
https://arxiv.org/pdf/1701.06538.pdf
[선행AI기술팀 전동준]
스타트업 회사인 Mistral AI 에서 지난 8일에 Mixtral 8x7B 모델을 오픈소스로 출시하였습니다. 지난 9월에 출시한 Mistral 7B 모델 기반으로 현존 언어 생성 분야에서 최고 성능인 GPT-4에서 채택중인 “MoE” 방식을 사용하여 파라미터 수가 더 많은 Llama 2 70B, GPT3.5 모델보다 자연어 벤치마크 성능이 뛰어나고, 추론 속도도 빠르다고 설명하고 있습니다. 그리고 Apache 2.0 라이선스로 “open weights”를 표방하면서 오픈소스 생태계에 큰 도움이 되고 있습니다!
Mixtral
이번에 발표한 Mixtral은 다음의 특징들이 있다고 합니다.
- 32k, 3만 2천개의 토큰을 컨텍스트로 처리할 수 있고
- 영어, 불어, 이탈리안, 독일어, 스페인어등의 다국어가 가능하고
- 코드 생성에 뛰어난 성능
- instruction 튜닝을 통해 언어 모델의 성능을 측정하는 MT-Bench에서 8.3점 달성
https://huggingface.co/spaces/lmsys/chatbot-arena-leaderboard
Mixtral은 sparse mixture-of-expoerts 네트워크를 가지고 있습니다. 8개의 그룹화된 파라미터에 feedforward되는 decoder-only 모델인데 이 부분은 다음 단락에서 자세히 살펴보겠습니다. Mixtral은 470억개 정도의 파라미터를 가지는 모델인데 이 방법을 통해서 130억개 파라미터만 사용하는 것처럼 작동합니다. 그래서 추론 속도도 빠르고 효율적으로 사용할 수 있습니다.
MoE(Mixture of Experts)
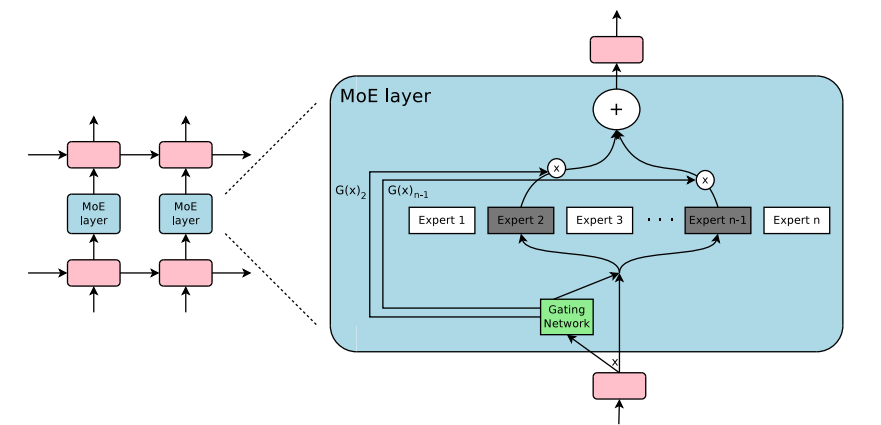
AI 모델의 크기를 키울수록(파라미터가 많을수록) 성능이 좋아집니다. MoE는 한정된 리소스에서 모델의 사이즈를 키우는 방법으로 제안되었습니다. transformer 구조에서 MoE는 아래 그림의 파란색 부분의 레이어로 구성되어 있습니다. 각각의 FFN(feed-forward network)이 “experts”(전문가)입니다. Router를 통해 입력이 어떤 expert로 보내질지 결정됩니다. 환자가 오면 증상을 파악하고 그 증상을 봐줄 수 있는 전문의에게 보내주는 느낌입니다.
