
[분석AI서비스팀 박효주]
최근 언어 모델의 발전은 큰 임팩트를 주었고, 그만큼 연구 또한 활발히 이루어지고 있습니다.
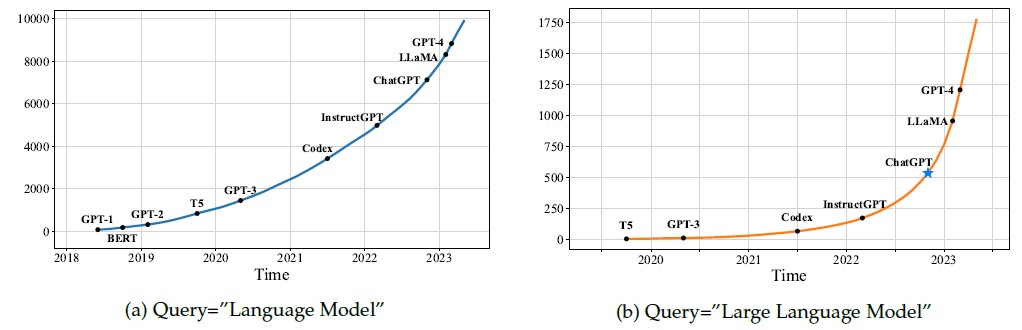
그러나 이러한 모델의 서빙 과정에서 발생하는 고도의 계산 작업과 메모리 요구량은 새로운 도전 과제를 제시하고 있습니다. 최적화된 서빙은 이러한 LLM을 효율적으로 운영하기 위한 중요한 역할을 수행합니다. 본문에서는 이러한 중요한 역할을 하는 LLM 최적화 라이브러리 3개를 소개합니다.
라이브러리 소개
FasterTransformer (GitHub)
가장 유명한 모델 최적화 라이브러리로 LLM이 나오기 전부터 사용되다 LLM이 등장하면서 더 많이 사용되고 있습니다. 큰 특징은 C++, CUDA Native로 동작하고 Model Parallel(Tensor Parallel/Pipeline Parallel) 기반의 추론 가속 엔진을 구현했다는 것입니다.
다만 2023년 초까지 버전을 Release하다 현재는 개발이 중단되었고, 이후 개발 건이 TensorRT-LLM으로 이관되었습니다.
FasterTransformer에서 지원되는 모델의 종류는 여기서 확인할 수 있습니다.
vLLM (GitHub)
2023년 6월에 등장해서 현재 인기있는 모델 최적화 라이브러리 중 하나 입니다. 처음 등장했을 때 지원되는 모델이 많지 않았던 FasterTransformer에 비해 다수의 최신 모델을 지원하면서 최신 언어 모델들을 효율적으로 다룰 수 있게 되었습니다. 큰 특징은 Paged Attention 기법을 활용해서 latency를 유지하면서 throughput은 2-4X 향상했다는 것입니다.
vLLM에서 지원되는 모델의 종류는 여기서 확인할 수 있습니다.
TensorRT-LLM (GitHub)
가장 최근에 공개(2023년 10월)한 라이브러리로, FasterTransformer의 후속 버전입니다. 앞에서 설명드린 것처럼 FasterTransformer의 개발이 중단되고 이후 기능이 모두 TensorRT-LLM에 이관 개발되었습니다. 큰 특징은 TensorRT 딥러닝 컴퍼일러와 최적화된 커널, 전/후처리 단계, Multi-GPU/Multi-Node 통신 기본요소에 In-flight Batching이라 불리는 최적화된 스케줄링 기술이 포함됐다는 것 입니다.
TensorRT-LLM에서 지원되는 모델의 종류는 여기서 확인할 수 있습니다.
라이브러리 비교
활성화 추이 비교
아래 그래프는 각 라이브러리 별 GitHub stars 누적 추이입니다.
