com/nvidia-triton-inference-server
- https://github.com/triton-inference-server/client/blob/main/src/c++/perf_analyzer/README.md






