
[선행AI기술팀 이지현]
Model Merge (모델 병합)은 여러 개의 Large Language Models (LLMs; 대형 언어 모델)을 추가 교육이나 미세 조정 없이 하나의 강력한 모델로 결합하는 방법론입니다. 특정 태스크에 최적화된 각 LLMs을 병합함으로써 여러 모델의 전문지식을 가져오고 성능도 향상시킬 수 있습니다. 말하자면 집단 지성을 활용하는 셈이지요. 여러 분야의 전문 지식을 필요로 하는 복잡한 태스크를 수행할 때 특히 유용합니다. 본 글에서는 이러한 모델 병합의 다양한 방법론들을 소개하고자 합니다. 간단하게 모델 병합을 실행할 수 있는 방법 중 하나는 mergekit 라이브러리를 활용하는 것입니다. 여러 방법론들을 yaml 파일 수정만으로 쉽게 적용할 수 있습니다.

Linear
첫째, Linear 방법론은 간단하게 여러 모델의 가중치를 평균 내는 방식으로, mergekit에서는 아래와 같이 가중치 (weight) 파라미터를 사용하여 사용자가 최종 병합 모델에 대한 각 모델의 기여도를 제어할 수 있습니다.
models:
- model: psmathur/orca_mini_v3_13b
parameters:
weight: 1.0. # relative (or absolute if normalize=False) weighting of a given tensor
- model: WizardLM/WizardLM-13B-V1.2
parameters:
weight: 0.3
- model: garage-bAInd/Platypus2-13B
parameters:
weight: 0.5
merge_method: linear
dtype: float16
SLERP
SLERP (Spherical Linear Interpolation; 구형 선형 보간) 방법론은 기존의 가중치 평균 방식의 한계를 해결합니다. SLERP는 모델의 매개변수를 초구체의 점으로 처리하여 모델 사이의 최단 경로를 계산하여 일정한 변화율을 보장합니다. SLERP는 공간의 곡률을 따라가며 고차원 공간에서 기하학적 특성을 유지하며 보다 부드러운 매개변수 전환을 가능하게 합니다. 방법론은 다음과 같습니다. 각 모델의 벡터를 정규화한 다음 내적을 통해 두 벡터의 각도를 계산합니다. 그리고 interpolation factor (보간 계수) t와 각도를 기반으로 스케일링 인자를 계산하여 최종 병합된 모델에서 각 모델의 영향력을 제어하는 방식입니다.
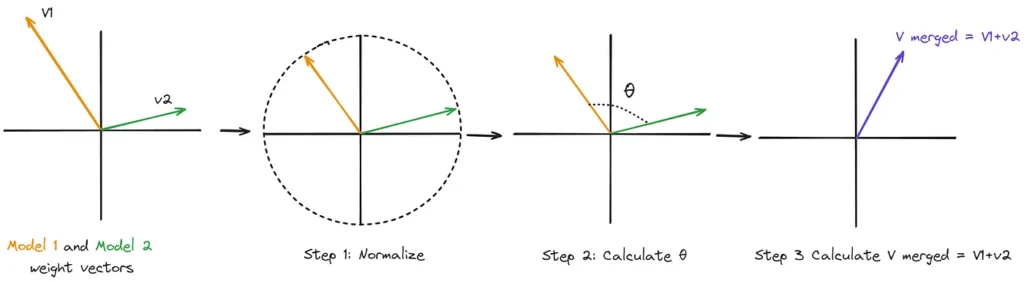
mergekit에서 이를 적용할 때에는 주요 파라미터로 interpolation factor (보간 계수) t와 사용할 모델의 레이어 조각을 정의하는 slices가 있습니다. t=0일 때는 base_model을 반환하고, t=1일 때는 다른 모델을 반환합니다. 여기서 value: [1.0, 0.5, 0.0]과 같은 파라미터는 무슨 뜻일까요? 이는 BlockMerge Gradient 보간 기법이라고 불립니다. [1.0, 0.5, 0.0]의 경우, model2 값의 100%로 텐서를 혼합하는 것에서 시작하여 점차적으로 두 모델 간의 50-50 혼합으로 전환하고, 마지막으로 model1의 값만 사용하도록 설정하는 것입니다.
slices:
- sources:
- model: psmathur/orca_mini_v3_13b
layer_range: [0, 40]
- model: garage-bAInd/Platypus2-13B
layer_range: [0, 40]
merge_method: slerp
base_model: psmathur/orca_mini_v3_13b
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0]
- filter: mlp
value: [1, 0.5, 0]
- value: 0.5 # fallback for rest of tensors
dtype: float16
Task Arithmetric
Task Arithmetic 방법론은 파인 튜닝된 동일한 모델의 가중치에서 사전학습 모델의 가중치를 빼는 방식으로 생성된 ‘Task Vector (작업 벡터)’를 활용합니다. Editing Models With Task Arithmetic 논문에서는 Task Vector를 이용한 여러 연산 과정을 통해 모델을 수정하는 방법을 제시했습니다. 아래 그림에서와 같이, (b) Forgetting via negation: 원하는 Task Vector를 음수화하거나 (e.g. 독성 데이터에 학습한 LM vector를 음수화하여 독성 콘텐츠의 영향력을 줄임) (c) Learning via addition: 여러 Task Vector를 더해 사전 학습 모델의 성능을 향상시키거나 (e.g. 여러 모델의 task vectors를 더해서 이미지 분류 정확도를 높임) (d) Task analogies: 서로 다른 데이터 소스에서 지도 학습이나 비지도 학습과 같은 analogy 관계를 형성하는 경우 벡터 조합을 통해 지도 학습 타겟 태스크에서의 성능을 개선할 수 있습니다 (e.g. 감성 분류 태스크에서 다른 감성 분석 데이터셋에서의 task vector와 두 도메인의 레이블 없는 데이터를 이용해 생성된 task vector를 결합함). 이 방법론은 공통적인 ancestor (조상)에서 파인 튜닝된 모델에 특히 효과적입니다.