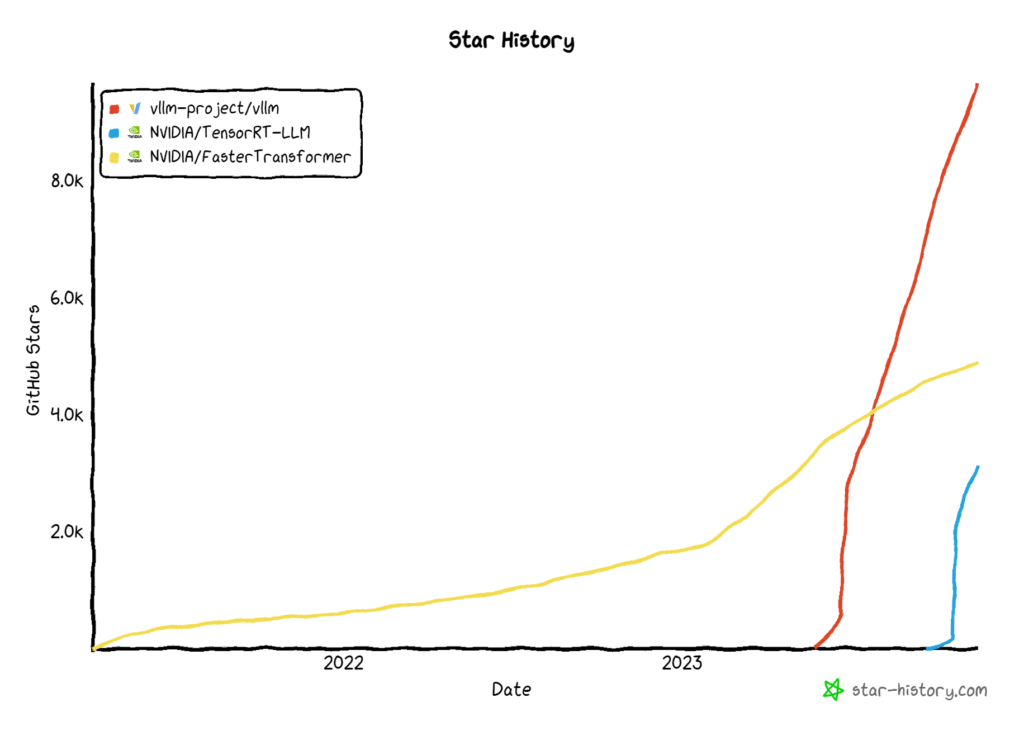
그래프를 보면 FasterTransformer가 출시된지 오래된 만큼 꾸준한 상승세를 보이고 있고, vLLM과 TensorRT-LLM이 등장과 동시에 급등하는 것을 확인할 수 있습니다. 이를 봐도 vLLM과 TensorRT-LLM이 얼마나 필요한 라이브러리인지 확인할 수 있습니다.
지원 모델 비교
각 라이브러리에서 지원하는 모델을 비교해보면 아래 표와 같습니다.
| FasterTransformer | vLLM | TensorRT-LLM | |
|---|---|---|---|
| BLOOM | O | O | O |
| GPT-J | O | O | O |
| GPT-NeoX | O | O | O |
| OPT | O | O | O |
| GPT | O | O | |
| BERT | O | O | |
| T5 | O | ||
| ViT | O | ||
| BART | O | ||
| DeBERTa | O | ||
| Aquila | O | ||
| Baichuan | O | O | |
| Falcon | O | O | |
| GPT-2 | O | ||
| StarCoder | O | O | |
| SantaCoder | O | O | |
| WizardCoder | O | ||
| Dolly v2 | O | ||
| StableLM | O | ||
| InternLM | O | ||
| LLaMA | O | O | |
| LLaMA-2 | O | O | |
| Vicuna | O | ||
| Alpaca | O | ||
| Koala | O | ||
| Guanaco | O | ||
| Mistral | O | ||
| MPT | O | O | |
| Qwen | O | ||
| Blip2 | O | ||
| ChatGLM-6B | 예정 | O | |
| ChatGLM2-6B | 예정 | O |
FasterTransformer는 올 초에 개발을 중단했기 때문에 최신 모델은 지원되지 않습니다. vLLM은 대부분의 모델을 지원하며 GLM 모델도 곧 지원될 예정(v0.2.2)입니다. TensorRT-LLM은 지원이 많이 안되는 것처럼 보이지만 대부분의 기반 모델을 지원하기 때문에 대부분의 모델이 지원된다고 볼 수 있습니다. 다만 이 때문에 모델에 대해 조금은 이해하고 사용해야 할 필요가 있습니다.
처리량 성능 비교
개발이 중단된 FasterTransformer를 제외하고 TensorRT-LLM과 vLLM의 성능을 비교한 결과는 아래와 같습니다.
Throughput은 vLLM이 약 130 tokens/sec, TensorRT-LLM이 약 120 tokens/sec으로 vLLM이 조금 더 처리량이 높은 것을 확인할 수 있습니다. 하지만 큰 차이가 있는 것은 아니기 때문에 상황에 따라 라이브러리를 선택해서 사용해도 괜찮을 것 같습니다.
마침
LLM 연구가 활발히 이루어지고 있는 만큼 모델의 최적화 또한 필요하다는 것을 라이브러리 별 GitHub stars 누적 추이만 봐도 알 수 있습니다. vLLM 혹은 TensorRT-LLM을 사용했을 때의 효과는 확실하지만, 두 라이브러리 모두 아직 초기 버전이기 때문에 사용할 때 새로 Release되는 버전의 기능을 살펴보면서 판단할 필요가 있습니다.
Reference
[1] Zhao, Wayne Xin, et al. “A survey of large language models.” arXiv preprint arXiv:2303.18223 (2023).
[2] https://twitter.com/HamelHusain/status/1719872352694174093
[3] https://developer.nvidia.com/blog/optimizing-inference-on-llms-with-tensorrt-llm-now-publicly-available/