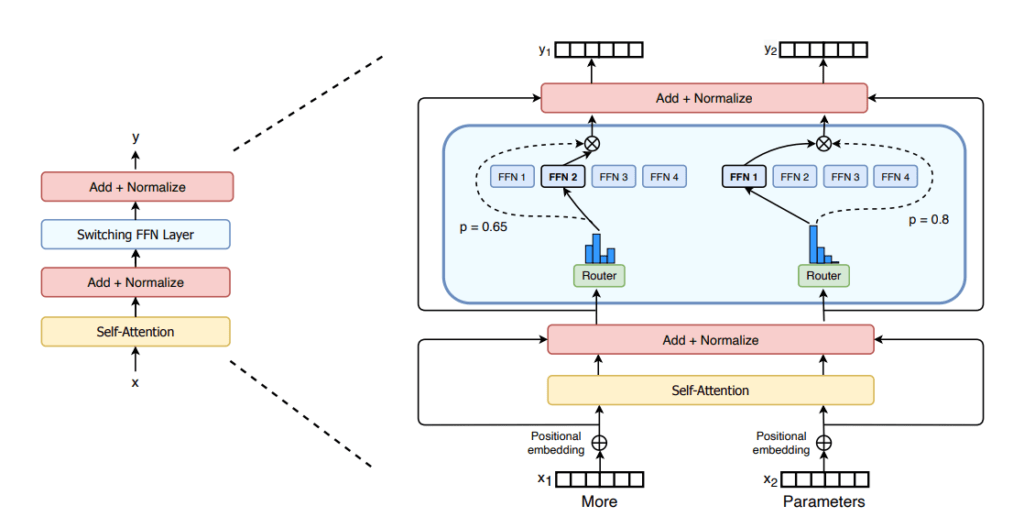
MoE는 학습을 효율적으로 하고 추론을 비슷한 파라미터수의 모델보다 빠르게 할 수 있지만, fine-tuning 단계에서 일반화하는데 한계가 있다고 합니다. 많은 experts, FFN 파라미터를 가지고 있지만 추론에서는 특정 FFN만 계산함으로써 추론 속도가 빠르지만, 모델의 모든 파라미터를 RAM에 올려서 사용해야 합니다. 그래서 메모리 요구량이 높습니다. 이번에 발표한 Mixtral 8x7B 모델 같은 경우도 470억개의 파라미터 수를 가진 모델로, 이를 수용하려면 많은 VRAM이 필요합니다. 이름에서 나와있는 것으로는 7Bx8개인데 56B이 아닌 47B인 이유는 FFN layer가 여러개로 구성되어 있고 나머지는 공유하는 파라미터이기 때문입니다.
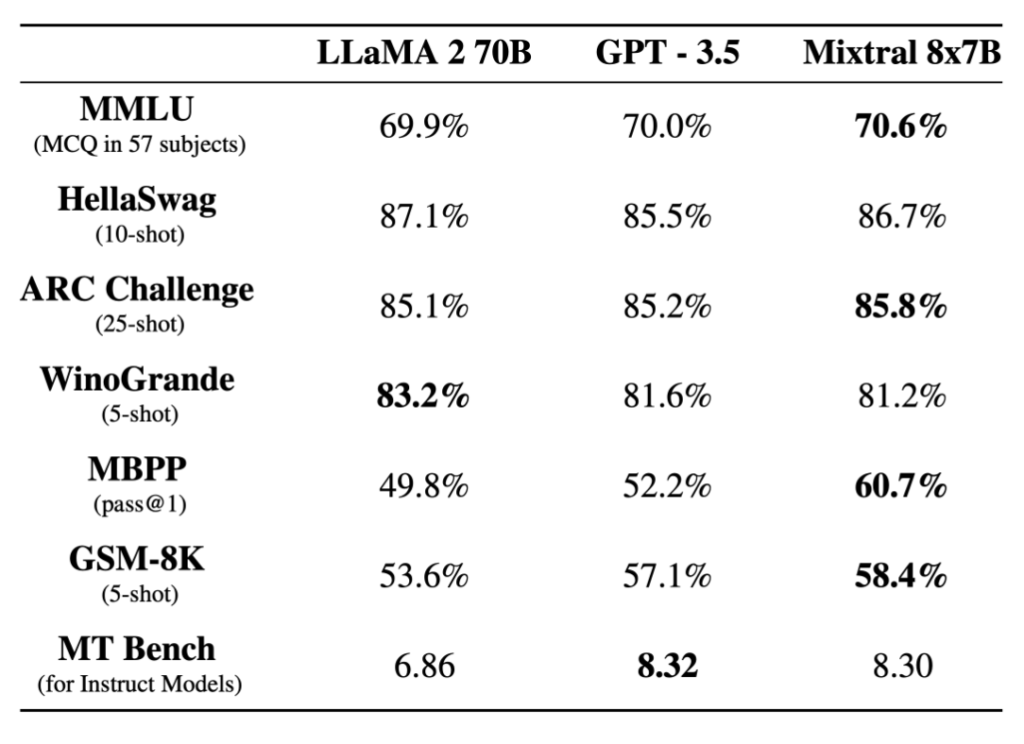
Performance
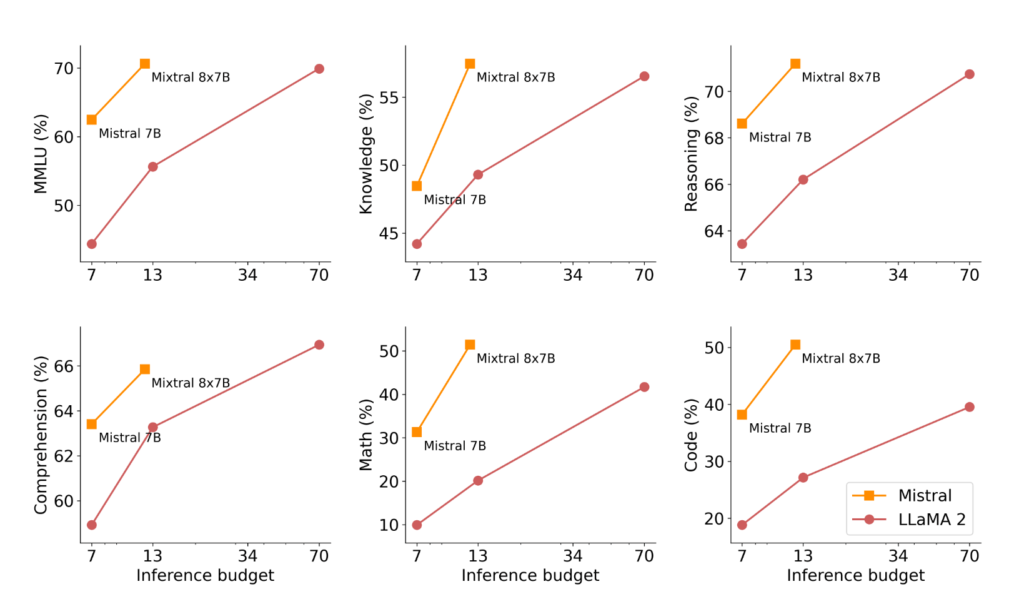
Mixtral과 Llama2, GPT3.5 모델과의 자연어 벤치마크에서의 성능 비교입니다. 모델 크기가 더 큰 Llama2 70B 모델뿐 아니라 GPT3.5와 비교해도 거의 대부분에서 성능 우위를 보이고 있습니다.
추론시에 더 적은 Inference cost를 사용하면서 성능은 Llama2 70B 모델보다 더 우위에 있는 것도 볼 수 있습니다.
Mixtral을 대화형 Instruction에 맞는 답변에 최적화한 instruct 버전도 발표하였습니다. instruction을 지도학습(supervised fine-tuning)하고 생성 답변에 대한 긍정적 답변의 확률을 높아지도록 학습하는(DPO, direct preference optimisation) 방법이 적용되었습니다. 이는 현재 오픈소스 모델중에 가장 높은 성능을 이끌어내는 모델입니다. 