base_model: teknium/OpenHermes-2.5-Mistral-7B
dtype: bfloat16
merge_method: task_arithmetic
slices:
- sources:
- layer_range: [0, 32]
model: teknium/OpenHermes-2.5-Mistral-7B
- layer_range: [0, 32]
model: simonveitner/Math-OpenHermes-2.5-Mistral-7B
parameters:
weight: 0.25
- layer_range: [0, 32]
model: openaccess-ai-collective/dpopenhermes-alpha-v0
parameters:
weight: 0.25
- layer_range: [0, 32]
model: mlabonne/NeuralHermes-2.5-Mistral-7B
parameters:
weight: 0.25
- layer_range: [0, 32]
model: mlabonne/NeuralHermes-2.5-Mistral-7B-laser
parameters:
weight: 0.25
TIES
TIES 방법론은 Trim, Elect Sign, Merge의 3단계를 통해 파라미터 간섭, 중복 문제를 해결하고자 합니다. 2개 이상의 모델을 동시에 병합할 수 있기 때문에 많이 활용되는 방식 중 하나입니다. TIES-Merging은 위에서 설명한 Task Arithmetic 방법에 기반합니다. (1) Trim: 먼저, 중복된 매개변수를 식별하고 가장 영향력 있는 상위 k%의 매개변수 값만 남깁니다. (2) Elect Sign: 다음으로, 영향력 있는 매개변수 값 간의 충돌을 방지하기 위해 모든 모델에서 업데이트 뱡향이 가장 큰 쪽을 나타내는 unified sign vector (통합 기호 벡터)를 구합니다. (3) Disjoint Merge: 마지막으로 통합 기호 벡터에 맞춰 정렬된 매개변수 값의 평균을 구합니다.

아래 mergekit 예시에서 density는 base_model과의 차이에서 유지할 가중치의 비율을 조정하는 값입니다.
models:
- model: psmathur/orca_mini_v3_13b
parameters:
density: [1, 0.7, 0.1] # density gradient
weight: 1.0
- model: garage-bAInd/Platypus2-13B
parameters:
density: 0.5
weight: [0, 0.3, 0.7, 1] # weight gradient
- model: WizardLM/WizardMath-13B-V1.0
parameters:
density: 0.33
weight:
- filter: mlp
value: 0.5
- value: 0
merge_method: ties
base_model: TheBloke/Llama-2-13B-fp16
parameters:
normalize: true
int8_mask: true
dtype: float16
이렇게 Linear, SLERP, Task Arithmetic, TIES 방법론을 간단히 설명해 드렸는데요. 이외에도 다양한 모델 병합 기술이 있으며, 관련 연구가 계속해서 쏟아져 나오고 있습니다. 이러한 모델 병합 기술은 성능을 향상시킬 뿐 아니라 개발 시간과 비용을 절약하는 등 효율적인 자원 활용을 가능하게 합니다. 여러분도 모델 병합을 통해 여러 모델의 장점만을 수용한 나만의 모델을 만들어보는 것 어떨까요?






