
[분석AI서비스팀 이현정]
관리해야 할 AI모델과 데이터가 많아지고 그 용량이 커지면서 필자가 관심을 가지게 된 Ceph에 대해 간략히 소개해 보고자 합니다.
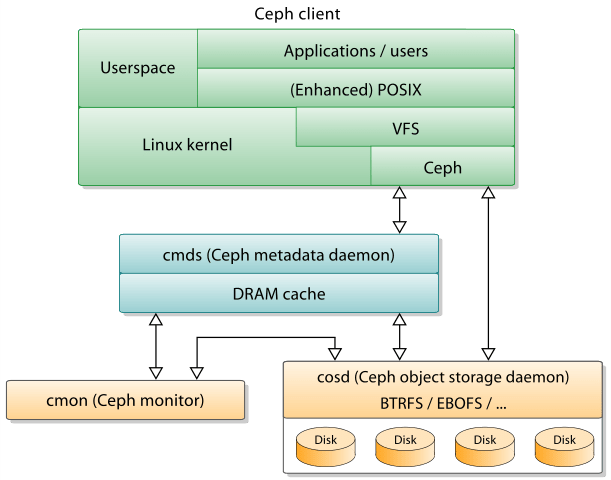
Ceph 이란?
Ceph은 단일 분산 컴퓨터 클러스터에 오브젝트 스토리지를 구현하는 오픈 소스 소프트웨어 정의 스토리지 플랫폼으로 대규모 데이터를 효과적으로 저장하고 관리하기 위한 목적으로 개발되었습니다
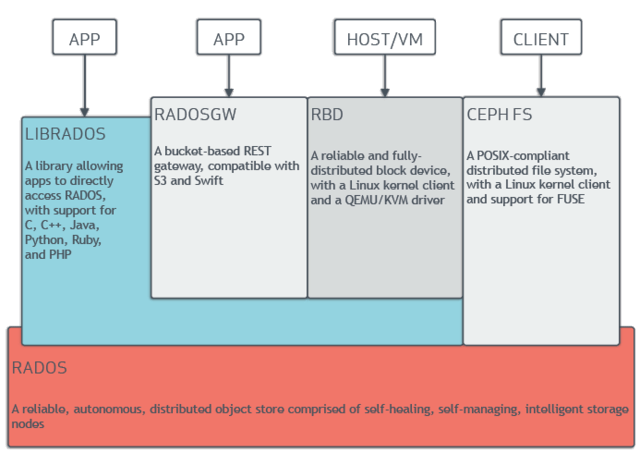
분산 클러스터 위에 Object Storage를 구현하여 Object, Block, File Level의 스토리지 인터페이스를 제공하며, 클러스터를 형성하는 여러 노드에 데이터를 분산하여 안정성과 가용성을 확보해 줍니다.
Ceph의 내부는 Object Storage로 설계되어 있으며, Ceph의 Object-based software architecture는 RADOS (Reliable Autonomic Distributed Object Store)로 Ceph의 interface를 통해 들어온 데이터(Object, Block, File)는 모드 RADOS를 통해서 RADOS Object 포맷으로 변환되어 Ceph에 저장되고 관리 됩니다.
Ceph의 장점
분산 아키텍처를 기반으로 하고 있어, 여러 노드에 데이터를 분산하여 저장함으로써 확장성이 용이하고 높은 가용성을 제공합니다.
객체 스토리지, 블록 스토리지, 파일 시스템을 지원하여 다양한 용도에 활용할 수 있습니다.
데이터의 손상이나 노드의 장애에 대비하여 자동으로 데이터를 복구하고 클러스터를 유지하는 기능을 제공합니다.
Ceph는 오픈 소스로 개발되어 있어 라이선스 문제 없이 자유롭게 사용할 수 있습니다.
상대적으로 저렴한 하드웨어에서도 운영이 가능하며, 여러 가용성 옵션을 통해 비용을 절약할 수 있습니다.
Ceph의 단점
다양한 구성 및 설정 옵션이 있어 초기 설정이나 유지 보수가 다소 복잡합니다.
Ceph를 제대로 구성하고 사용하기 위해서는 일정 수준의 전문 지식이 필요할 수 있어, 러닝 커브가 높고, 설정에 따라 (같은 성능을 내더라도) 높은 컴퓨팅 비용(하드웨어, 네트웍)이 발생할 수 있습니다.
특정 규모 이상으로 커지면 일부 Ceph 컴포넌트가 불안정해진다는 기술 사례가 보고 되고 있습니다.
작은 규모의 클러스터에서는 Ceph의 이점보다 운영의 비용이 커집니다.
결론
Ceph은 오픈소스라는 강점과, 확장의 용이함과 데이터의 안전한 관리로 대규모 데이터 스토리지, 분산 저장 시스템에서는 거의 필수로 사용되고 있는 추세로 보입니다.
다만 단점에서 거론되고 있는 러닝 커브가 높은 부분과, 작은 규모에서는 Ceph을 사용하여 얻을 수 있는 이점보다 운영 비용이 높아진다는 부분은 도입 전 신중한 검토가 필요한 부분일 것 같습니다. 여러 방식의 검색에도 Ceph을 구축하기에 작은 규모 또는 Ceph을 구성하는 최적의 규모에 대한 결과는 얻을 수 없었기 때문에 구축 전 사용가능한 컴퓨팅 리소스를 충분히 검토하고 구축 후 어떤 효과가 있을지 명확히 정의한 후, 구축 여부를 결정해야 할 것 같습니다.
https://ceph.io/en/
https://en.wikipedia.org/wiki/Ceph_(software)
https://ceph.io/en/news/blog/2022/scaletesting-with-pawsey/
https://ceph.io/en/news/blog/2022/mgr-ttlcache/