안정성을 강화하기 위해 아래와 같은 안정성 프롬프트에 대한 튜닝도 진행하였다고 합니다. Mistral의 safe_mode 파라미터를 통하여 쉽게 프롬프트를 붙일 수 있고, 생성모델에 대한 할루시네이션, 편향적 답변을 해결하려는 노력이 보입니다.
chat_response = client.chat(
model="mistral-tiny",
messages=ChatMessage(role="user", content="What is the best French cheese?"),
safe_mode=True
)
# safe_mode를 True로 주면, 다음과 같은 프롬프트가 붙는다고 합니다.
# Always assist with care, respect, and truth. Respond with utmost utility yet securely. Avoid harmful, unethical, prejudiced, or negative content. Ensure replies promote fairness and positivity.
성능도 잡으면서 추론도 빠르게, 두 마리 토끼를 다 잡으면서 LLM을 실제 어플리케이션단에서 더 쉽게 사용할 수 있게 된 것 같습니다. 하지만 아직은 OpenAI, Google같은 빅테크 기업에서 API형태로 제공하는 LLM 대비 경쟁력이 얼만큼 인지에 대한 의문이 따라 붙지만 LLM 생태계의 좋은 활력을 주는 것 같습니다. (Mistral AI도 스타트업이고, Business Model을 바꿀 수는 있겠지만…)
Reference
- https://mistral.ai/news/mixtral-of-experts/
- https://huggingface.co/blog/moe
- https://www.aitimes.com/news/articleView.html?idxno=155775






