일반적으로 이미지에서 사용되는 convolution은 3D operation입니다. (KxKxC; K=커널크기, C=채널수) 이것을 KxKx1의 2D operation 복수개로 분할하여 적용한 후, 채널 방향으로 1x1xC 크기로 convolution을 적용하는 depthwise separable convolution은 파라미터 수를 엄청나게 감소시킵니다. 이 방식으로 만들어진 네트워크 구조가 Google MobileNet입니다.
Google Inception은 입력 텐서에 대해 3×3, 5×5, 7×7 등 서로 다른 크기의 커널을 적용한 후 concatenation하는 방법의 기본 모듈을 가지고 있습니다. 이 방식의 장점 또한 같은 성능 기준 파라미터수의 감소로 나타납니다.
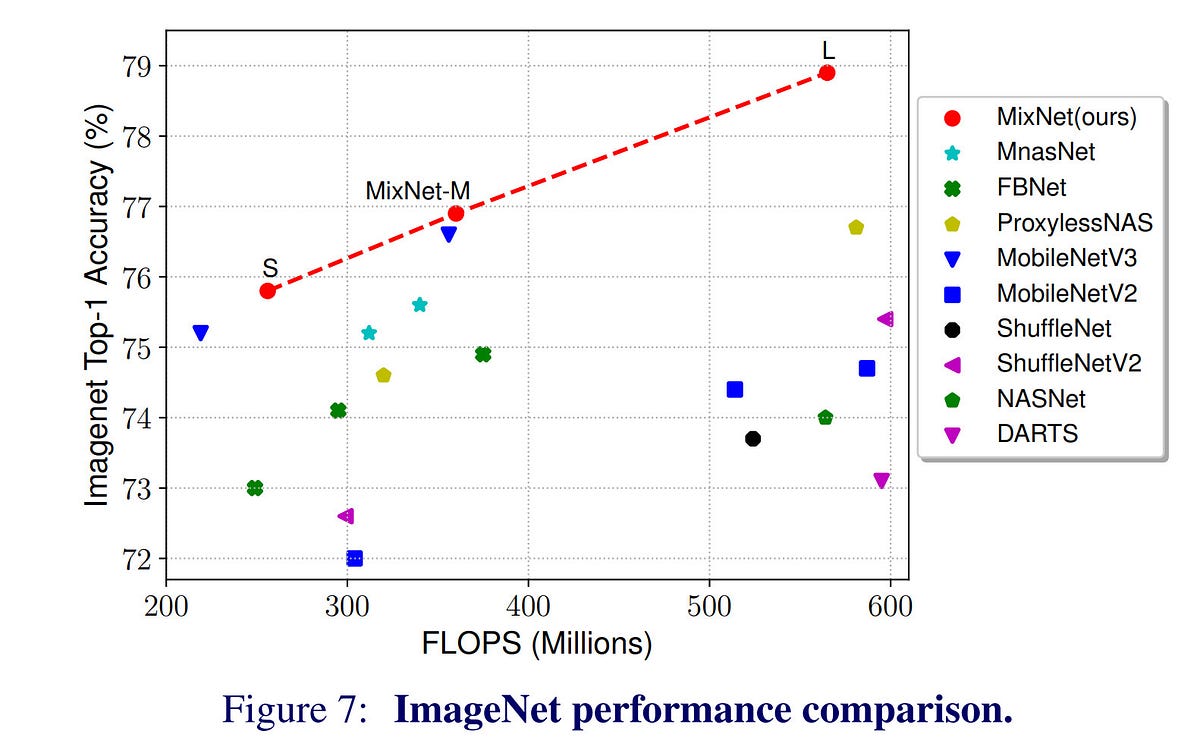
아래 링크에 공유한 Google MixNet은 위 두 가지 특성을 하나로 합친 구조를 가지고 있습니다. 즉, depthwise separable convolution을 쓰면서도 다양한 크기의 커널을 적용하도록 한 것입니다. 실험 결과는 놀랍습니다. ImageNet-1K task에서 ResNet-153에 비해 1/12의 파라미터수, 1/28의 연산수만으로 같은 성능을 보여줍니다.
다만, 그렇다고 해서 MixNet이 ResNet에 비해 28배 빠른 것은 아닙니다. 일반적으로 GPU 연산이 가장 효율적이려면 “대량”의 “동일”한 연산이 반복되어야 하나 depthwise convolution은 쪼개서 각각 convolution을 적용하기 때문에 standard convolution보다 복잡하고, 결국 연산수 감소만큼의 성능차이를 보이지 않습니다. Inception 또한 마찬가지입니다. 여러 커널로 나누어 각각 연산을 하기 때문에 더 복잡하며, inception 구조가 아닌 방식에 비해서 느립니다. 또한, “분기”가 발생하기 때문에 단순 구현시 요구 메모리 또한 증가합니다.
참고로 residual network, 즉 skip connection의 경우는 파라미터수를 1도 증가시키지 않으며 단순히 MFLOPS로 계산한 연산량도 거의 동일하지만 실제로 측정해보면 수행시간에 꽤 영향을 줍니다. (역시 “분기”가 발생하기 때문으로 이해하고 있습니다) 필터링 전후를 각각 저장하기 위한 요구 메모리도 증가하구요.
MixNet이 나쁘다는 뜻은 절대 아니며, 저도 추후 이걸 가져다 쓸 겁니다만^^, 파라미터수와 연산수만으로는 네트워크의 복잡도를 온전히 표현할 수 없다는 생각입니다. 실제로 MixNet-S는 MobileNet-V3에 비해 30% 이상 적은 파라미터수를 가지지만 구글 픽셀에서 수행한 inference test에서 MobileNet-V3가 2배 가량 더 빠르게 나왔습니다 ^^;; “구조적 단순성”, “구현 친화도”가 실제로는 많은 영향을 준다는 하나의 예라고 생각합니다. 참고로, 하드웨어 구현시에는 훨씬 더 티가 납니다. 3×3과 5×5, 7×7은 단순히 파라미터 수의 차이를 훨씬 상회하는 implementation cost의 차이가 존재합니다.